Clear Sky Science · it
La costruzione e le tecniche raffinate di estrazione del grafo della conoscenza basate su grandi modelli di linguaggio
Mappe più intelligenti per decisioni complesse
Le decisioni moderne in ambiti ad alto rischio — come operazioni su larga scala, gestione delle infrastrutture o risposta alle catastrofi — dipendono dalla capacità di comprendere rapidamente grandi quantità di informazioni frammentarie. Manuali, flussi di sensori, rapporti e simulazioni raccontano ciascuno una parte della storia, ma raramente sono organizzati in modo che persone o computer possano usarli agevolmente. Questo articolo presenta un metodo per trasformare quelle informazioni frammentate in "mappe della conoscenza" vive, alimentate da grandi modelli di linguaggio, così che pianificatori e analisti possano porre domande migliori e ottenere risposte più rapide e affidabili.
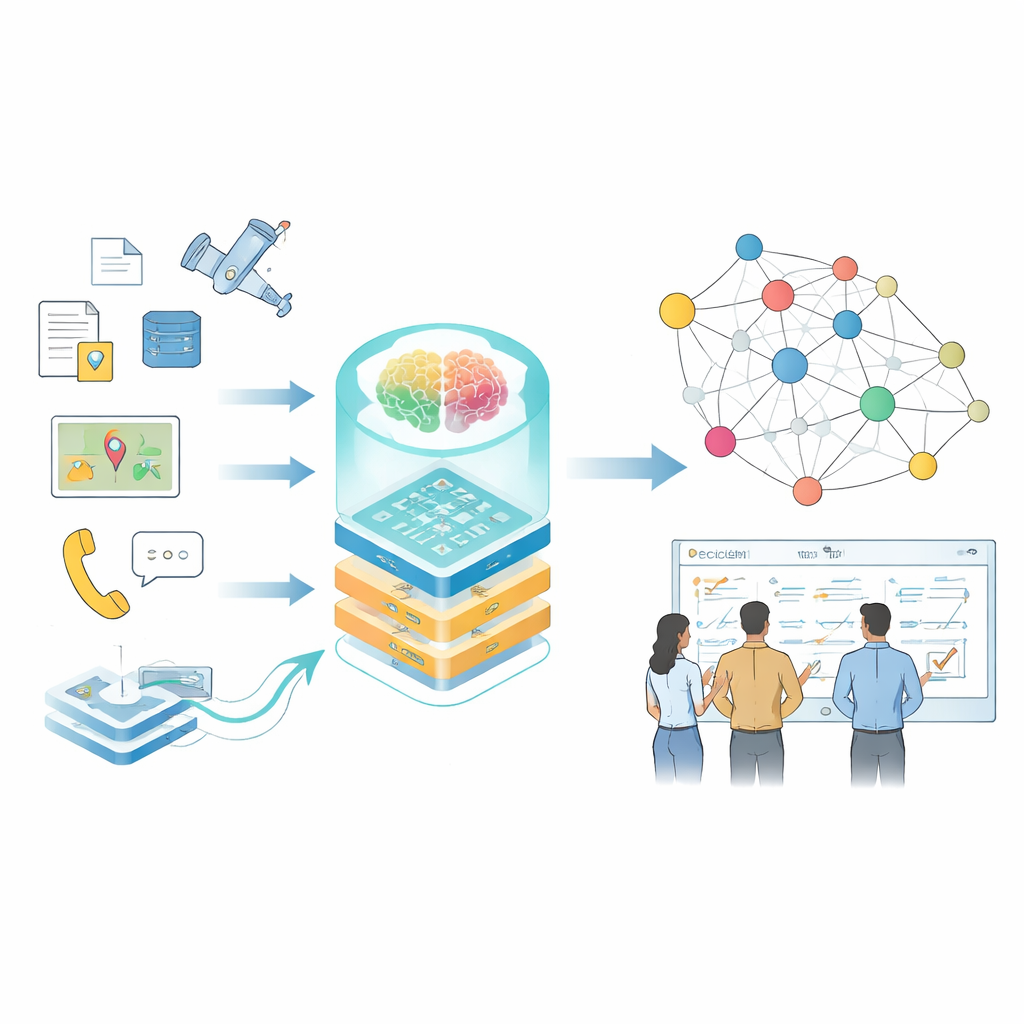
Dai fatti sparsi alla conoscenza connessa
Gli autori si concentrano sui grafi della conoscenza, una modalità di rappresentazione delle informazioni come una rete di fatti collegati — chi ha fatto cosa, con quale sistema, in quali condizioni. In contesti quotidiani tali grafi già alimentano motori di ricerca e sistemi di raccomandazione, ma i domini specializzati pongono problemi più complessi: i dati sono sensibili, la terminologia è densa, i formati vanno da rapporti in testo libero a log di sensori, e le condizioni cambiano rapidamente. Gli strumenti tradizionali basati su regole scritte a mano o su modelli di piccole dimensioni faticano a tenere il passo, e i modelli di linguaggio generici spesso interpretano male termini tecnici o non colgono relazioni sottili che sono rilevanti per decisioni reali.
Insegnare una nuova specialità ai grandi modelli di linguaggio
Per affrontare questo problema, lo studio effettua un fine‑tuning di un potente modello di base su un dataset specifico e progettato con cura. Il dataset si basa su comunicazioni di comando, manuali delle apparecchiature, scenari simulati e letteratura di esperti. Prima che questo materiale raggiunga il modello, viene fortemente desensibilizzato: coordinate concrete diventano posizioni relative, nomi di unità si trasformano in codici generici e logiche sensibili sono parzialmente oscurate pur preservando i modelli complessivi. I dati sono memorizzati in un formato strutturato che descrive la situazione più ampia, i compiti specifici (come pianificazione, classificazione delle minacce o risposta a domande) e i legami tra essi. Questa struttura permette al modello di apprendere non solo fatti isolati, ma anche come diversi compiti condividono il contesto.
Strati di adattamento per compiti diversi
Invece di riaddestrare ogni parametro del modello — un processo costoso e rischioso — gli autori utilizzano una tecnica chiamata adattamento a basso rango, organizzata in diversi strati che si concentrano ciascuno su un aspetto differente del problema. Uno strato cattura la terminologia e i concetti di base, un altro incorpora regole operative e vincoli, e un terzo si specializza nell'adattamento a compiti particolari, come la pianificazione o la valutazione delle minacce. Un componente di controllo separato, la rete di "instradamento", esamina ogni pezzo di input e decide quale combinazione di questi adattatori leggeri il modello dovrebbe usare. Questo design consente al sistema di passare efficacemente tra i compiti preservando sia la capacità linguistica generale sia l'expertise specifica del dominio.
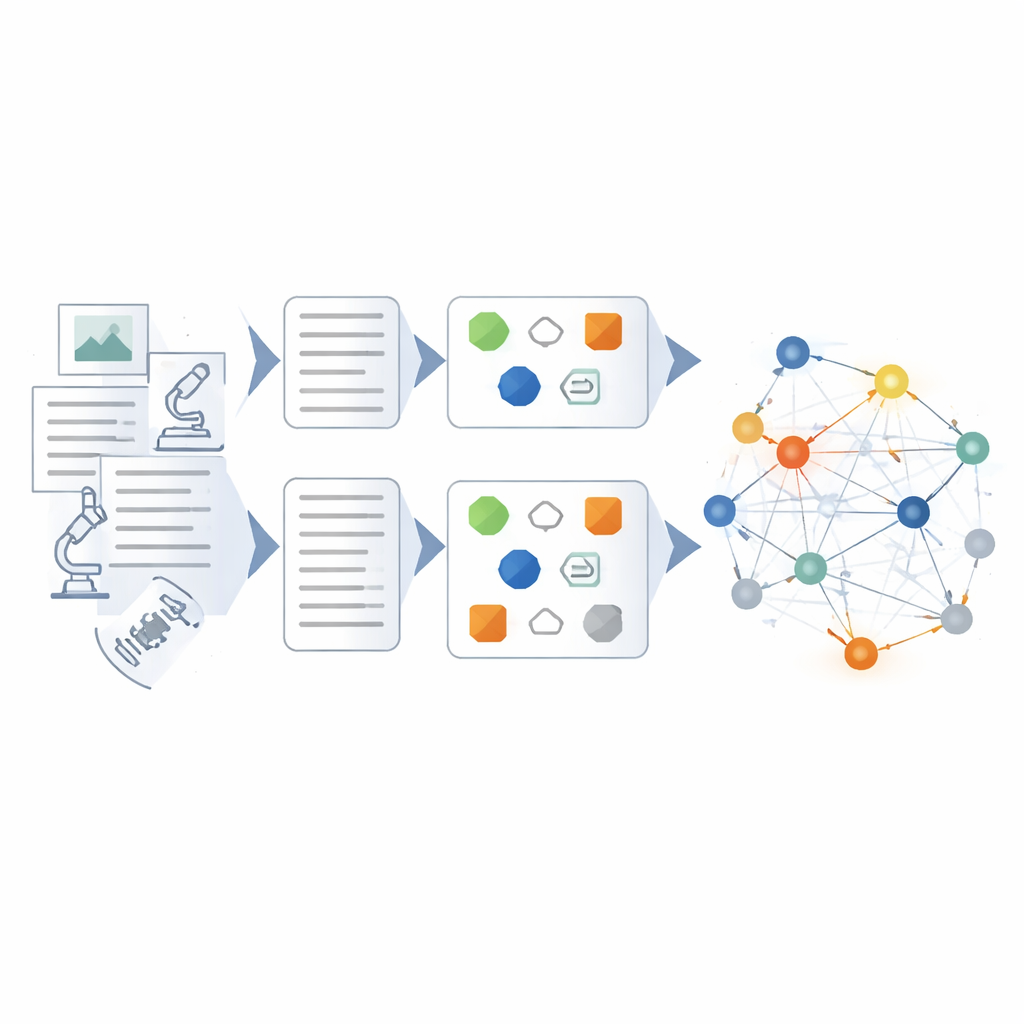
Costruire e verificare la rete di conoscenza
Sopra il modello ottimizzato, gli autori progettano una pipeline ibrida per costruire il grafo della conoscenza vero e proprio. Prima, i dati grezzi vengono puliti e standardizzati in modo che termini e formati siano coerenti. Poi, metodi basati su regole e template elaborati da esperti estraggono entità ed eventi ovvi. Il modello di linguaggio fine‑tuned interviene per gestire lavori più complessi: sintetizzare rapporti disordinati in sommari concisi, identificare attori chiave e apparecchiature, e inferire relazioni come catene di causa‑effetto o coordinazione tra unità. Ogni fatto estratto viene valutato da più angolazioni — quanto bene si adatta a schemi noti, quanto si collega ad altri fatti e se si allinea con percorsi di ragionamento multi‑passo attraverso il grafo. Solo i risultati ad alta confidenza vengono aggiunti, mentre quelli a bassa confidenza sono contrassegnati per la revisione.
Guadagni provati in accuratezza e affidabilità
Il team valuta il loro approccio su tre compiti fondamentali che rispecchiano esigenze reali: rispondere a domande complesse su regole e apparecchiature, proporre piani d'azione per situazioni date e classificare diversi scenari di minaccia per gravità. In tutti questi compiti, il modello adattato supera costantemente sistemi generali noti, inclusi modelli di punta addestrati in modo molto più generico. Risponde a più domande correttamente, produce piani più realistici e classifica le minacce con maggiore accuratezza. Il grafo della conoscenza risultante è allo stesso tempo ampio e densamente connesso, con oltre il 90 percento dei fatti memorizzati che passa severi controlli di confidenza e aiuta i pianificatori a raggiungere decisioni solide più rapidamente.
Perché questo conta in futuro
Per un lettore non specialista, il messaggio chiave è che i modelli di linguaggio possono essere trasformati da ottimi conversatori in analisti attenti e specializzati — se sono addestrati sui dati giusti, vincolati da regole chiare e costantemente verificati per qualità. Questo lavoro mostra come farlo in un dominio sensibile e in rapido cambiamento proteggendo al contempo le informazioni private. Il quadro non solo organizza la conoscenza frammentaria in una rete utilizzabile, ma mantiene anche quella rete aggiornata e affidabile, offrendo un progetto guida per futuri sistemi di supporto decisionale in qualsiasi campo dove prendere decisioni complesse sia davvero cruciale.
Citazione: Peng, L., Yang, P., Juexiang, Y. et al. The construction and refined extraction techniques of knowledge graph based on large language models. Sci Rep 16, 8104 (2026). https://doi.org/10.1038/s41598-026-38066-w
Parole chiave: grafo della conoscenza, grande modello di linguaggio, supporto alle decisioni, adattamento al dominio, desensibilizzazione dei dati