Clear Sky Science · it
Generazione di campioni limite per tester di casualità tramite ottimizzazione intelligente e algoritmi evolutivi
Perché l quasi‑casuale è importante per la sicurezza di tutti i giorni
Ogni volta che fai acquisti online, sblocchi il telefono o invii un messaggio privato, vengono lanciati dadi matematici invisibili per proteggere i tuoi dati. Questi dadi assumono la forma di lunghe sequenze di bit presumibilmente casuali usate come chiavi crittografiche. Se quei bit sono anche solo leggermente meno casuali di quanto dovrebbero essere, aggressori determinati possono talvolta individuare schemi sfruttabili. Questo articolo esplora un nuovo metodo per costruire sequenze di test “quasi‑casuali”—dati che appaiono estremamente casuali ma nascondono piccoli difetti—così che gli ingegneri possano sottoporre a stress serio i dispositivi che proteggono la nostra vita digitale.
Quando i numeri casuali non sono abbastanza casuali
I moderni sistemi di sicurezza si basano su due tipi di generatori di numeri casuali. I generatori veramente casuali attingono a effetti fisici imprevedibili, come il rumore elettronico o le fluttuazioni quantistiche, mentre i generatori pseudo‑casuali usano algoritmi che trasformano brevi semi casuali in lunghe sequenze. In pratica, la qualità di entrambi dipende in ultima analisi dalla fonte fisica di imprevedibilità, chiamata fonte di entropia. Sfortunatamente, le fonti di entropia reali sono fragili: variazioni di temperatura, invecchiamento dell’hardware o errori di progettazione possono ridurre silenziosamente la loro casualità. Per individuare tali problemi, organismi di standardizzazione come NIST definiscono batterie di test statistici che verificano se i bit in uscita appaiono sufficientemente casuali. I dispositivi inseriscono sempre più spesso “tester di casualità in tempo reale” che monitorano il proprio output durante il funzionamento. Tuttavia non esisteva un buon modo per generare casi di errore realistici e difficili da rilevare per verificare se quei controlli integrati funzionino davvero.
Progettare sequenze che falliscono di poco i test di casualità
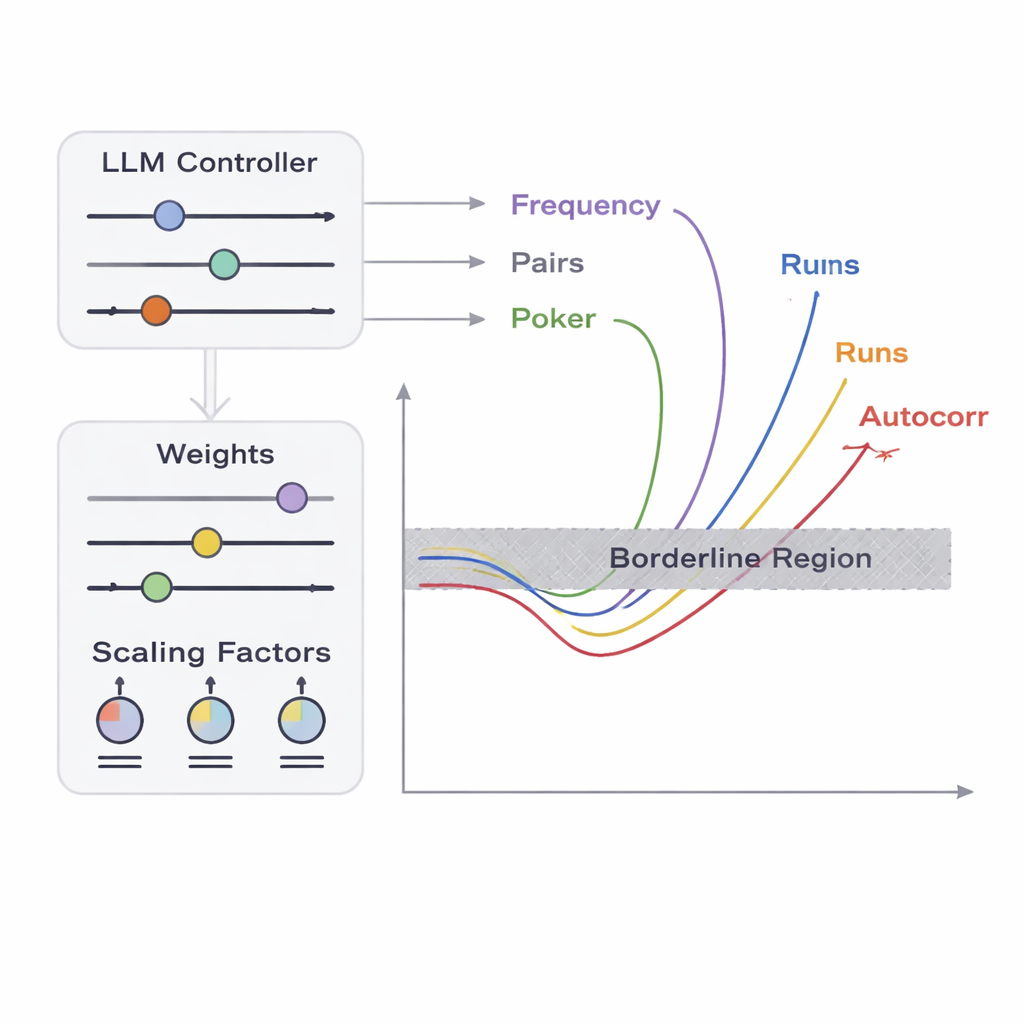
Dal punto di vista di un tester, i fallimenti banali—come output costituiti da soli zeri—sono facili da individuare. La vera sfida è rilevare i casi limite: sequenze quasi indistinguibili dalla casualità ideale ma che falliscono appena uno o più test statistici. Gli autori si concentrano su cinque test classici che osservano aspetti diversi dei pattern di bit, inclusa la frequenza di zeri e uni, il comportamento delle coppie di bit, la distribuzione di certi pattern brevi, la correlazione dei bit con copie shiftate di sé stessi e la disposizione delle lunghezze delle run di bit identici. Definiscono una “zona limite” per ciascun test: una fascia stretta in cui i dati violano solo leggermente le soglie di accettazione usuali. Produrre una lunga sequenza che cada contemporaneamente all’interno di tutte queste fasce strette è estremamente improbabile per caso, perché i test interagiscono in modi complicati e non lineari. Qui entrano in gioco ottimizzazione e IA.
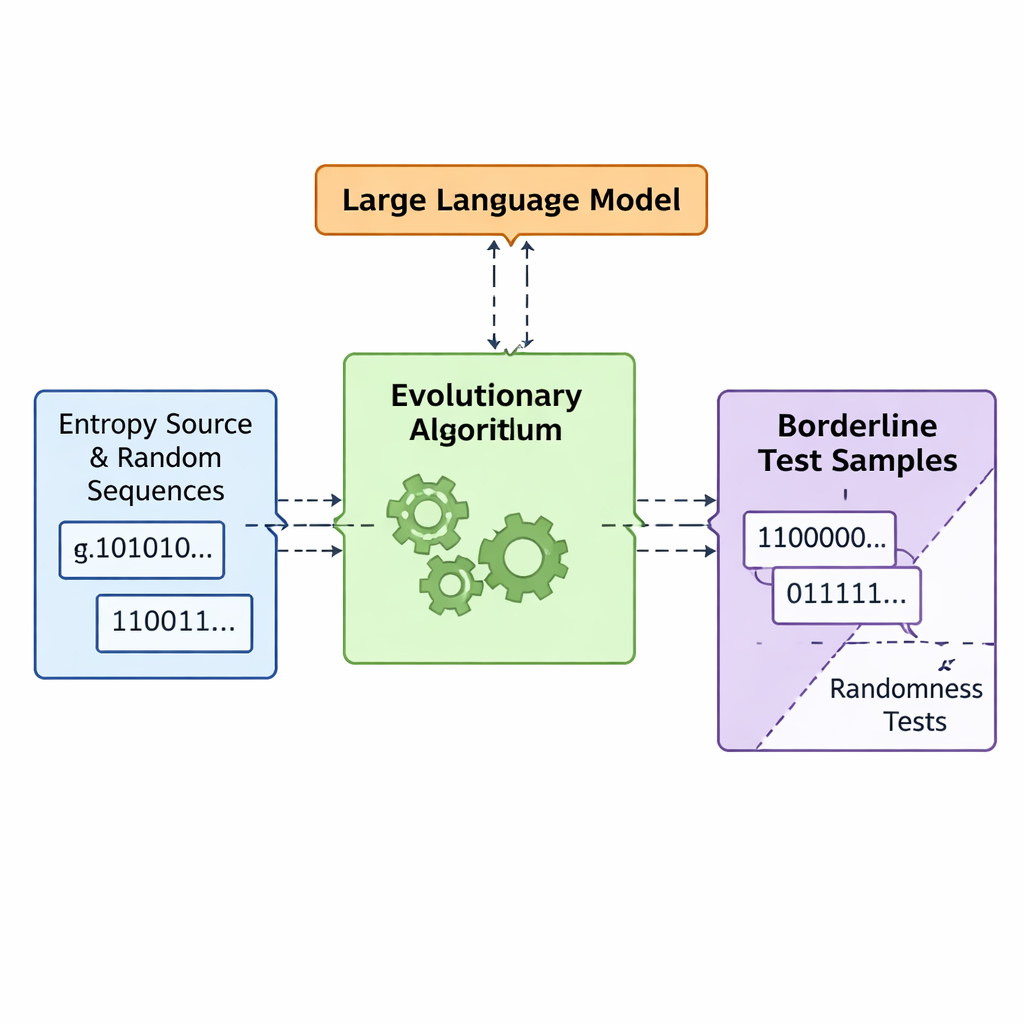
Lasciare che evoluzione e modelli di linguaggio co‑progettino cattiva casualità
Il team introduce un framework chiamato APAM‑IGLLM che tratta la generazione di sequenze come un problema di ottimizzazione ad alta dimensionalità. Ogni sequenza candidata è una stringa di bit e la sua “fitness” misura quanto si avvicina alle zone limite dei cinque test. Un algoritmo genetico muta e ricombina ripetutamente queste sequenze, mantenendo quelle che si avvicinano alla regione target. Su questo livello, un modello di linguaggio di grandi dimensioni (LLM) agisce come una sorta di allenatore strategico. Ad ogni generazione esamina statistiche riassuntive della popolazione e la storia a breve termine, poi suggerisce come regolare manopole interne—pesi e fattori di scala che decidono quanto ciascun test influenzi la fitness. Questo crea un ciclo di retroazione: l’algoritmo genetico esplora lo spazio delle possibili sequenze, mentre l’LLM dirige la ricerca in modo che i punteggi dei cinque test convergano verso la piccola intersezione in cui le sequenze sono appena non‑casuali.
Quanto possono apparire perfette dati difettosi?
Per verificare se i loro difetti artificiali sembrano realistici, gli autori confrontano le sequenze generate con benchmark ampiamente usati. Calcolano sia l’entropia di Shannon sia la min‑entropia, misure di quanto imprevedibile appare ogni byte, e trovano valori intorno a 7,6–8 bit per byte—molto vicini al massimo teorico di 8 e simili a fonti commerciali di casualità hardware e al beacon pubblico di casualità del NIST. Eseguono anche l’intera suite di test statistici NIST SP 800‑22 e osservano che le loro sequenze limite passano e falliscono quasi nello stesso schema dei dati casuali di alta qualità genuini. In altre parole, per gli strumenti standard questi campioni appaiono essenzialmente normali, anche se sono stati deliberatamente ingegnerizzati per trovarsi vicino a molteplici soglie di fallimento. Questo li rende input “avversariali” ideali per verificare quanto siano robusti i tester di casualità integrati.
Cosa significa questo per la sicurezza nel mondo reale
Dal punto di vista del pubblico, questo lavoro offre un nuovo modo per verificare la sicurezza delle macchine di generazione di numeri casuali che stanno alla base della crittografia. Invece di testare i dispositivi soltanto con casualità chiaramente rotta o chiaramente sana, gli ingegneri possono ora bombardare i sistemi con sequenze accuratamente costruite e quasi‑corrette che imitano sottili guasti hardware o deriva ambientale. Se un tester di casualità in tempo reale manca questi casi limite, ciò segnala un potenziale punto cieco che dovrebbe essere corretto prima che il dispositivo sia distribuito in ambiti bancari, comunicazioni sicure o sistemi blockchain. Utilizzando una ricerca evolutiva guidata da un modello di linguaggio, gli autori forniscono uno strumento pratico per generare tali dati di test esigenti, contribuendo a spingere le fondamenta nascoste della sicurezza digitale verso livelli più elevati di affidabilità.
Citazione: Gao, P., Zhang, B., Wang, Z. et al. Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms. Sci Rep 16, 7268 (2026). https://doi.org/10.1038/s41598-026-38020-w
Parole chiave: generatori di numeri casuali, fonti di entropia, algoritmi evolutivi, modelli di linguaggio di grandi dimensioni, test crittografici