Clear Sky Science · it
Un framework ibrido a ensemble impilato per il rilevamento multilabel delle emozioni nei testi
Perché interpretare le emozioni nei testi è importante
Ogni giorno le persone riversano i propri sentimenti in post sui social, recensioni e messaggi. Nella mole di parole si nascondono segnali precoci su difficoltà di salute mentale, l’aumento di discorsi d’odio e le reazioni pubbliche a crisi e disastri. Ma i computer di solito rilevano solo “positivo” o “negativo”, perdendo la mescolanza di emozioni che le persone esprimono spesso contemporaneamente. Questo articolo esplora un nuovo modo per insegnare alle macchine a riconoscere più emozioni in un singolo testo e a farlo non solo in inglese ma anche in lingue che raramente beneficiano delle più avanzate tecnologie di intelligenza artificiale.
Oltre il semplice positivo o negativo
Gli strumenti tradizionali di analisi del sentiment sono come termometri grossolani: possono dire se l’umore è buono o cattivo, ma non distinguere se qualcuno prova rabbia, paura, speranza o sollievo contemporaneamente. Gli autori sostengono che comprendere questa tavolozza emotiva più ricca sia cruciale per applicazioni come il soccorso in caso di disastri, il supporto terapeutico e l’assistenza clienti. Un messaggio che mescola paura e urgenza, per esempio, può richiedere attenzione immediata, mentre uno che combina tristezza e ottimismo potrebbe richiedere un tipo diverso di intervento. Catturare più emozioni in parallelo — noto come rilevamento delle emozioni multilabel — è quindi un passo chiave verso sistemi più sensibili e consapevoli dell’umano.
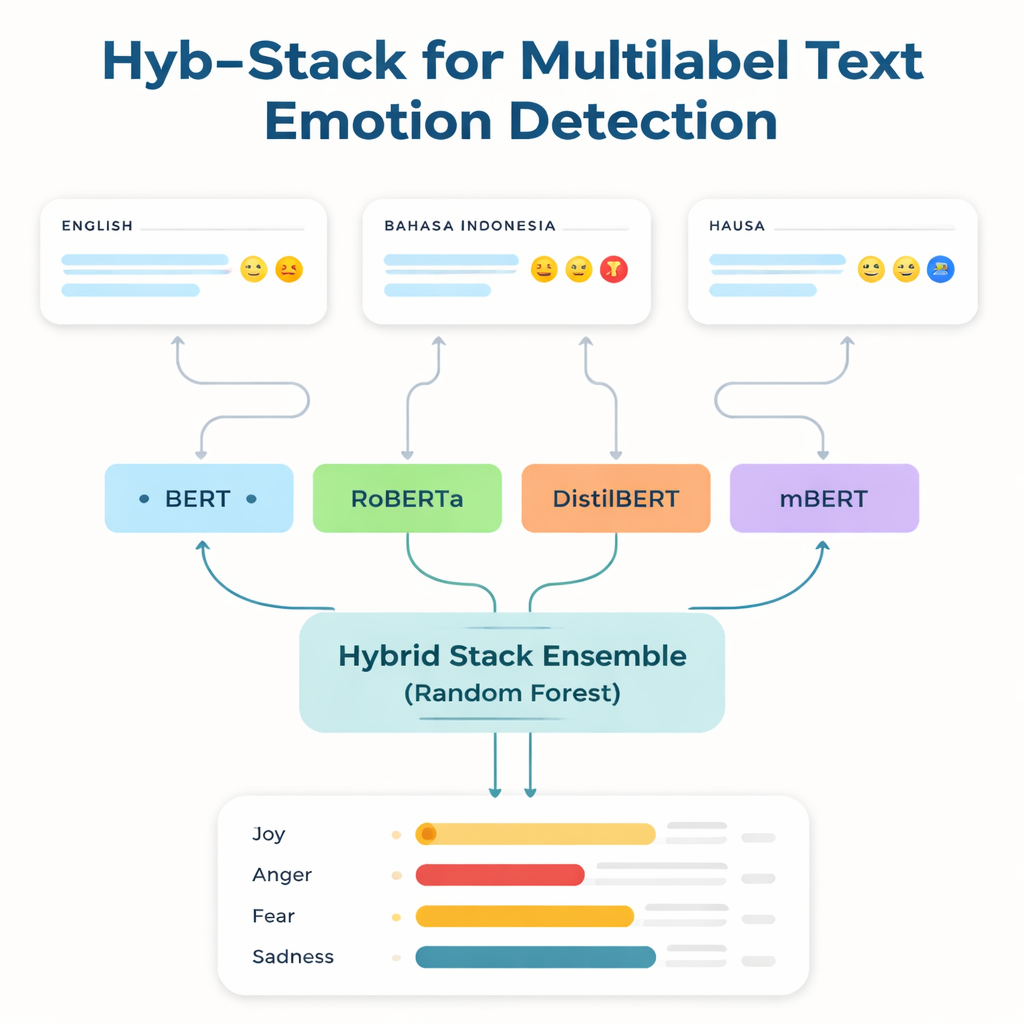
Dare voce alle lingue trascurate
Le tecnologie linguistiche più potenti sono addestrate e ottimizzate sull’inglese e su poche altre lingue ampiamente usate. I parlanti di lingue a bassa risorsa — con pochi dati etichettati e pochi strumenti digitali — vengono spesso lasciati indietro. Per colmare questo divario, i ricercatori si concentrano su tre dataset: un noto benchmark inglese per le emozioni; una raccolta in Bahasa Indonesia focalizzata su linguaggio offensivo e d’odio; e un nuovo corpus di tweet in Hausa creato dagli autori, chiamato HaEmoC_V1. Il dataset in Hausa include oltre dodicimila tweet accuratamente puliti e annotati, ciascuno etichettato con una o più delle undici emozioni come rabbia, gioia, fiducia, pessimismo e anticipazione. Revisori esperti hanno verificato le etichette e i punteggi di accordo indicano che le annotazioni sono coerenti e affidabili.
Combinare più lettori intelligenti in uno
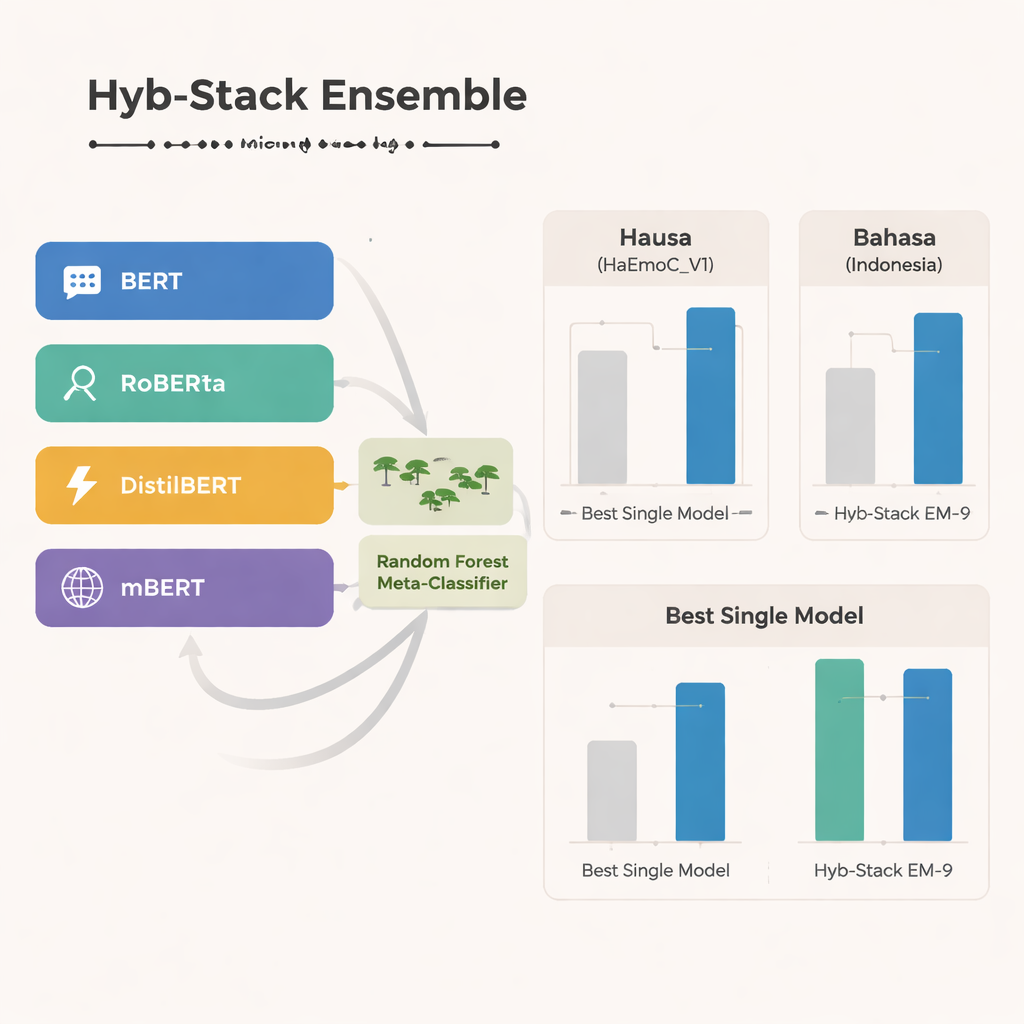
Al centro dello studio c’è Hyb-Stack, un ensemble ibrido impilato — una sorta di “comitato di esperti” per il linguaggio. Quattro modelli avanzati basati su transformer (BERT, RoBERTa, DistilBERT e il multilingue mBERT) sono ciascuno fine-tuned per leggere segnali emotivi nel testo. Piuttosto che affidarsi a un solo modello, Hyb-Stack permette a tutti di fare previsioni e poi alimenta i loro punteggi interni in un decisore di secondo livello: un classificatore Random Forest. Questo meta-classificatore impara a pesare i diversi punti di forza di ciascun modello, catturando pattern complessi nelle co-occorrenze emotive. Il team testa anche metodi di ensemble più semplici che mediamente aggregano le previsioni, con o senza pesatura basata sulle performance pregresse, per verificare se l’impilamento più elaborato porta davvero vantaggi.
Quanto bene funziona l’approccio ibrido
In tutte e tre le lingue, il multilingue mBERT si distingue come il singolo modello più forte, performando particolarmente bene sul nuovo dataset in Hausa e sul set di discorsi d’odio in Bahasa Indonesia. Tuttavia l’ensemble ibrido va oltre. Una particolare combinazione — chiamata EM-9, che fonde BERT, DistilBERT e mBERT all’interno del framework Hyb-Stack — fornisce costantemente i risultati migliori. Raggiunge punteggi F1 più elevati, una misura comune di accuratezza, rispetto a qualsiasi singolo modello o ad approcci di semplice media, con i guadagni maggiori nei dataset a bassa risorsa di Hausa e Bahasa Indonesia. Analisi dettagliate degli errori mostrano che gli sbagli rimanenti si verificano di solito tra emozioni strettamente correlate, come gioia versus sorpresa o tristezza versus paura, riflettendo la naturale sfumatura dei sentimenti umani più che veri e propri fallimenti del sistema.
Cosa significa per i sistemi nel mondo reale
Per il lettore generale, la conclusione principale è che combinare più modelli di IA in modo intelligente può aiutare i computer a leggere le emozioni nei testi con maggiore precisione, specialmente in lingue a lungo trascurate dalla tecnologia. Costruendo un corpus di emozioni in Hausa di alta qualità e dimostrando che gli ensemble ibridi sovraperformano modelli singoli e schemi di voto semplici, gli autori mostrano un percorso pratico verso strumenti più inclusivi e attenti alle emozioni. Lavori futuri estenderanno l’approccio a sfumature emotive più sottili, linguaggio code-mixed, emoji e altre lingue sottorappresentate, con l’obiettivo di creare sistemi in grado di percepire non solo se le persone sono felici o tristi, ma come e perché si sentono in quel modo — indipendentemente dalla lingua che parlano.
Citazione: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
Parole chiave: rilevamento delle emozioni, NLP multilingue, ensemble learning, modelli transformer, lingue a bassa risorsa