Clear Sky Science · it
Critici distributivi doppi sensibili al rischio con un bound di confidenza inferiore lambda per l'apprendimento per rinforzo nel controllo continuo
Insegnare ai robot a essere cauti
Molti dei robot e dei programmi di gioco più impressionanti di oggi si basano sull'apprendimento per rinforzo, un processo di addestramento per tentativi ed errori in cui gli agenti software imparano raccogliendo ricompense. Ma questi agenti spesso inseguono il punteggio più alto possibile ignorando quanto siano rischiose le loro decisioni, il che porta a un apprendimento instabile e ad occasionali incidenti. Questo articolo presenta un metodo chiamato TDC-λ (Twin Distributional Critics with a Lambda Lower Confidence Bound) che insegna a tali agenti non solo a puntare in alto, ma anche a restare affidabilmente al sicuro durante l'apprendimento.
Perché la stabilità conta nelle macchine che apprendono
Gli algoritmi standard per il controllo continuo, come i largamente usati TD3 e Soft Actor–Critic (SAC), hanno permesso ai robot di correre, saltare e mantenere l'equilibrio in simulatori complessi. Tuttavia, questi metodi tipicamente giudicano ogni azione usando un unico numero: una stima di quanta ricompensa porterà a lungo termine. Quel punteggio semplice può essere fuorviante quando il processo di apprendimento è rumoroso, inducendo il sistema a sovrastimare quanto siano buone alcune azioni. Il risultato è una curva di apprendimento che può apparire forte in media ma oscillare violentemente tra le diverse esecuzioni, un problema se lo stesso algoritmo deve controllare macchine fisiche o sistemi critici per la sicurezza.
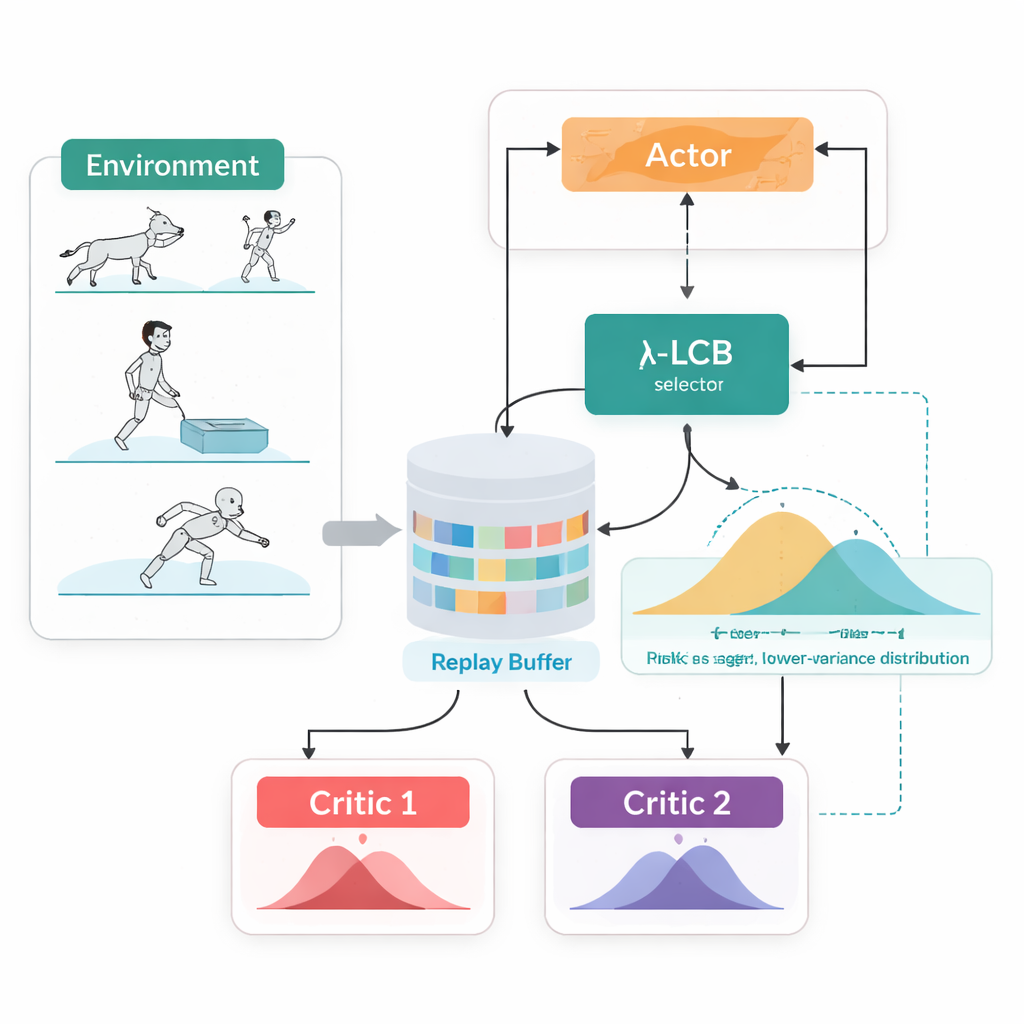
Considerare interi futuri, non singoli numeri
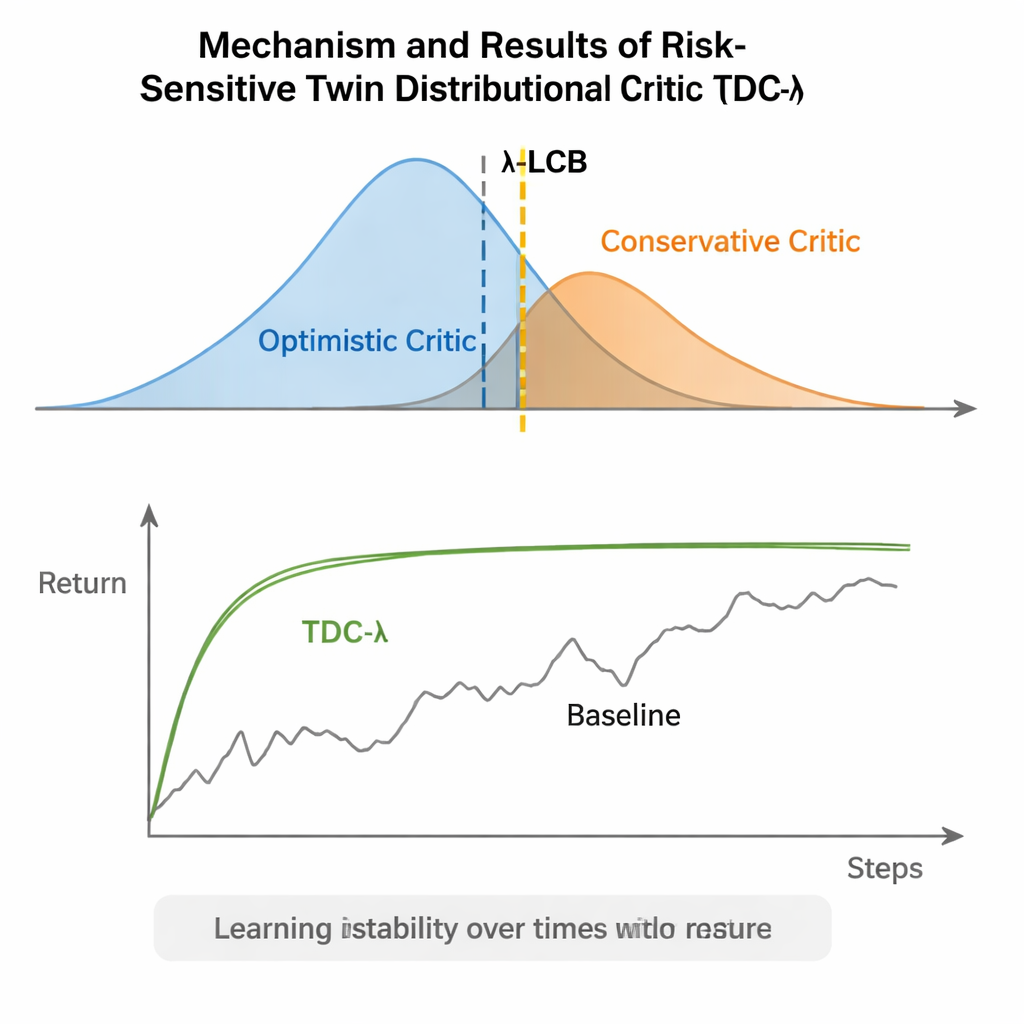
TDC-λ affronta questo problema cambiando il modo in cui l'agente valuta il proprio futuro. Invece di prevedere una sola ricompensa attesa per ogni azione, impara due "critici" separati che ciascuno restituisce un'intera distribuzione sulle possibili ricompense future. Da queste distribuzioni, l'algoritmo calcola non solo l'esito medio ma anche quanto siano disperse le possibilità. Questa dispersione riflette incertezza o rischio. Usando una regola semplice, riassunta come bound di confidenza inferiore, TDC-λ preferisce il critico che prevede un esito più sicuro: uno che può essere leggermente meno ottimista ma è supportato da prove più coerenti. Una singola impostazione, il parametro di rischio λ, regola in modo continuo quanto sia cauta questa selezione — da un comportamento simile a un metodo TD3 convenzionale quando λ è zero fino a diventare più conservativa al crescere di λ.
Un ciclo di addestramento, due modi di agire
Un altro aspetto pratico di TDC-λ è che supporta sia modalità deterministiche sia stocastiche di scelta delle azioni all'interno di un unico framework unificato. Durante l'addestramento, si può optare per una politica deterministica classica o per una politica gaussiana "tanh-squashed" che campiona azioni, favorendo l'esplorazione. Indipendentemente da questa scelta, i critici distributivi doppi vengono addestrati nello stesso modo e la valutazione utilizza sempre l'azione media deterministica. Questo design sfrutta risultati precedenti secondo cui il comportamento deterministico al test spesso rende quanto meno quanto il campionamento, permettendo al contempo politiche ricche e favorevoli all'esplorazione durante l'apprendimento.
Mettere il metodo alla prova
Gli autori hanno valutato TDC-λ su cinque popolari task benchmark MuJoCo in cui robot simulati come HalfCheetah, Hopper, Ant, Walker2d e Humanoid devono imparare a muoversi in modo efficiente. In questi task, il nuovo metodo ha eguagliato o migliorato la performance finale di solidi baseline come TD3, DDPG, SAC e un avanzato approccio basato sui flussi chiamato MEOW, mostrando costantemente una variabilità inferiore tra le esecuzioni ripetute. Nei compiti più difficili e ad alta dimensionalità, come Humanoid, valori di λ leggermente più elevati — cioè stime del bersaglio più caute — hanno portato ai migliori ritorni a lungo termine e alle bande di performance più strette. Esperimenti aggiuntivi in altri simulatori (PyBullet e NVIDIA Isaac) e diagnostiche che tracciano la variabilità del segnale di apprendimento hanno rafforzato la conclusione che TDC-λ rende l'apprendimento più stabile senza rallentarlo.
Una manopola semplice per un apprendimento più sicuro
In termini pratici, TDC-λ dà ai sistemi di apprendimento per rinforzo un "margine di sicurezza" quando decidono quanto fidarsi del proprio ottimismo. Imparando distribuzioni complete dei possibili esiti e poi inclinandosi verso il critico più sicuro tramite la manopola λ, l'algoritmo riduce le oscillazioni violente durante l'addestramento preservando un'elevata performance finale. Per i praticanti, questo offre un modo pratico per costruire controllori più affidabili per robot e altri sistemi di controllo continuo: iniziare con un λ moderatamente conservativo e regolarlo in base a quanto volatile appare il processo di apprendimento. Il messaggio più ampio è che modellare con cura da cosa l'agente impara — i suoi bersagli di addestramento — può fornire gran parte della robustezza spesso attribuita ad architetture più complesse, rendendo l'apprendimento per rinforzo avanzato sia più stabile sia più accessibile.
Citazione: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
Parole chiave: apprendimento per rinforzo, controllo continuo, apprendimento sensibile al rischio, critici distributivi, robotica