Clear Sky Science · it
UncerTrans: trasformatore temporale consapevole dell'incertezza per la previsione anticipata delle azioni
Perché vedere le azioni in anticipo può mantenerci al sicuro
Immaginate un robot domestico che, dalla sola prima vibrazione di un polso, riesca a capire se qualcuno sta per versare acqua calda in sicurezza in una tazza oppure per ribaltare accidentalmente il bollitore. In fabbriche, ospedali e case intelligenti, le macchine condividono sempre più spesso lo spazio con le persone, e reagire soltanto dopo che un incidente è iniziato è troppo tardi. Questo articolo presenta UncerTrans, un nuovo sistema di IA che non solo predice cosa è probabile che una persona stia per fare basandosi sui primissimi istanti di un’azione, ma indica anche quanto è sicuro della sua ipotesi—un’abilità cruciale quando è in gioco la sicurezza umana.
Dal guardare al prevedere le azioni umane
La maggior parte degli attuali sistemi di visione artificiale riconosce ciò che qualcuno sta facendo solo quando l’azione è quasi terminata: classificano un clip video completo come “tagliare verdure” o “prendere una tazza”. Questo è utile per analisi successive, ma non per prevenire ustioni, collisioni o cadute. La previsione anticipata delle azioni affronta un problema più difficile: decidere quale azione completa seguirà osservando solo il 10–20% iniziale. La difficoltà è che molte azioni appaiono simili all’inizio—allungare la mano verso un bollitore potrebbe significare versare una bevanda o urtarlo—quindi un sistema deve lavorare con poche informazioni e comunque evitare errori pericolosi.
Insegnare a una macchina a concentrarsi sui momenti giusti
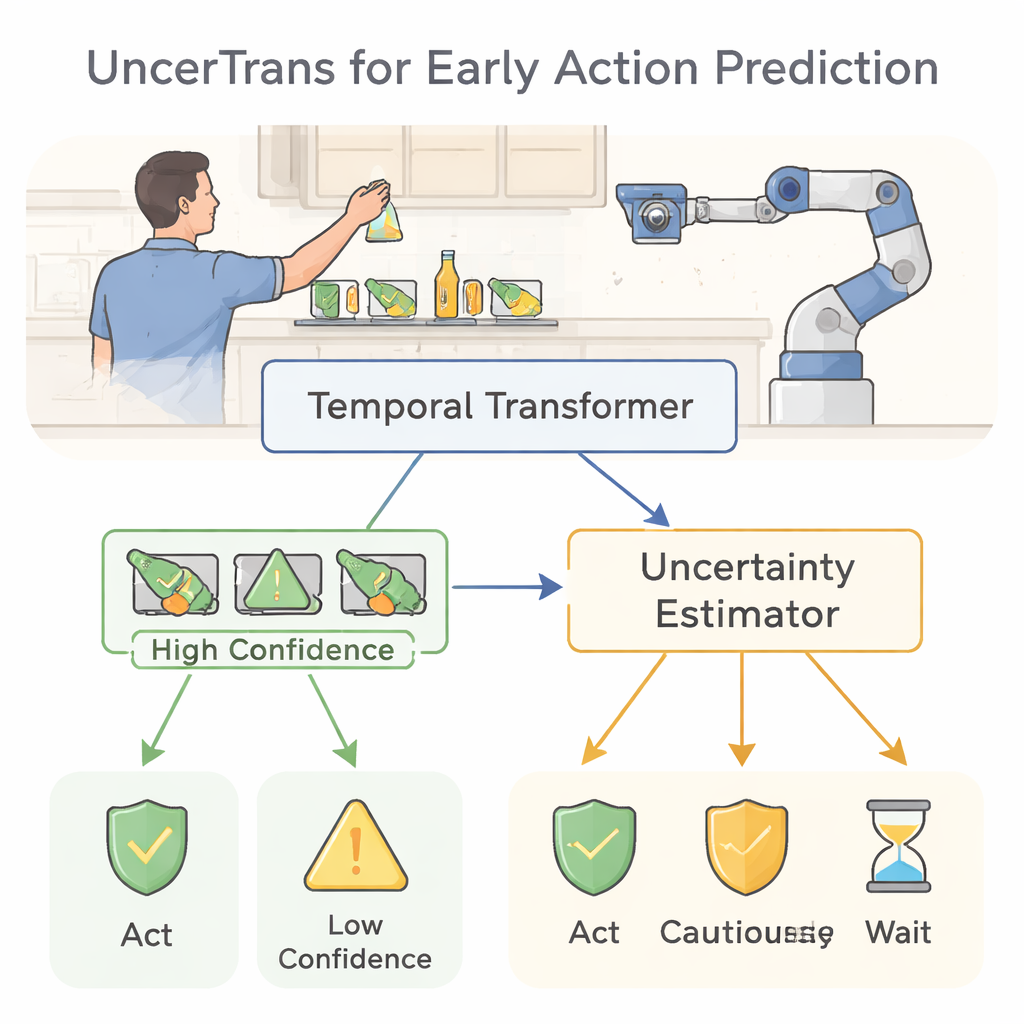
UncerTrans affronta questo problema usando un trasformatore temporale, una moderna architettura neurale sviluppata originariamente per il linguaggio. Invece di leggere parole in una frase, osserva brevi frammenti di video nel tempo. Il modello suddivide una sequenza d’azione precoce in alcuni segmenti e sfrutta un meccanismo di attenzione per decidere quali momenti sono più importanti. I frame più recenti ricevono un peso maggiore, in accordo con l’intuizione che l’ultimo movimento spesso rivela l’intento più chiaramente. Questa progettazione permette al sistema di cogliere sia dettagli fini, come il movimento delle dita, sia schemi più ampi, come la traiettoria di un braccio, anche quando osserva solo una frazione dell’azione completa.
Far ammettere a una macchina quando è insicura
Un’innovazione chiave di UncerTrans è che non si ferma a una singola risposta netta. Invece, esegue lo stesso input attraverso la rete molte volte con leggere variazioni usando una tecnica chiamata Monte Carlo dropout. Ogni esecuzione annulla a caso connessioni interne diverse, producendo predizioni leggermente diverse. Analizzando quanto queste predizioni divergono, il sistema può stimare la propria incertezza: previsioni strettamente raggruppate indicano alta fiducia, mentre previsioni disperse segnalano dubbio. UncerTrans separa inoltre l’incertezza dovuta a esperienza di addestramento limitata dal rumore nel video stesso, e regola dinamicamente quante esecuzioni di test eseguire—utilizzandone di più quando i primi campioni appaiono ambigui e di meno quando sono già concordi.
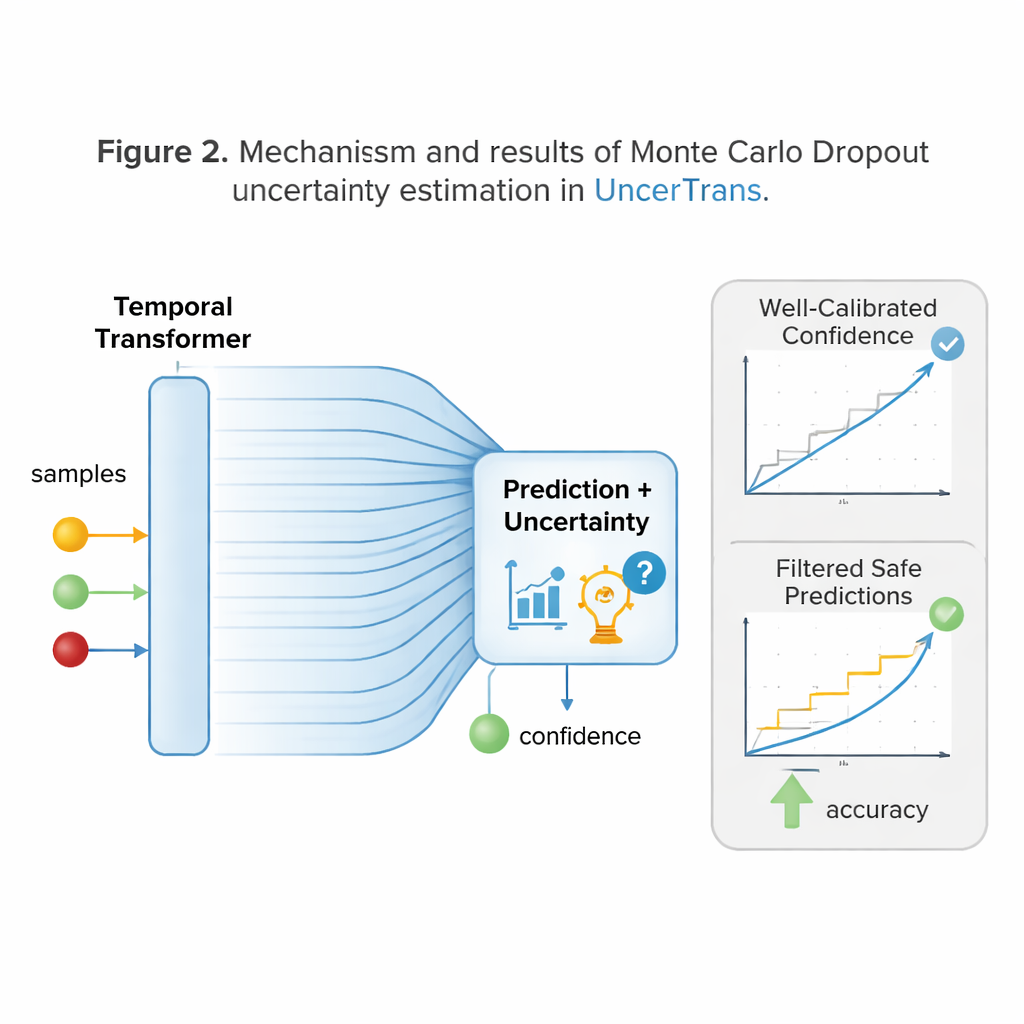
Trasformare la fiducia in decisioni più sicure
Sapere quando si può sbagliare è utile solo se cambia il comportamento. UncerTrans converte le sue stime di fiducia in scelte pratiche. Per predizioni a bassa incertezza, il sistema può agire con decisione—per esempio attivando un avviso o spostando un braccio robotico fuori dalla zona di pericolo. Quando l’incertezza è moderata, può optare per comportamenti più conservativi e sicuri, come rallentare il robot o chiedere ulteriori informazioni. Se l’incertezza è molto alta, può rifiutare di decidere e limitarsi a osservare. I test su un ampio dataset video “in prima persona” in cucina mostrano che UncerTrans predice le azioni imminenti con maggiore accuratezza rispetto a diversi forti concorrenti, soprattutto quando è visibile solo il primo 10% dell’azione. È significativo che scartando solo il 30% dei casi più incerti, l’accuratezza delle predizioni rimanenti salga a circa l’84%, dimostrando il valore reale del filtraggio consapevole dell’incertezza.
Cosa significa questo per il lavoro quotidiano uomo–robot
Per un non specialista, il messaggio è chiaro: UncerTrans rappresenta un passo verso macchine che non solo indovinano la nostra prossima mossa da indizi limitati, ma sanno anche quando questi indizi sono affidabili. Combinando un modello visivo sensibile al tempo con un “misuratore di fiducia” interno, il sistema può reagire più rapidamente e più in sicurezza in ambienti reali affollati come cucine, stabilimenti e strutture di assistenza. Sebbene il metodo comporti ancora costi computazionali e richieda ulteriori perfezionamenti, offre un progetto promettente per futuri robot e sistemi di monitoraggio che prevedono in anticipo i pericoli, rispondono con cautela quando sono incerti e, in definitiva, si integrano in modo più sicuro negli spazi umani.
Citazione: Zhai, X., Liu, Y. UncerTrans: uncertainty-aware temporal transformer for early action prediction. Sci Rep 16, 7068 (2026). https://doi.org/10.1038/s41598-026-38107-4
Parole chiave: previsione anticipata delle azioni, collaborazione uomo-robot, incertezza nell'IA, modelli di visione transformer, sistemi intelligenti sicuri