Clear Sky Science · it
Un modello di degradazione accoppiata alla fusione guidato da VLM per la fusione degradazione-consapevole di immagini infrarosse e visibili
Visione notturna più nitida per un mondo rumoroso
Le fotocamere moderne riescono a vedere al buio, rilevare il calore e osservare la strada per noi, ma le loro immagini sono spesso ben lontane dalla perfezione. I lampioni abbagliano, le ombre inghiottono i dettagli e i sensori introducono rumore puntinato. Questo studio presenta un nuovo modo di unire video a colori ordinari con immagini infrarosse termiche in modo che la vista finale sia più chiara e affidabile, anche quando entrambi gli ingressi sono fortemente degradati. Il metodo potrebbe rendere più affidabili le auto autonome, i sistemi di sorveglianza e altre telecamere intelligenti nelle condizioni in cui ne abbiamo più bisogno: di notte, in condizioni meteo avverse e in scene reali complesse.
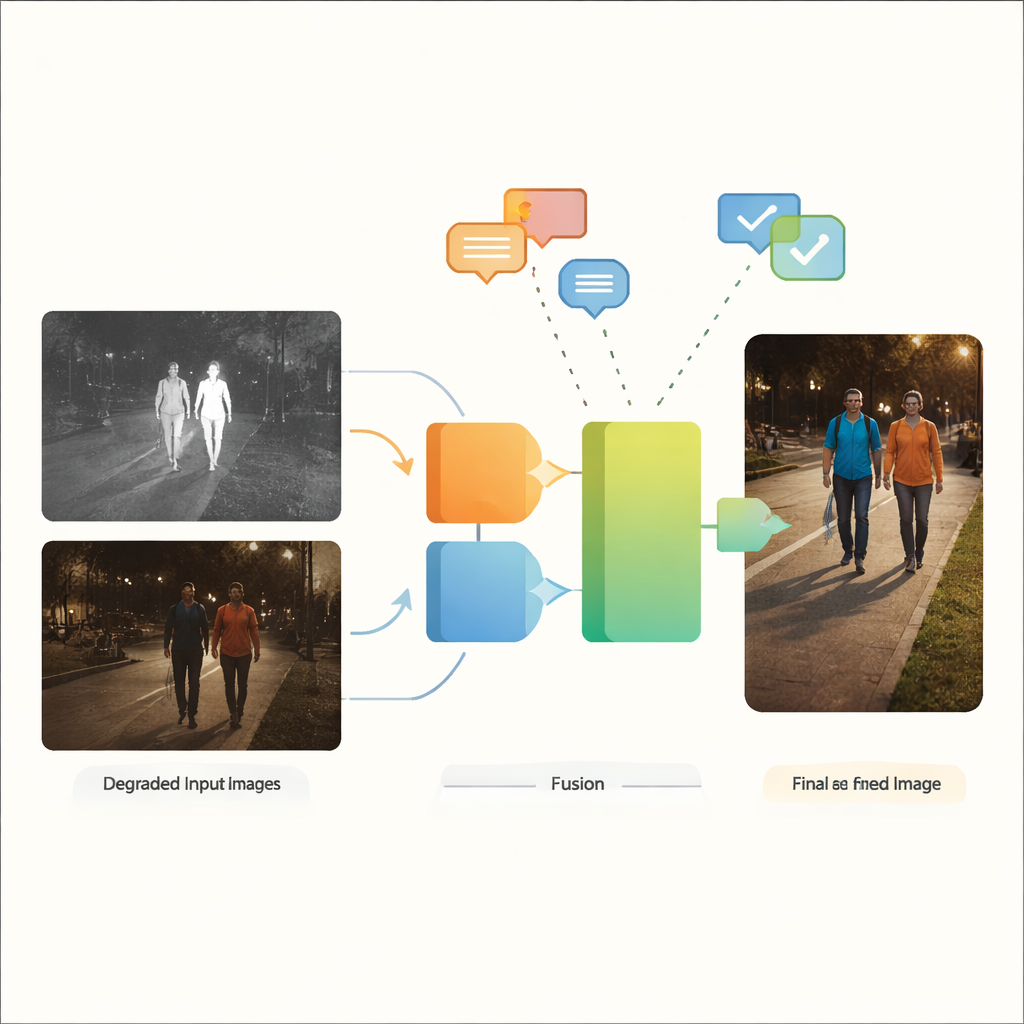
Perché due occhi valgono meglio di uno
Le fotocamere in luce visibile catturano i ricchi colori e le trame a cui gli esseri umani sono abituati, ma faticano in condizioni di scarsa illuminazione, abbagliamento e ombre profonde. Le camere a infrarossi, al contrario, percepiscono il calore e riescono facilmente a distinguere oggetti caldi come persone o veicoli al buio, sebbene le loro immagini spesso appaiano piatte e prive di dettagli fini. La fusione di immagini infrarosse e visibili mira a combinare il meglio di entrambi: i contorni netti dei bersagli caldi dall’infrarosso con il contesto e il colore della luce visibile. Tradizionalmente, però, la maggior parte dei metodi di fusione assume che entrambe le immagini in ingresso siano già pulite e di alta qualità — ipotesi poco realistica per strade, città e siti industriali dove sfocatura, rumore, illuminazione insufficiente e sovraesposizione sono la norma piuttosto che l’eccezione.
Quando il preprocessing non basta
I sistemi esistenti solitamente affrontano le immagini degradate in due fasi separate. Prima, strumenti di miglioramento separati schiariscono le scene scure, riducono il rumore o correggono il contrasto. Solo dopo una rete di fusione unisce le immagini migliorate. Questo approccio in due stadi presenta diversi limiti. Costringe gli ingegneri a scegliere e calibrare strumenti di miglioramento diversi per ogni tipo di difetto e per ogni sensore, rendendo i flussi di lavoro fragili e complessi. Soprattutto, qualsiasi informazione persa o distorta durante la pulizia autonoma non può essere recuperata successivamente dalla fase di fusione. Alcune ricerche recenti hanno introdotto reti speciali tarate su un tipo specifico di degradazione o hanno usato modelli guidati dal linguaggio per gestire una singola modalità deteriorata alla volta. Tuttavia, quando sia le immagini infrarosse sia quelle visibili sono degradate — e spesso in modi diversi — queste strategie dipendono ancora molto dal preprocessing manuale e incontrano difficoltà con condizioni miste e realistiche.
Una rete di fusione che comprende la degradazione
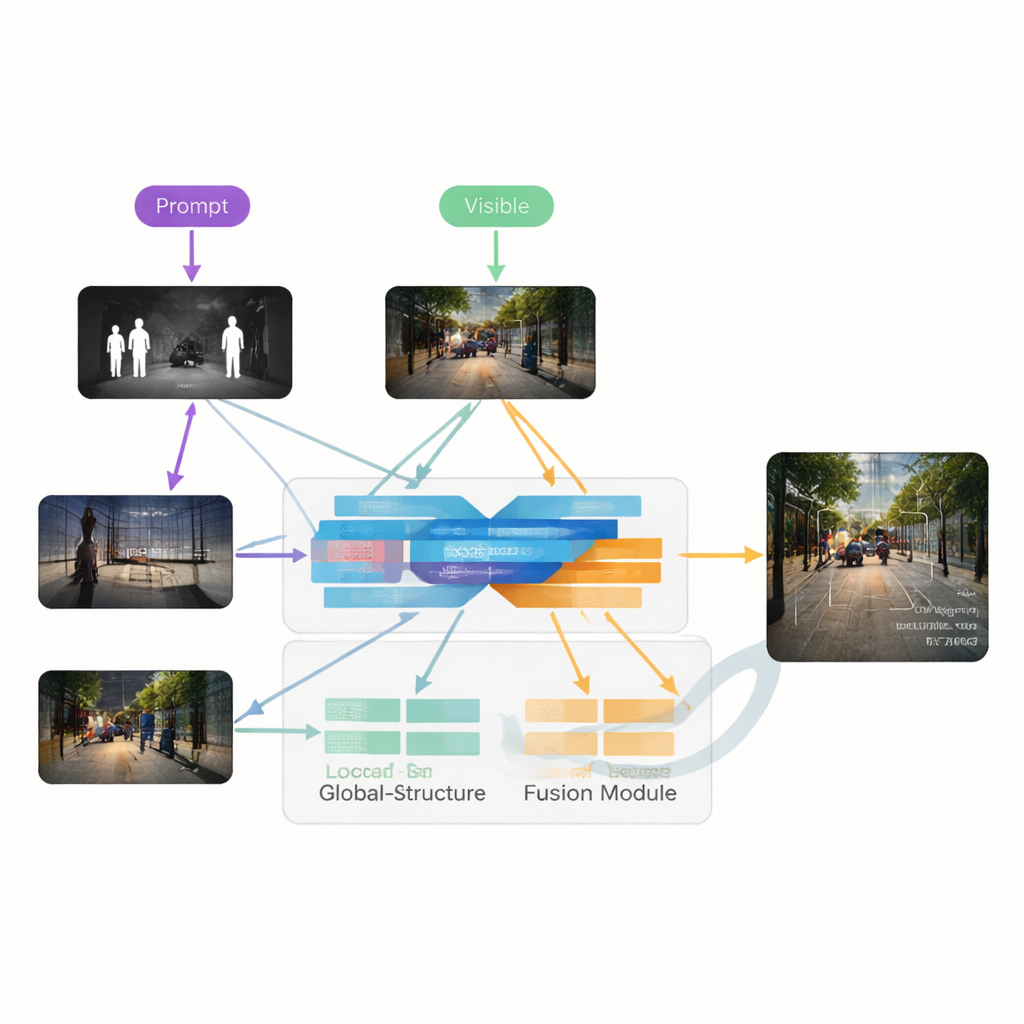
Gli autori propongono VGDCFusion, un nuovo framework di deep learning che integra la gestione della degradazione direttamente nel processo di fusione. L’idea chiave è permettere alla rete di sapere, tramite parole, quale tipo di problemi aspettarsi e usare tale conoscenza a ogni passaggio dell’estrazione e della fusione delle caratteristiche. Brevi prompt testuali descrivono il compito (fusione infrarosso–visibile) e i problemi specifici presenti, come scarsa illuminazione, sovraesposizione, basso contrasto o rumore. Un potente modello visione–linguaggio — simile nello spirito a sistemi come CLIP — trasforma questi prompt in descrittori numerici compatti. Questi descrittori guidano due blocchi principali: lo Specific-Prompt Degradation-Coupled Extractor (SPDCE), che opera separatamente su ciascuna modalità, e il Joint-Prompt Degradation-Coupled Fusion (JPDCF), che fonde le informazioni tra le modalità continuando a tenere conto del tipo di degradazione residua.
Come funziona il processo di fusione guidata
All’interno di ciascun modulo SPDCE, la guida derivata dal prompt indirizza la rete verso le caratteristiche importanti e lontano dagli artefatti. Strati convoluzionali multi-scala osservano piccoli intorni per preservare bordi e texture, mentre strati Transformer catturano strutture e contesto su scala maggiore. Insieme imparano a mettere in risalto, per esempio, firme termiche importanti in un frame infrarosso rumoroso o segnali stradali deboli in un’immagine visibile sottoesposta, sopprimendo al contempo il rumore del sensore e i difetti di illuminazione. In parallelo, i moduli JPDCF prendono le caratteristiche pulite da entrambi i rami e le combinano, sempre sotto la guida del prompt. Utilizzano attenzione spaziale e per canale per enfatizzare le regioni informative, filtrare le degradazioni residue e mettere insieme indizi complementari — come allineare un contorno luminoso infrarosso di un pedone con il colore e la struttura di sfondo della camera visibile — prima di ricostruire un’immagine di uscita fusa a tre canali.
Mettere il metodo alla prova
Per dimostrarne l’utilità, il team ha valutato VGDCFusion su diversi dataset pubblici che includono immagini visibili in condizioni di scarsa illuminazione e sovraesposte, oltre a immagini infrarosse rumorose o a basso contrasto. Hanno confrontato il loro metodo con una gamma di tecniche di fusione all’avanguardia che spaziano da autoencoder, reti convoluzionali, reti antagoniste generative (GAN) e Transformer. Utilizzando misure standard di qualità dell’immagine, VGDCFusion ha prodotto sistematicamente immagini fuse con bordi più nitidi, contrasto migliore e colori più naturali, anche quando i metodi concorrenti beneficiavano del vantaggio di un preprocessing accuratamente tarato. Il nuovo approccio ha migliorato le metriche chiave di circa il 15% in media negli scenari fortemente degradati. Quando le immagini fuse sono state fornite a un popolare sistema di rilevamento oggetti, hanno anche portato a una maggiore accuratezza rispetto all’uso di sole immagini infrarosse o visibili, o rispetto ad altre reti di fusione.
Visione più chiara per sistemi più sicuri
In termini semplici, questo lavoro mostra che dire a una rete di fusione quali tipi di problemi visivi aspettarsi — e permetterle di correggere e fondere in un unico passo strettamente integrato — può produrre immagini più pulite e più informative rispetto al trattare miglioramento e fusione come compiti separati. Accoppiando la modellazione della degradazione con il processo di fusione e usando segnali guidati dal linguaggio a ogni livello, VGDCFusion può adattarsi a forme variegate e miste di degradazione dell’immagine senza un continuo riaggiustamento manuale. Questo tipo di fusione intelligente e consapevole della degradazione potrebbe aiutare i futuri sistemi visivi, dalle auto a guida autonoma alle telecamere di sicurezza, a vedere in modo più affidabile nelle condizioni disordinate e imperfette del mondo reale.
Citazione: Zhao, J., Zhang, T. & Cui, G. A VLM guided network coupling degradation modeling for degradation aware infrared and visible image fusion. Sci Rep 16, 8249 (2026). https://doi.org/10.1038/s41598-026-38181-8
Parole chiave: fusione infrarosso e visibile, imaging in condizioni di scarsa illuminazione, modelli visione-linguaggio, degradazione dell'immagine, percezione per guida autonoma