Clear Sky Science · it
Calcolo efficiente e progettazione di un'architettura di moltiplicatore vedico a doppia precisione ad alta velocità
Perché conta accelerare i calcoli numerici
Ogni volta che guardi un video in streaming, usi la navigazione sul telefono o lasci che un sistema di intelligenza artificiale analizzi immagini mediche, hardware specializzato sta silenziosamente eseguendo miliardi di piccoli calcoli al secondo. Una larga parte di queste operazioni sono moltiplicazioni su numeri in virgola mobile, il modo standard con cui i computer rappresentano valori reali come 3,14159. Questo articolo esplora un modo più intelligente di costruire uno di quei componenti fondamentali: un moltiplicatore ad alta velocità ed efficiente dal punto di vista energetico che sfrutta idee della matematica vedica antica per potenziare l'hardware digitale moderno.
Dai trucchi matematici antichi ai chip moderni
L'aritmetica in virgola mobile è alla base dell'elaborazione digitale del segnale, dell'elaborazione delle immagini, delle comunicazioni e degli acceleratori per il deep learning. I moltiplicatori standard devono gestire parole binarie ampie—64 bit per la doppia precisione—e farlo rapidamente senza sprecare area del chip o energia. Gli approcci tradizionali, come Booth, Karatsuba e i moltiplicatori a matrice, bilanciano compromessi tra velocità, dimensione hardware e complessità progettuale. La matematica vedica, un sistema di 16 regole aritmetiche classiche sviluppate in India, include un metodo di moltiplicazione chiamato Urdhva Tiryakbhyam, o "verticale e incrociato". Esso genera prodotti parziali in modo altamente parallelo, il che può ridurre il numero di passaggi intermedi e l'hardware necessario. I ricercatori hanno recentemente adattato queste idee ai circuiti digitali, ma i progetti esistenti presentano ancora sovraccosti quando vengono impiegati per operazioni in virgola mobile a doppia precisione.
Cosa c'è di speciale in questo nuovo moltiplicatore
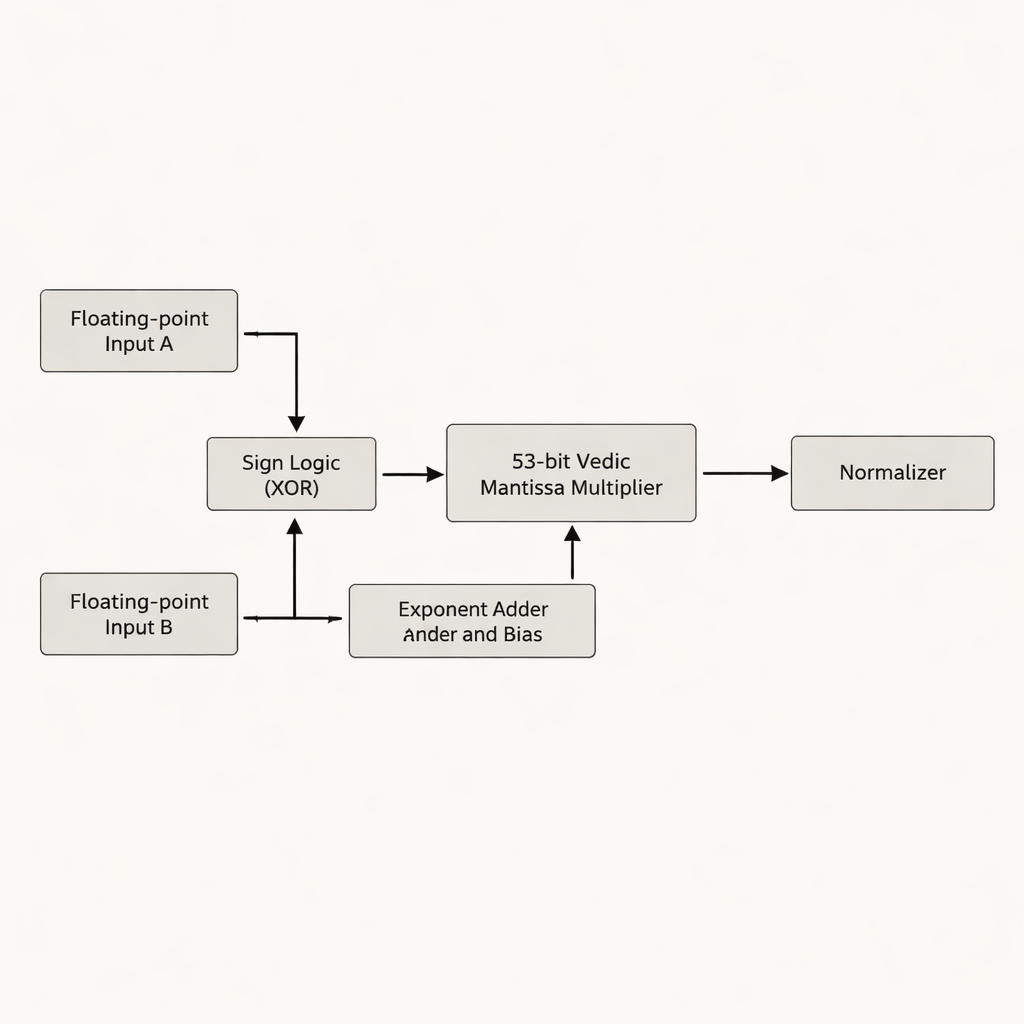
Gli autori propongono un moltiplicatore in virgola mobile a doppia precisione che si concentra sulla mantissa—la parte di un numero in virgola mobile che contiene la maggior parte delle cifre significative. Invece di riempire (padding) la mantissa a 52 bit fino a 54 bit, come fanno molti progetti precedenti, lavorano con la vera mantissa efficace a 53 bit, evitando bit "vuoti" che consumano spazio di memorizzazione e wiring aggiuntivi sul chip. Il cuore del progetto è un moltiplicatore vedico a 53 bit basato su Urdhva Tiryakbhyam, organizzato in una gerarchia di blocchi costitutivi più piccoli: unità a 3 bit formano unità a 6 bit, che costruiscono unità a 12 bit, 13 bit, 26 bit e 52 bit, tutte combinate nello stadio finale a 53 bit. L'architettura separa il lavoro in tre fasi principali—calcolo del segno, somma dell'esponente e biasing, e moltiplicazione della mantissa seguita dalla normalizzazione—allineandosi allo standard IEEE-754 per la virgola mobile mentre elimina circuiti ridondanti.
Blocchi di dimensione primo per un hardware più pulito
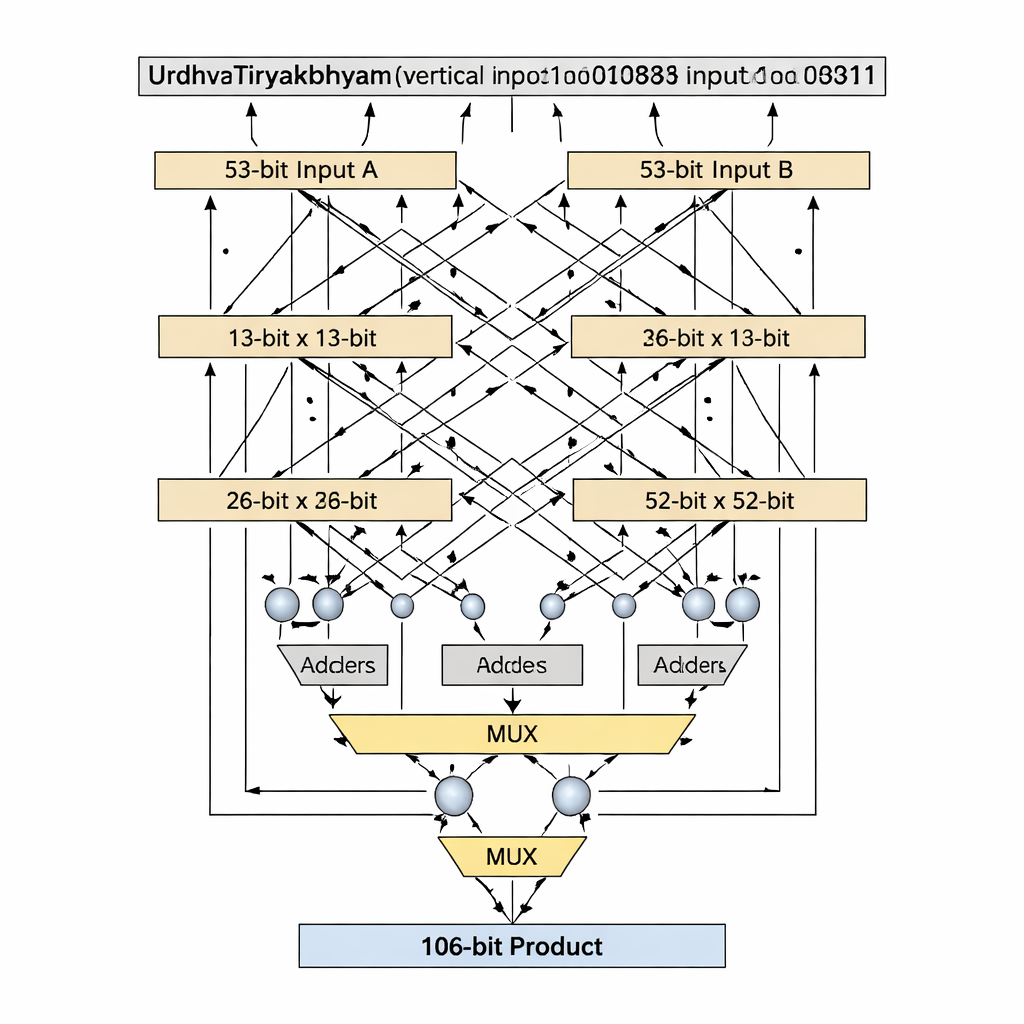
Un'innovazione chiave è come il progetto gestisce larghezze di bit che sono numeri primi, come 13 e 53, che non si dividono ordinatamente in blocchi di dimensione uguale. Le decomposizioni vediche standard presuppongono ingressi divisi in parti uguali, ma questo diventa scomodo o dispendioso per lunghezze prime. Gli autori introducono un algoritmo "prime-bit" che riutilizza in modo intelligente un moltiplicatore vedico più piccolo (n−1) bit, più addizionatori, multiplexer e un singolo gate logico extra, per emulare un moltiplicatore n-bit senza padding. Per lo stadio a 13 bit, gli ingressi sono divisi in sezioni da 1 bit e 12 bit; i prodotti parziali sono creati usando un moltiplicatore vedico a 12 bit, selezione condizionale (tramite multiplexer) basata sui bit più significativi e un piccolo numero di addizionatori. Lo stesso schema scala fino a 53 bit con un core a 52 bit. Questa decomposizione su misura accorcia il percorso critico—la catena più lunga di logica che un segnale deve attraversare—mantenendo bassa la quantità di elementi logici.
Vantaggi misurati in velocità, dimensioni ed energia
Il progetto è stato descritto in linguaggio di descrizione hardware Verilog e implementato su una FPGA Xilinx Zynq usando gli strumenti Vivado. Tra moltiplicatori vedici da 13, 26, 52, 53 e 64 bit, l'unità proposta a 53 bit mostra un equilibrio favorevole tra ritardo, uso di logica (lookup table e pin I/O) e consumo energetico stimato. Rispetto a moltiplicatori a doppia precisione precedenti basati su Booth, Karatsuba e altre disposizioni vediche, la nuova architettura riduce in modo significativo il ritardo nel caso peggiore e la quantità di risorse FPGA necessarie, senza aggiungere complessità al circuito di supporto della virgola mobile. Poiché la moltiplicazione della mantissa è più veloce e la profondità logica è minore, l'attività di commutazione si riduce, il che indica un prodotto potenza–ritardo migliore anche se confronti diretti di potenza tra tecnologie diverse sono difficili da effettuare.
Impatto su IA ed elaborazione del segnale
Per testare il progetto in un carico di lavoro reale, gli autori hanno integrato il loro moltiplicatore vedico a doppia precisione nel motore di convoluzione di una rete neurale convoluzionale, dove le operazioni di moltiplicazione e accumulo dominano il tempo di esecuzione. Sostituire moltiplicatori convenzionali IEEE-754 e precedenti moltiplicatori vedici con il nuovo design ha ridotto il ritardo delle convoluzioni, diminuito il consumo energetico e abbassato il tempo di inferenza, mantenendo la stessa accuratezza di classificazione. Vantaggi simili sono attesi in altri compiti intensivi di calcolo, come il filtraggio digitale, il rilevamento dei bordi e le pipeline per immagini mediche, dove moltiplicatori più veloci aumentano direttamente la produttività e possono permettere ai dispositivi di funzionare più freschi o con batterie più piccole.
Cosa significa per la tecnologia di tutti i giorni
In termini semplici, l'articolo dimostra che prendere in prestito un'idea di moltiplicazione intelligente dalla matematica vedica e adattarla accuratamente ai formati binari moderni può produrre un moltiplicatore più piccolo, più veloce e più efficiente dal punto di vista energetico rispetto ai progetti standard. Questo blocco migliorato può essere inserito in processori, chip per l'elaborazione del segnale e acceleratori per l'IA, portando ad analisi dei dati più rapide, dispositivi più reattivi e potenzialmente a un consumo di energia inferiore in sistemi che vanno dagli smartphone agli scanner medici. Gli autori delineano anche direzioni future, inclusa la logica reversibile per un uso energetico ancora minore e l'integrazione in unità di elaborazione più grandi, suggerendo che questo matrimonio tra aritmetica antica e hardware moderno è solo all'inizio.
Citazione: Kumar, A.S., Sahitya, G., Kusuma, R. et al. Efficient computation and design of high speed double precision Vedic multiplier architecture. Sci Rep 16, 7364 (2026). https://doi.org/10.1038/s41598-026-38147-w
Parole chiave: moltiplicatore vedico, aritmetica in virgola mobile, progettazione FPGA, elaborazione digitale del segnale, reti neurali convoluzionali