Clear Sky Science · it
Integrazione di Swin-T semplificato con EFS-Net modificato per la segmentazione guidata da attenzione di condotte sottomarine in ambienti marini complessi
Perché osservare il fondale è importante
Nascosti sotto le onde, vasti reticoli di tubazioni trasportano petrolio, gas e cavi elettrici di cui le società moderne dipendono. Se queste condotte subacquee si incrinano, corrodono o si spostano, il risultato può essere costose interruzioni e gravi inquinamenti. Oggi gran parte delle ispezioni è svolta da operatori umani che passano ore a esaminare video torbidi provenienti da robot subacquei. Questo articolo presenta un nuovo sistema di intelligenza artificiale (IA) in grado di individuare automaticamente le tubazioni in immagini subacquee difficili, anche quando sono deboli, offuscate dalla “nevicata” marina o parzialmente sepolte nella sabbia. Questo passo verso ispezioni automatiche affidabili potrebbe rendere più sicure e meno costose la manutenzione dell’energia offshore e delle infrastrutture.

Vedere chiaramente in un mondo torbido
Le immagini subacquee sono notoriamente difficili da interpretare per i computer. La luce svanisce rapidamente con la profondità, i colori si spostano verso il verde e il blu, e particelle sospese creano foschia e puntini simili alla neve. Le tecniche classiche di elaborazione, che si basano su contorni netti e contrasto pulito, tendono a fallire quando la condotta è coperta di sabbia, nascosta da piante o sfocata dalla foschia. Il deep learning ha migliorato la situazione, e diverse reti neurali note possono già riconoscere tubi in dataset specifici. Tuttavia questi sistemi solitamente si specializzano in un certo tipo di condizione dell’acqua o configurazione della camera. Quando incontrano un nuovo ambiente—acque, illuminazione o sfondo diversi—la loro precisione cala drasticamente. La sfida centrale è costruire un modello che sia allo stesso tempo accurato e adattabile, ma anche efficiente abbastanza da funzionare nei sistemi di ispezione reali.
Un approccio a due cervelli per le immagini subacquee
Gli autori affrontano il problema costruendo un’architettura ibrida che combina due “modalità di visione” molto differenti. Un ramo, basato su una versione snellita del Swin Transformer, agisce come un osservatore grandangolare. Scansiona l’intero fotogramma per cogliere schemi su larga scala, come il percorso complessivo di una condotta sul fondale. Il secondo ramo, adattato da un modello chiamato EFS-Net e alimentato da una backbone EfficientNet, si comporta come una lente d’ingrandimento. Si concentra sui dettagli fini—contorni, texture e strutture sottili che rivelano dove inizia la tubazione e dove termina la sabbia o la vegetazione. Entrambi i rami elaborano le stesse immagini ridimensionate e le trasformano in mappe di caratteristiche interne che descrivono ciò che la rete ritiene possano essere strutture significative in ciascuna regione dell’immagine.
L’attenzione decide cosa conta
Semplicemente sovrapporre le uscite di questi due rami creerebbe un groviglio di informazioni ridondanti. Invece, il modello utilizza un meccanismo di “attenzione” per decidere, pixel per pixel, quali dettagli meritano attenzione. Un modulo di cross-attention a tre teste confronta le feature del ramo orientato ai dettagli con quelle del ramo focalizzato sul contesto. In sostanza, il ramo dei dettagli pone domande mirate—“Questo contorno è parte di una condotta?”—mentre il ramo del contesto fornisce indizi globali—“Una linea in questa posizione e direzione ha senso come parte di un tubo?” Un ulteriore passaggio di raffinamento, chiamato CBAM, potenzia ulteriormente il segnale dalle regioni probabilmente corrispondenti alla condotta e attenua il rumore di fondo come rocce, alghe o particelle sospese. Una rete decoder poi ricostruisce gradualmente una maschera a dimensione piena che segna ogni pixel come condotta o non condotta.
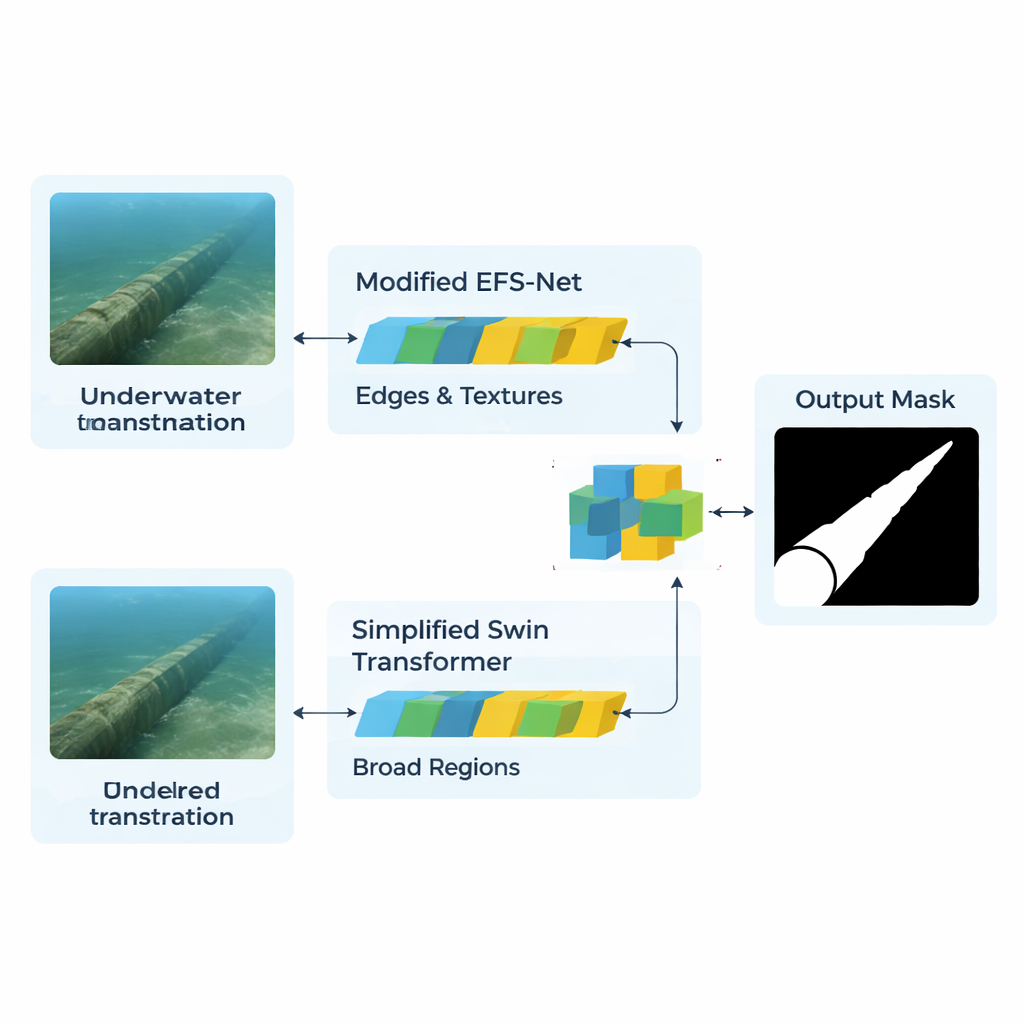
Mettere il sistema alla prova
Per valutare se questo progetto funziona nella pratica, i ricercatori hanno assemblato un dataset ampio e impegnativo chiamato HOMOMO. Contiene più di 120.000 immagini a colori di vere condotte sul fondale riprese lungo 1,2 chilometri di tubazione in condizioni variabili e spesso ostili: scarsa illuminazione, nebbia marina, “nevicata” flottante, dune di sabbia e fitta vegetazione. Hanno addestrato il loro modello su una parte di questa raccolta e poi lo hanno confrontato con sistemi ampiamente usati come UNet, DeepLab, SwinUNet, TransUNet, Mask2Former e varie versioni del rilevatore di oggetti YOLO. Su HOMOMO, il loro modello ibrido ha segmentato correttamente i pixel delle condotte con un intersection-over-union medio di circa il 98%, sostanzialmente superiore al miglior metodo concorrente. Altrettanto importante, quando testato—senza riaddestramento—su due sorgenti d’immagine molto diverse, un dataset sintetico Roboflow e filmati reali da YouTube, il modello ha comunque mostrato prestazioni solide, dimostrando di saper gestire nuove camere e condizioni dell’acqua.
Implicazioni per il mare reale
Per i non specialisti, la conclusione è che questo sistema IA può delineare in modo affidabile le condotte subacquee in fotogrammi video troppo rumorosi e incoerenti per i metodi convenzionali. Combinando una visione globale della scena con un occhio attento ai contorni e alle texture, e usando l’attenzione per fondere queste prospettive, il modello raggiunge alta precisione senza richiedere potenza di calcolo massiccia. In termini pratici, uno strumento del genere potrebbe aiutare robot autonomi a monitorare continuamente estese tratte di infrastrutture sottomarine, segnalando possibili danni o interramento per la revisione umana. Pur incontrando ancora difficoltà con tubazioni estremamente sottili o completamente nascoste, l’approccio rappresenta un passo importante verso ispezioni più sicure e automatizzate dell’impiantistica nascosta che sostiene le moderne reti energetiche e di comunicazione.
Citazione: Hosseini, N., Mohanna, F. & Moghimi, M.K. Integrating simplified Swin-T with modified EFS-Net for attention-guided underwater pipelines segmentation in complex underwater environments. Sci Rep 16, 6987 (2026). https://doi.org/10.1038/s41598-026-38081-x
Parole chiave: condotte sottomarine, segmentazione immagini, deep learning, ispezione marina, reti transformer