Clear Sky Science · it
Correggere le etichette rumorose tramite distillazione comparativa: un approccio di adattamento del dominio
Perché i dati disordinati sono un problema in crescita
L’intelligenza artificiale moderna prospera sui dati, ma quei dati sono spesso errati, incompleti o etichettati in modo incoerente. Quando le etichette sono rumorose — per esempio una foto di un gatto etichettata come cane — i sistemi di apprendimento possono essere fuorviati, diventando meno precisi e meno affidabili. Questo articolo affronta quel problema reale: come addestrare sistemi di riconoscimento delle immagini che funzionino bene anche quando le etichette di training sono imperfette e le immagini provengono da ambienti diversi, come negozi online rispetto a foto del mondo reale.
Apprendere attraverso mondi diversi
In pratica, i modelli di IA spesso imparano da un mondo “sorgente” dove le etichette sono controllate accuratamente, e poi devono operare in un mondo “target” dove le etichette sono scarse e soggette a errori. Per esempio, oggetti d’ufficio fotografati in studio sono ordinati e correttamente etichettati, mentre foto da webcam o quotidiane degli stessi oggetti sono disordinate e taggate in modo incoerente. I metodi tradizionali di adattamento del dominio cercano di colmare questo divario allineando le statistiche complessive dei due mondi. Tuttavia, di solito assumono che le etichette target, quando disponibili, siano corrette — un’ipotesi rischiosa che viene meno in applicazioni reali con tag crowd‑sourced, sensori di bassa qualità o strumenti di annotazione automatici.
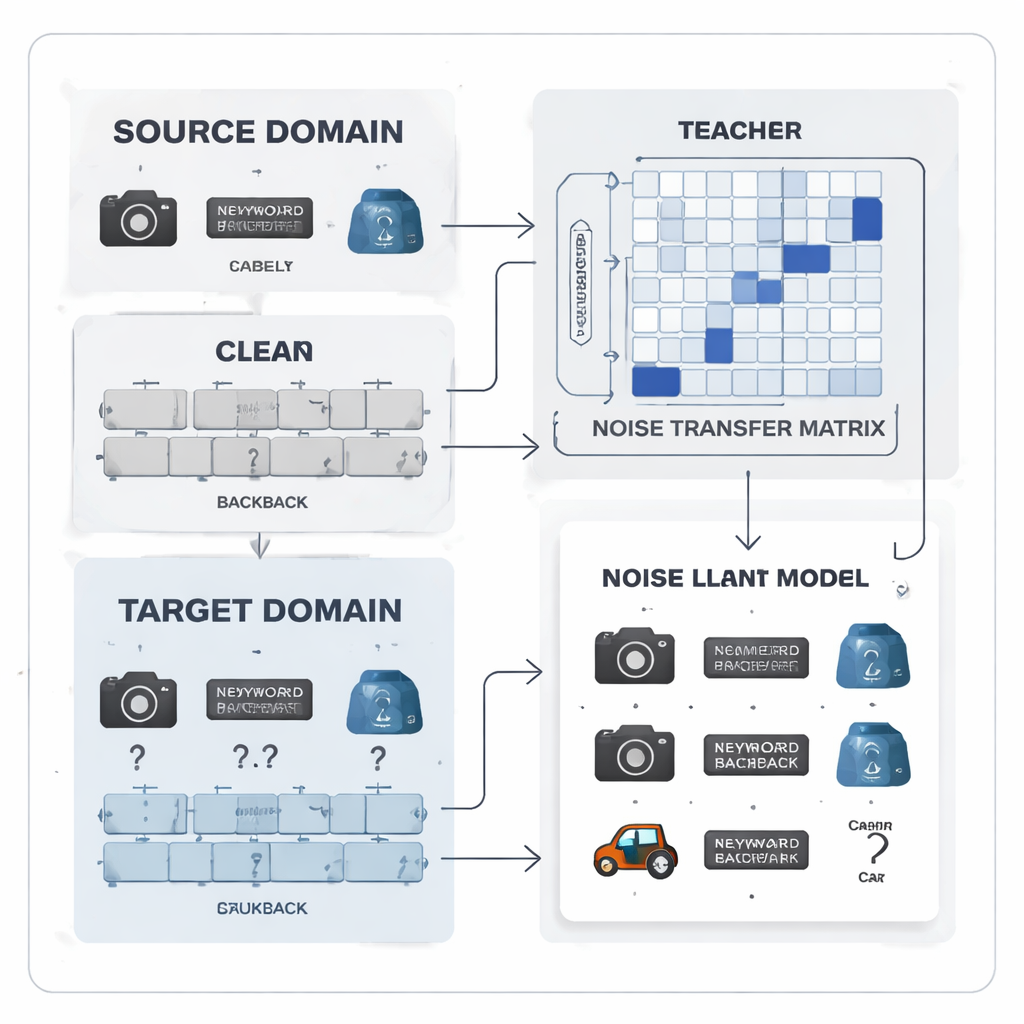
Trasformare gli errori di etichettatura in uno schema apprendibile
Gli autori propongono di trattare il rumore nelle etichette non come caos casuale ma come uno schema apprendibile. Introducono una “matrice di trasferimento del rumore”, una tabella che cattura quanto sia probabile che ogni classe reale venga etichettata erroneamente come un’altra. Invece di stimare questa matrice da pochi esempi perfetti “ancora” — cosa irrealistica quando le etichette sono rumorose e le classi sbilanciate — la matrice viene appresa direttamente durante l’addestramento. Per avviare l’apprendimento, il metodo costruisce “prototipi” di categoria, impronte medie delle feature per ciascuna classe estratte da un solido modello pre‑addestrato. La similarità tra questi prototipi viene usata per inizializzare la matrice in modo che categorie confondibili, come strumenti d’ufficio simili, siano più fortemente collegate fin dall’inizio, dando al sistema una capacità iniziale di correggere le etichette.
Lavoro di squadra insegnante–studente per segnali più puliti
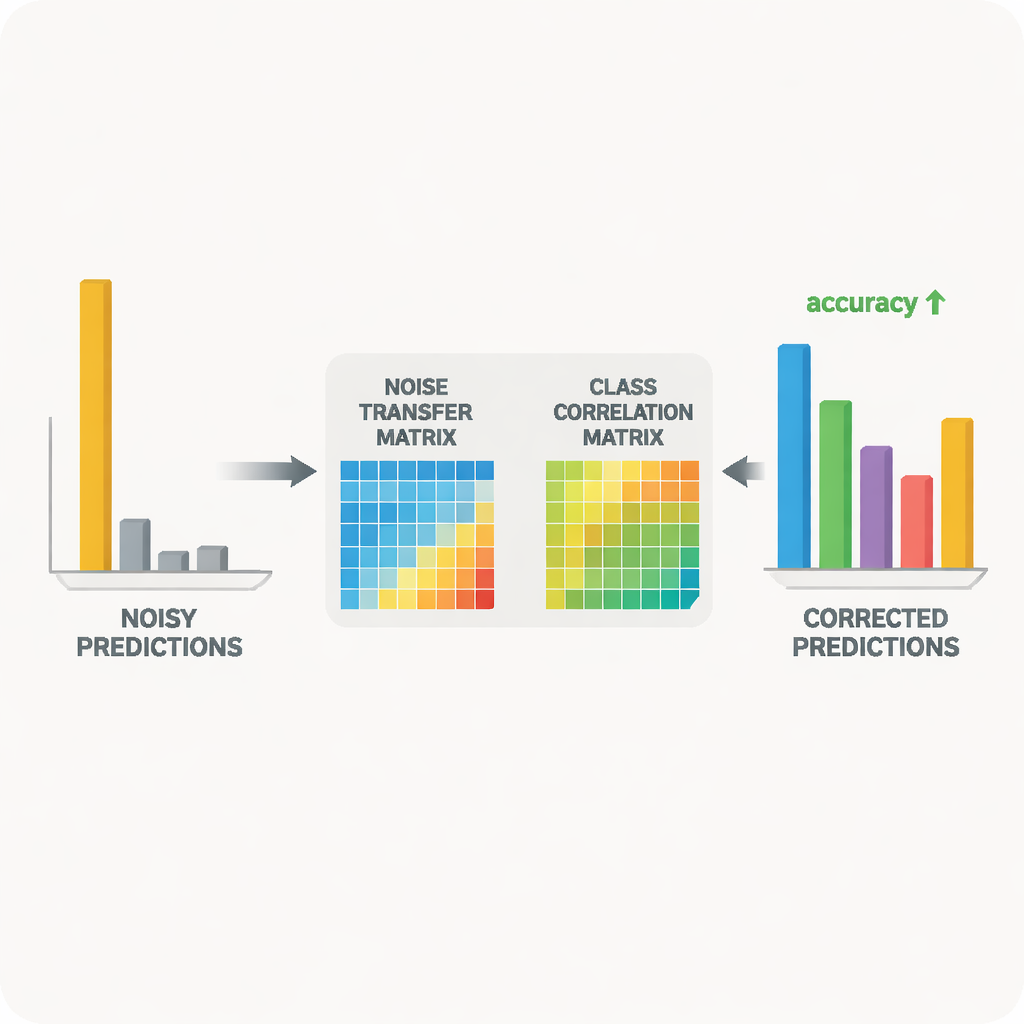
Al cuore del sistema c’è una coppia insegnante–studente di reti neurali. L’insegnante si basa su un grande modello visivo autodidatta che ha appreso ricche feature visive da enormi quantità di dati non etichettati. Lo studente è una rete più leggera che deve funzionare bene sui dati target rumorosi. L’insegnante produce punteggi di previsione "soft" che rivelano quanto le diverse classi siano correlate; da questi punteggi il metodo costruisce una matrice di correlazione delle classi che riassume quali etichette tendono a co‑occuparsi. Questa matrice funge da guida, spingendo la matrice di trasferimento del rumore verso correzioni più realistiche. Allo stesso tempo, lo studente viene addestrato a imitare il comportamento dell’insegnante tramite un processo noto come distillazione, mentre l’apprendimento contrastivo incoraggia entrambe le reti a fornire rappresentazioni interne simili per diverse viste aumentate della stessa immagine e rappresentazioni distinte per oggetti diversi.
Mantenere le correzioni stabili ed evitare eccessiva certezza
Consentire alla matrice di trasferimento del rumore di variare liberamente potrebbe renderla instabile o eccessivamente sensibile agli outlier. Per evitarlo, gli autori usano un trucco matematico basato sulla decomposizione ai valori singolari, che scompone la matrice in direzioni fondamentali di deformazione. Penalizzando il “volume” complessivo implicito in queste direzioni, il metodo scoraggia distorsioni estreme che amplificherebbero il rumore. Un altro problema si presenta quando il modello diventa troppo sicuro di sé, assegnando quasi tutta la probabilità a una singola classe; con previsioni così affilate diventa difficile correggere etichette errate. Per affrontare questo, il metodo aggiunge una forma di regolarizzazione dell’entropia, basata sull’entropia di Tsallis, che mantiene le probabilità di previsione più morbide. Questo rende più semplice per la matrice di trasferimento del rumore riallocare parzialmente massa di probabilità da una classe scorretta a alternative più plausibili.
Dimostrare l’idea su collezioni reali di immagini
I ricercatori hanno testato il loro approccio su due benchmark ampiamente usati per il riconoscimento di oggetti cross‑domain: Office‑31 e Office‑Home, che includono immagini di oggetti d’ufficio quotidiani in più stili come foto di prodotto, clip art e scatti del mondo reale. In una varietà di compiti “addestra su uno stile, testa su un altro”, il loro metodo ha eguagliato o superato algoritmi di punta, specialmente nei casi più difficili in cui lo shift tra domini è maggiore. Studi dettagliati hanno mostrato che ciascun componente — il controllo del volume per la matrice del rumore, la guida della correlazione di classe e la levigatura tramite entropia — ha contribuito con guadagni misurabili. Visualizzazioni della matrice appresa e dello spazio delle feature hanno confermato che, durante l’addestramento, gli esempi etichettati erroneamente sono stati gradualmente riavvicinati alle loro categorie corrette e che le distribuzioni di immagini sorgente e target sono diventate meglio allineate.
Cosa significa questo per i sistemi di IA di tutti i giorni
Per un non specialista, il messaggio chiave è che questo lavoro rende i modelli di IA più tolleranti agli errori umani e meccanici nella etichettatura dei dati, in particolare quando quei modelli devono passare da condizioni di laboratorio pulite a ambienti reali più disordinati. Imparando esplicitamente come le etichette tendono a sbagliare e usando un potente modello insegnante per guidare le correzioni, il metodo può ripulire i segnali di training rumorosi e produrre classificatori più accurati e robusti. Sebbene l’approccio richieda calcolo aggiuntivo, indica una direzione in cui grandi dataset imperfetti raccolti “in natura” possono essere sfruttati in modo più sicuro ed efficace, riducendo la nostra dipendenza da un’accurata annotazione manuale.
Citazione: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
Parole chiave: etichette rumorose, adattamento del dominio, distillazione della conoscenza, classificazione di immagini, apprendimento semi-supervisionato