Clear Sky Science · it
YOLC con attenzione dinamica sparsa per il rilevamento ad alta velocità di piccoli bersagli in immagini sportive indossabili
Vedere lo sport attraverso gli occhi di un giocatore
Immagina di osservare un servizio di tennis o uno scambio di ping-pong non dagli spalti, ma attraverso una videocamera fissata alla testa di un atleta. La palla sfreccia nel campo visivo come una piccola sfocatura, eppure allenatori e analisti vorrebbero sapere esattamente dove è andata, quanto velocemente e come hanno reagito i giocatori. Questo articolo presenta un nuovo sistema di visione artificiale chiamato YOLC, progettato per individuare e seguire questi oggetti piccoli e veloci in tempo reale su dispositivi indossabili compatti e a basso consumo.
Perché i bersagli piccoli e veloci sono così difficili da catturare
Le videocamere indossabili sono diventate comuni negli allenamenti sportivi, catturando video in prima persona di partite ed esercitazioni. Ma da questo punto di vista, oggetti cruciali – un volano, una pallina da tennis, il piede di partenza di uno sprinter – spesso occupano solo poche decine di pixel e si spostano rapidamente da un fotogramma all’altro. I sistemi di rilevamento esistenti sono o troppo pesanti per dispositivi a basso consumo o perdono il tracciamento quando gli oggetti sono piccoli, sfocati o lontani. Gli autori mostrano che nel materiale sportivo reale molti bersagli sono più piccoli di 32 per 32 pixel e si muovono così velocemente tra i fotogrammi che i metodi standard li mancano o ne perdono ripetutamente l’identità, interrompendo le traiettorie e compromettendo qualsiasi analisi prestazionale seria.
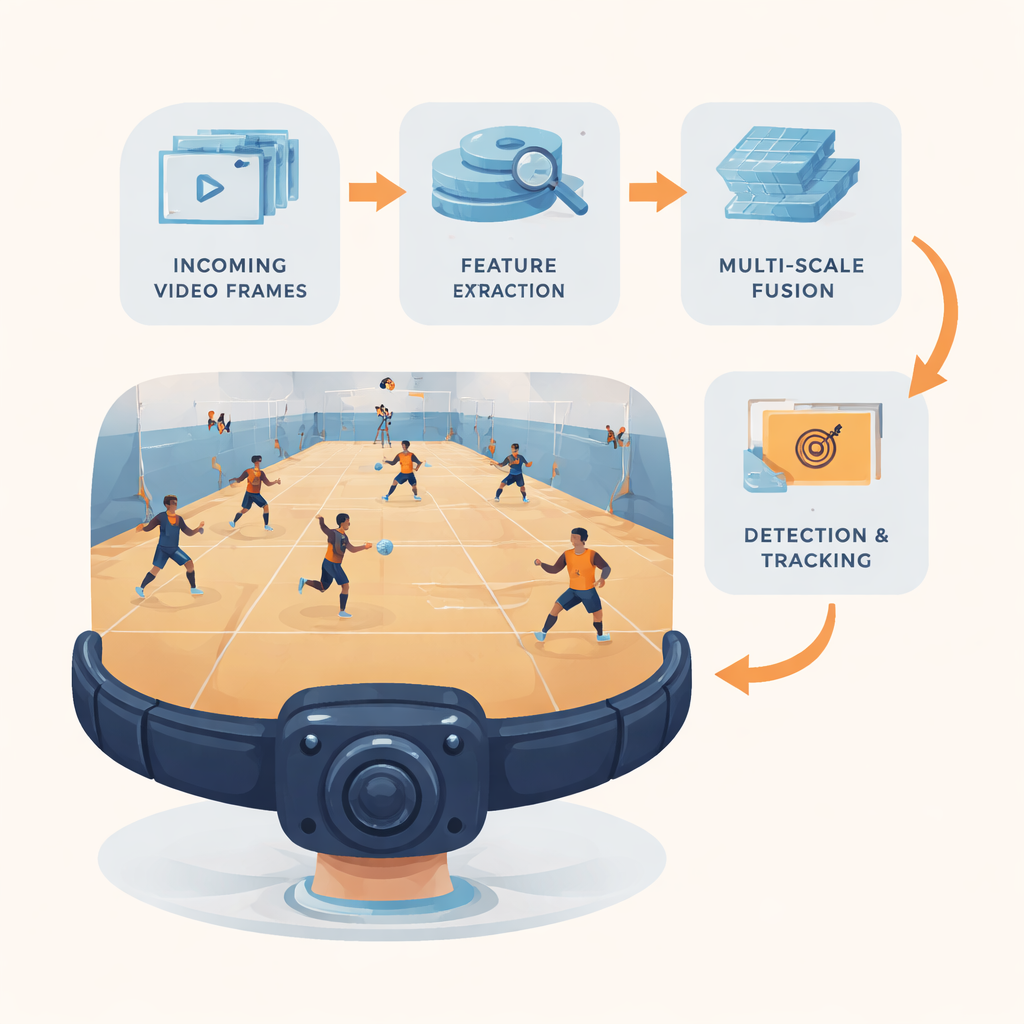
Una pipeline di visione leggera per videocamere indossabili
I ricercatori introducono YOLC (abbreviazione di “You Only Look Clusters”), una pipeline completa di rilevamento e tracciamento pensata per hardware edge come un NVIDIA Jetson Nano. Al centro c’è un estrattore di caratteristiche snello costruito su una famiglia di reti neurali efficienti nota come MobileNet, rimodellata per usare per lo più operazioni “economiche” che riducono sia memoria sia calcolo mantenendo però abbastanza dettaglio per vedere oggetti minuscoli. I fotogrammi video vengono ridimensionati a una risoluzione bilanciata e vengono prodotti tre livelli di mappe di caratteristiche: una che enfatizza i dettagli fini per bersagli piccoli, una per oggetti di dimensione media e una con semanticità di alto livello per oggetti grandi o distanti. Queste mappe multiscala alimentano il resto del sistema, progettato con cura per spremere quante più informazioni possibile da ogni operazione.
Lasciare alla rete il compito di guardare solo dove conta
Un’innovazione centrale è un meccanismo di “attenzione dinamica sparsa” che imita il modo in cui un umano potrebbe lanciare uno sguardo solo alle parti più informative di una scena. Invece di processare ogni pixel allo stesso modo, YOLC misura quanto cambia localmente l’immagine – ad esempio ai bordi, agli angoli o nel contorno di una palla in movimento – e costruisce una mappa dei punti dove la trama è più pronunciata. Mantiene quindi solo circa il 30 percento di queste posizioni ad alta risposta per l’elaborazione successiva, spegnendo di fatto le regioni di sfondo rumorose come pareti, spalti o cielo. Un trucco di addestramento speciale permette al modello di rimanere completamente allenabile nonostante questo taglio netto. Questa concentrazione selettiva non solo migliora l’accuratezza ignorando le distrazioni, ma riduce drasticamente anche il lavoro che la rete deve svolgere, un vantaggio cruciale sui dispositivi indossabili alimentati a batteria.
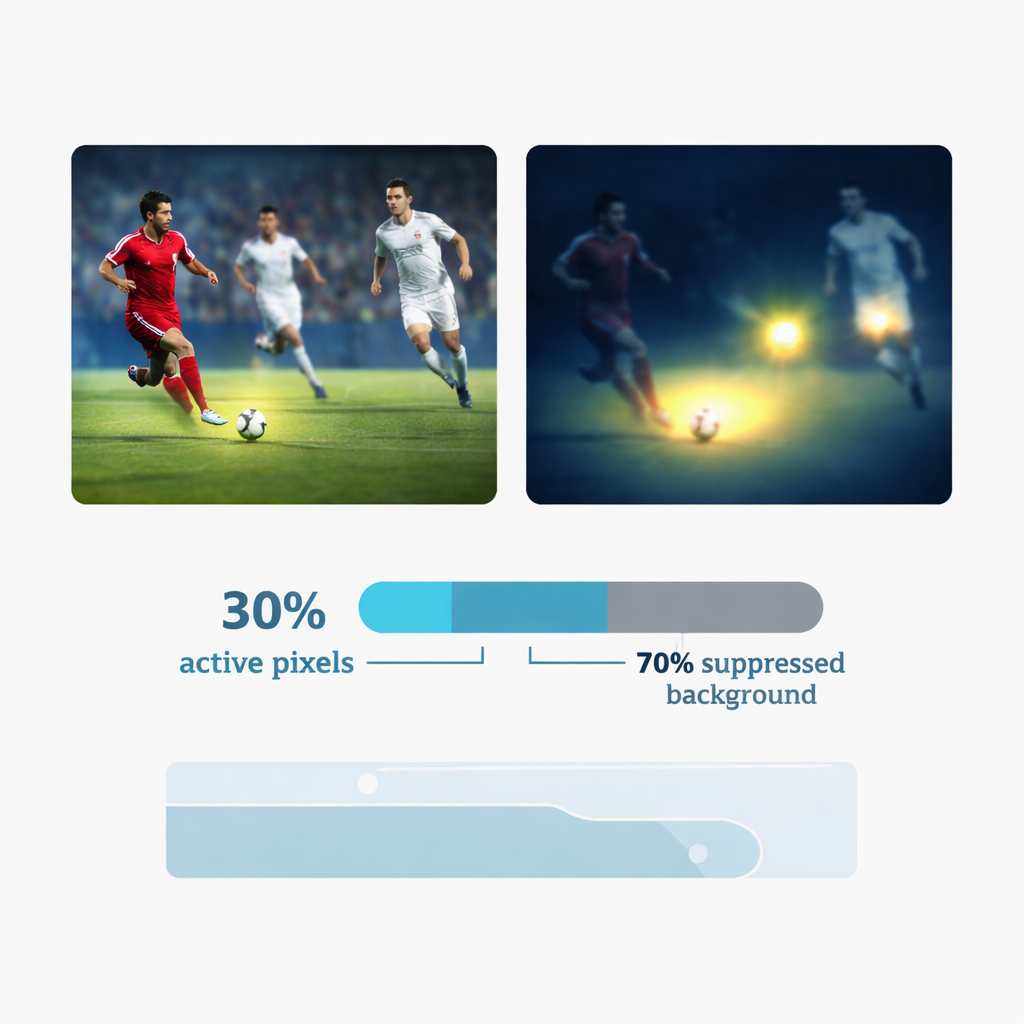
Dalle caratteristiche nette a traiettorie stabili
Dopo essersi concentrato sulle regioni chiave, YOLC combina informazioni attraverso le scale usando una piramide di caratteristiche bidirezionale che trasmette segnali sia dal grosso al fine sia dal fine al grosso. La forza di queste connessioni è guidata dalla stessa mappa di attenzione, in modo che i piccoli oggetti importanti vengano amplificati a ogni stadio. Nella fase finale di rilevamento, un’unità aggiuntiva di “attenzione coordinata” aiuta il sistema a capire meglio dove si trovano gli oggetti nel fotogramma collegando i segnali lungo le direzioni orizzontale e verticale. Per trasformare i rilevamenti fotogramma per fotogramma in tracce fluide nel tempo, il metodo aggiunge un modulo di flusso ottico leggero – uno strumento che stima come i pixel si spostano tra fotogrammi consecutivi – e uno schema di associazione in due fasi che prima abbina rilevamenti ad alta confidenza con tracce esistenti, poi riutilizza con cautela le caselle a bassa confidenza che si adattano al movimento previsto. Insieme, questi elementi riducono gli scambi di identità e i gap, anche quando gli oggetti si incrociano o sono temporaneamente nascosti.
Prestazioni nel mondo reale
Il team ha testato YOLC su un dataset sportivo personalizzato che include badminton, pallacanestro, tennis, sprint e ping-pong, tutti acquisiti con una camera montata sulla testa in ambienti di allenamento reali. Su questo materiale impegnativo, il sistema gira a 53,5 fotogrammi al secondo con appena 1,78 milioni di parametri, molto meno di molti noti rivelatori di oggetti. Ottiene un punteggio di rilevamento (mAP@0.5) del 75,3 percento e un recall per piccoli oggetti superiore all’80 percento, superando diversi modelli leggeri noti. Nei benchmark di tracciamento, YOLC mantiene traiettorie più lunghe e affidabili e riduce drasticamente gli scambi di identità. Si dimostra inoltre robusto sotto sfocatura da movimento e vibrazioni della camera, dimezzando approssimativamente il tasso di falsi allarmi rispetto ai metodi concorrenti.
Cosa significa per lo sport e oltre
Per allenatori, analisti e produttori di attrezzature, il messaggio è chiaro: una comprensione accurata e in tempo reale delle azioni sportive veloci non deve dipendere da server ingombranti o da riprese in stile televisivo impeccabili. Decidendo con cura dove e quando spendere risorse computazionali, YOLC trasforma video indossabili rumorosi e in prima persona in registrazioni dettagliate di come piccoli oggetti veloci si muovono e interagiscono con gli atleti. Questo può consentire feedback più ricchi negli allenamenti, monitoraggio più sicuro negli sport ad alta intensità e, più in generale, sistemi di visione più intelligenti su qualsiasi dispositivo piccolo che debba vedere chiaramente sotto vincoli hardware stringenti.
Citazione: Chen, H., Song, Y., Liu, W. et al. YOLC with dynamic sparse attention for high-speed small target detection in wearable sports images. Sci Rep 16, 6858 (2026). https://doi.org/10.1038/s41598-026-38079-5
Parole chiave: visione sportiva indossabile, rilevamento di piccoli oggetti, tracciamento in tempo reale, edge AI, meccanismi di attenzione