Clear Sky Science · it
Applicazione di reti neurali profonde basate su sciami e modelli ensemble per la ricostruzione di dati di conduttività specifica
Perché colmare i vuoti nei dati è importante
Le acque costiere sono la prima linea dove l'attività umana incontra l'oceano. Gli scienziati monitorano la salinità di queste acque usando una misura chiamata conduttività specifica, che aiuta a rivelare sversamenti inquinanti, variazioni nel flusso di acqua dolce e cambiamenti ambientali a lungo termine. Ma i sensori guastano, le tempeste interrompono l'alimentazione e gli strumenti hanno limiti operativi. Il risultato sono fastidiosi vuoti nelle registrazioni chiave—proprio quando gestori e ricercatori hanno più bisogno di dati continui. Questo studio pone una domanda pratica: l'intelligenza artificiale moderna può "riparare" in modo affidabile quei registri interrotti in modo che le decisioni costiere siano basate su informazioni complete e attendibili?
Osservare il respiro del Golfo
I ricercatori si sono concentrati sul Golfo del Messico, uno dei più grandi ecosistemi marini del mondo e una regione sotto forte pressione industriale e agricola. Hanno utilizzato misure di cinque stazioni dell'U.S. Geological Survey vicino al fiume Pascagoula e al Mullet Lake, ciascuna registrante la salinità dell'acqua (tramite conduttività specifica), la temperatura e il livello dell'acqua ogni 15 minuti. Una stazione, chiamata E, aveva circa il 5% dei dati di conduttività specifica mancanti—esattamente il tipo di problema che affrontano le reti di monitoraggio reali. I dati delle quattro stazioni vicine costituivano una sorta di rete di sicurezza ambientale: anche quando la stazione E rimaneva cieca, le altre continuavano a osservare. L'idea centrale era insegnare ai modelli computazionali come tutte e cinque le stazioni "respirano" insieme in modo che i vuoti in un sito possano essere inferiti a partire dai record completi degli altri.
Mettere alla prova algoritmi intelligenti
Per affrontare il problema, il team ha messo insieme una rosa di dieci approcci di modellazione diversi. Da un lato c'erano strumenti familiari come la regressione lineare multipla, che cerca di tracciare relazioni di tipo lineare tra ingressi e uscite. Al centro si collocano modelli più flessibili come reti neurali classiche, sistemi a logica fuzzy e una speciale rete a memoria a lungo termine (LSTM) spesso usata per dati temporali. Hanno impiegato anche un metodo auto‑organizzante chiamato group method of data handling (GMDH) e una variante non lineare (NGMDH) che può costruire formule multilivello autonomamente. Infine hanno introdotto metodi ad albero: un singolo modello ad albero decisionale (CART) e due approcci "ensemble"—Random Forest e XGBoost—che combinano molti alberi per prendere una decisione finale, un po' come una giuria di esperti che vota una risposta.
Apprendimento profondo potenziato dallo sciame
L'addestramento delle reti neurali profonde è notoriamente difficile: le loro numerose manopole e parametri possono facilmente incastrarsi in configurazioni scadenti. Per migliorarle, gli autori hanno accoppiato LSTM e NGMDH con un metodo di ottimizzazione recente ispirato ai flussi d'acqua turbolenti, chiamato turbulent flow of water‑based optimization (TFWO). In questo schema, ogni possibile insieme di parametri del modello è immaginato come una "particella" che si muove in un pattern a vortice nello spazio delle soluzioni. Nel corso di molti cicli, le particelle vengono spinte verso regioni che forniscono errori di previsione minori. Questa ricerca in stile sciame ha reso entrambi i tipi di reti neurali sensibilmente più accurate rispetto alle versioni standard, riducendo gli errori medi di circa il 6–11 percento. Tuttavia, anche questi modelli profondi migliorati sono stati alla fine superati dagli approcci basati sugli alberi.
Gli ensemble prendono il largo
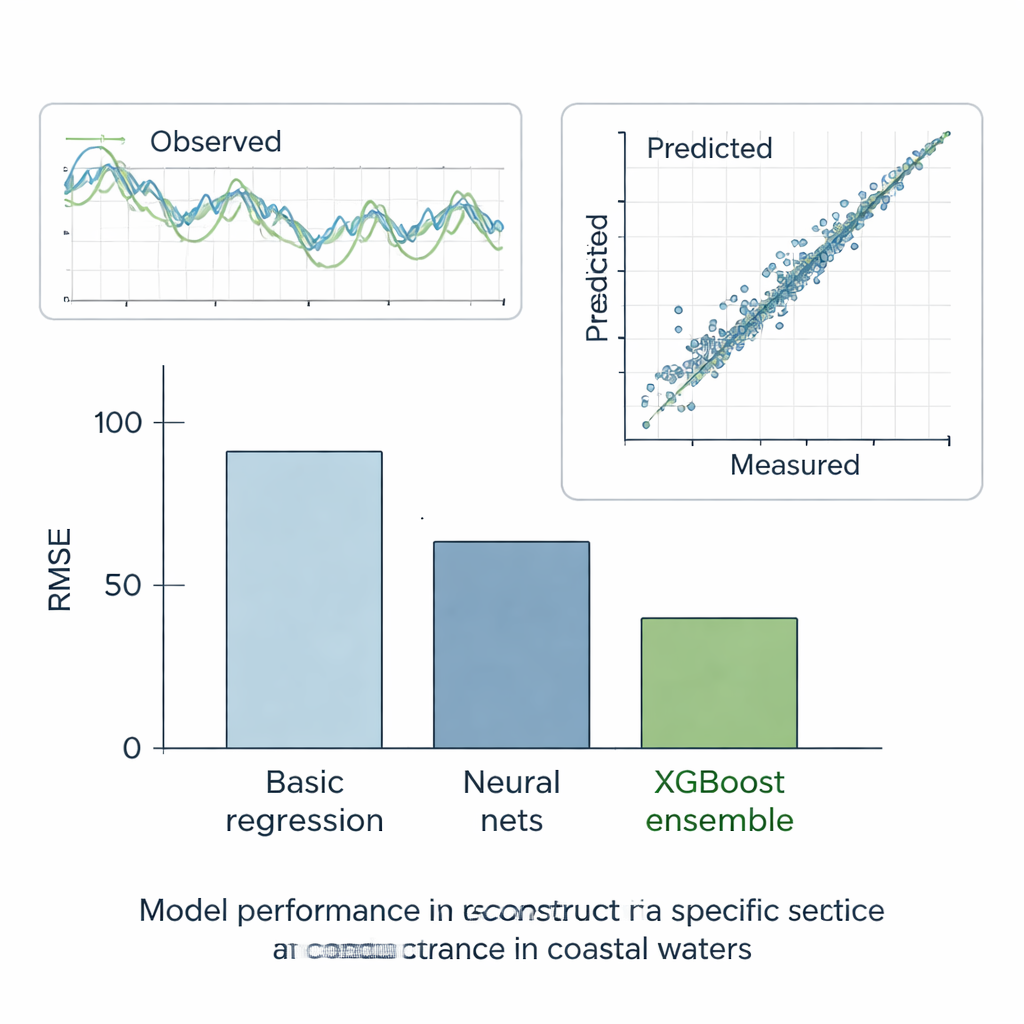
Gli autori hanno testato rigorosamente tutti i metodi in sei scenari. In cinque casi "what‑if" hanno nascosto porzioni di registrazioni altrimenti complete e verificato quanto bene ciascun modello riuscisse a ricostruire i valori mancanti. Nel caso finale, realistico, hanno chiesto ai modelli di colmare i veri vuoti della stazione E usando i dati delle stazioni vicine. In questi test, il metodo lineare più semplice ha dato le prestazioni peggiori, mentre i modelli standard di machine learning hanno fatto molto meglio, riducendo l'errore di circa la metà. Gli alberi decisionali, che suddividono automaticamente i dati in gruppi più omogenei, hanno ulteriormente migliorato i risultati. Ma il vincitore netto è stato l'ensemble XGBoost: costruendo centinaia di alberi che correggono ciascuno gli errori dei precedenti, ha raggiunto errori estremamente bassi e un quasi perfetto accordo tra conduttività specifica prevista e misurata. Le sue ricostruzioni seguivano da vicino le serie temporali osservate e riproducevano il comportamento statistico complessivo dei record di qualità dell'acqua.
Che cosa significa per le coste e oltre
Per i non specialisti, il messaggio è semplice: l'IA progettata con cura può riempire in modo affidabile i pezzi mancanti dei registri di qualità delle acque costiere, soprattutto quando sono disponibili stazioni vicine che forniscono il contesto. Pur essendo potenti, le reti neurali avanzate non sempre risultano le più accurate; questo studio mostra che metodi ensemble basati su alberi come XGBoost possono essere ancora più precisi e, nella pratica, la scelta migliore per riparare dataset ambientali. Con strumenti robusti per riempire i vuoti, gli scienziati possono monitorare meglio i cambiamenti sottili nella salinità costiera, identificare eventi di inquinamento e supportare decisioni gestionali senza essere ostacolati dagli inevitabili guasti dei sensori. Le stesse strategie possono essere adattate a molti altri problemi ingegneristici e ambientali in cui i flussi di dati sono abbondanti, rumorosi e talvolta incompleti.
Citazione: Mahdavi-Meymand, A., Sulisz, W. & Nandan Bora, S. Application of swarm-based deep neural networks and ensemble models for reconstruction of specific conductance data. Sci Rep 16, 7292 (2026). https://doi.org/10.1038/s41598-026-38136-z
Parole chiave: qualità delle acque costiere, conduttività specifica, apprendimento automatico, ricostruzione di dati mancanti, XGBoost