Clear Sky Science · it
Impilamento verticale dei container basato su Fuzzy C-means nei terminal container
Perché un impilamento più intelligente dei container è importante
Ogni anno quasi un miliardo di scatole metalliche standardizzate—i container—transitano per i porti marittimi di tutto il mondo. Far salire e scendere quelle scatole dalle navi rapidamente è essenziale per mantenere il flusso delle merci e contenere i costi. Eppure un problema sorprendentemente semplice rallenta le operazioni: quando il container necessario è sepolto sotto altri sbagliati, le gru devono rimescolare la pila, sprecando tempo e carburante. Questo articolo esplora un nuovo approccio guidato dai dati per impilare i container in base al peso che riduce queste costose riorganizzazioni, rendendo i porti più rapidi e affidabili senza richiedere più spazio o attrezzature.
Il problema nascosto delle pile disordinate
I piazzali container appaiono ordinati da lontano, ma la sequenza in cui i container devono essere caricati e scaricati è altamente incerta. I container in partenza arrivano al terminal prima della nave e il loro ordine di carico effettivo è influenzato dalle regole di stabilità della nave e da piani di stivaggio che cambiano. I container più pesanti vanno normalmente più in basso nella stiva, quelli più leggeri più in alto. Tuttavia, quando i container arrivano, gli operatori spesso non sanno se una certa cassa sarà considerata “pesante” o “leggera” rispetto al carico finale. Le strategie tradizionali cercano di dare priorità ai container pesanti o di assegnare categorie di peso fisse, ma questo può ritorcersi contro: un container classificato come pesante oggi potrebbe essere considerato medio il giorno dopo, costringendo a rimescolamenti extra al momento del carico della nave.
Impilamenti verticali e perché l’equilibrio dei pesi conta
I porti utilizzano diversi modi di disporre i container: affiancati in file (orizzontale), impilati per tipologia in colonne (verticale), o un ibrido di entrambi. Questo studio si concentra sull’impilamento verticale, dove container con caratteristiche simili sono posti nella stessa pila a colonna. L’impilamento verticale è interessante perché facilita l’accesso a un container di peso approssimativo adeguato senza disturbare troppi altri. Ma nella realtà il numero di container in ciascuna fascia di peso cambia da viaggio a viaggio. Se i gruppi di peso sono definiti usando soglie rigide—per esempio ogni 5 tonnellate—molti container vicini ai confini finiscono in pile diverse pur essendo di peso quasi identico. Ciò aumenta la variazione di peso all’interno delle pile e riduce i benefici dell’impilamento verticale.
Lasciare che siano i dati a tracciare i confini
Gli autori propongono una nuova strategia chiamata Fuzzy C-means-based Vertical Sequence Stacking, o FVSS. Invece di decidere a priori i limiti di ciascun gruppo di peso, il metodo esamina i dati storici dei pesi delle navi sulla stessa tratta e lascia che un algoritmo di clustering fuzzy trovi i gruppi naturali. “Fuzzy” qui significa che il peso di un container può appartenere in parte a più gruppi, riflettendo il fatto che non esiste un confine netto tra, per esempio, medio e pesante. L’algoritmo sceglie quante cluster sono ottimali per i dati storici di ciascuna nave e identifica un centro di peso per ogni cluster. Il piazzale viene quindi pre-diviso in un numero di pile proporzionale a quanti container tipicamente ricadono in ciascun gruppo di peso, e a ogni pila viene assegnato un peso di riferimento basato su quei centri.
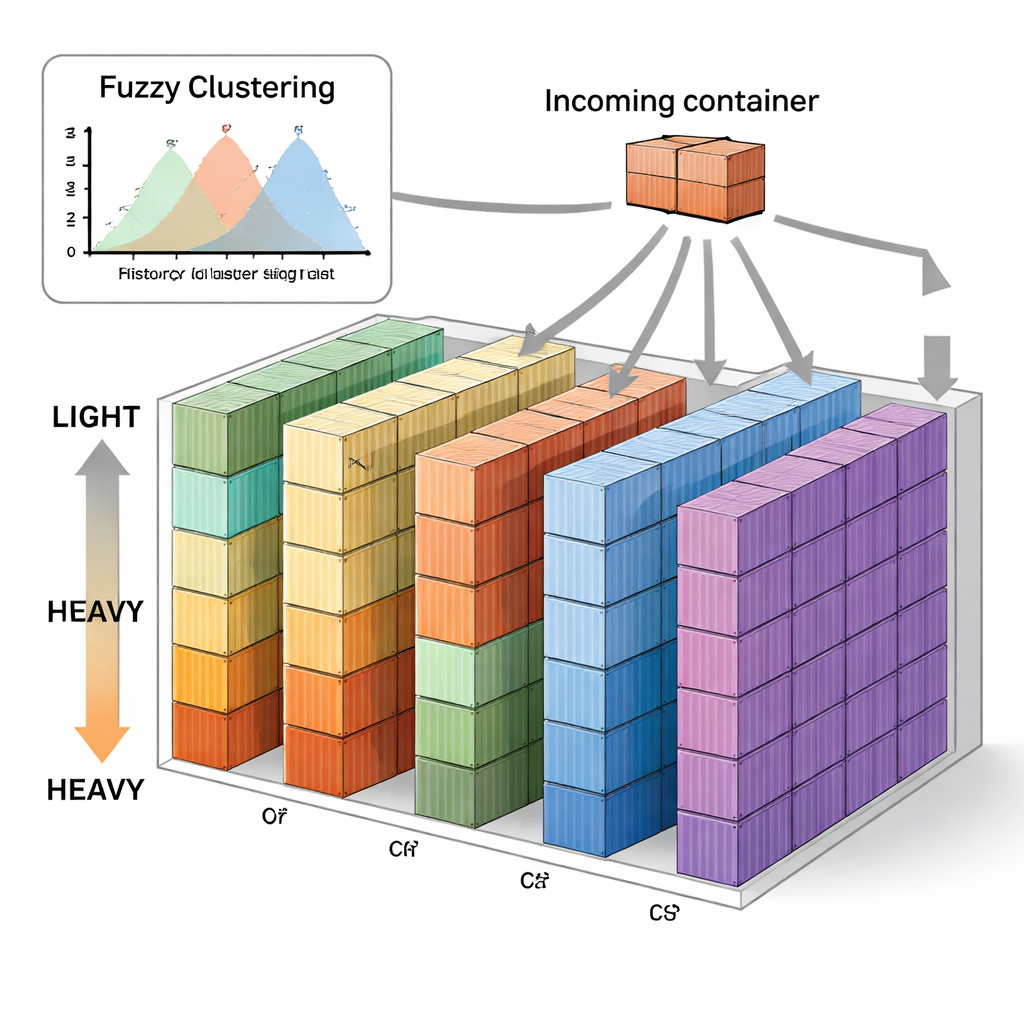
Regole semplici per decisioni in tempo reale
Una volta che il piazzale è configurato in questo modo, le operazioni quotidiane seguono una regola semplice. Man mano che ogni container arriva, la sua classe di peso approssimativa viene determinata usando i cluster fuzzy. Se c’è spazio libero nelle pile riservate a quella classe, il container va lì. Se quelle pile sono piene o sono disponibili più opzioni, il sistema sceglie la pila il cui peso di riferimento è più vicino al peso effettivo del container. Nel tempo, questo indirizza gradualmente container di peso simile verso le stesse pile senza ottimizzazioni complesse o addestramento continuo di machine learning. Gli autori hanno testato questo approccio su dieci mesi di dati reali dal Busan Container Terminal in Corea, confrontandolo con diversi metodi noti, inclusi impilamento casuale, una strategia ibrida orizzontale–verticale e tecniche precedenti basate su modelli di miscela gaussiana e apprendimento online.
Cosa significano i risultati per i porti
La misura chiave nello studio è quanto variano i pesi dei container all’interno di ciascuna pila—una dispersione minore significa che è più facile trovare container adatti durante il carico della nave con meno rimescolamenti. Su più navi e due configurazioni di piazzale (5 e 10 pile), la strategia FVSS ha ridotto la varianza dei pesi molto più dei metodi concorrenti, con miglioramenti fino al 78% rispetto all’impilamento casuale e guadagni sostanziali rispetto ad altri metodi avanzati. Elemento cruciale, le prestazioni sono rimaste solide anche quando i ricercatori hanno deliberatamente alterato i pesi dei container per imitare errori e cambi dell’ultimo minuto. Per gli operatori portuali, questo significa ottenere operazioni delle gru più fluide e tempi di sosta delle navi più brevi affidandosi a un insieme di regole automatizzato ma trasparente, facile da aggiornare man mano che nuovi viaggi si completano, senza investire in infrastrutture di calcolo pesanti o complessi sistemi di apprendimento.
Citazione: Lee, S., Lee, SH., Choi, S.C. et al. Fuzzy C-means clustering based vertical container stacking in container terminals. Sci Rep 16, 6891 (2026). https://doi.org/10.1038/s41598-026-37994-x
Parole chiave: terminal container, impilamento nel piazzale, clustering fuzzy, logistica marittima, efficienza operativa