Clear Sky Science · it
Modello di previsione della qualità dell'aria basato su un framework ibrido di deep learning
Perché previsioni dell'aria più pulita contano per te
Quando lo smog avvolge una città, le persone devono prendere decisioni pratiche: è sicuro fare jogging all'aperto, mandare i bambini a scuola o mantenere aperte le fabbriche? Quelle decisioni dipendono da quanto bene riusciamo a prevedere le piccole particelle inquinanti chiamate PM2.5, abbastanza piccole da raggiungere le profondità dei polmoni. Questo studio presenta un nuovo modello informatico che sfrutta i recenti progressi dell'intelligenza artificiale per prevedere i livelli di PM2.5 nelle città cinesi con maggiore precisione e più rapidamente rispetto a molti strumenti esistenti, fornendo potenzialmente al pubblico e ai decisori avvisi prima e più affidabili.
Dai cieli fumosi ai dati intelligenti
L'inquinamento atmosferico è diventato una minaccia sanitaria persistente in molte aree urbane, soprattutto nel nord della Cina, dove alti livelli di PM2.5 sono associati a malattie respiratorie e cardiovascolari. Le città ora gestiscono fitti network di stazioni di monitoraggio che registrano ogni ora PM2.5, altri inquinanti e le condizioni meteorologiche locali. I metodi tradizionali di previsione si basano su matematica semplificata o modelli fisici artigianali, che faticano a gestire la realtà disordinata e non lineare di venti turbolenti, variazioni di temperatura e attività umane. Invece, il nuovo approccio, chiamato CBLA, lascia che i dati “parlino da soli” addestrando reti neurali moderne su diversi anni di osservazioni provenienti da Pechino e Guangzhou.
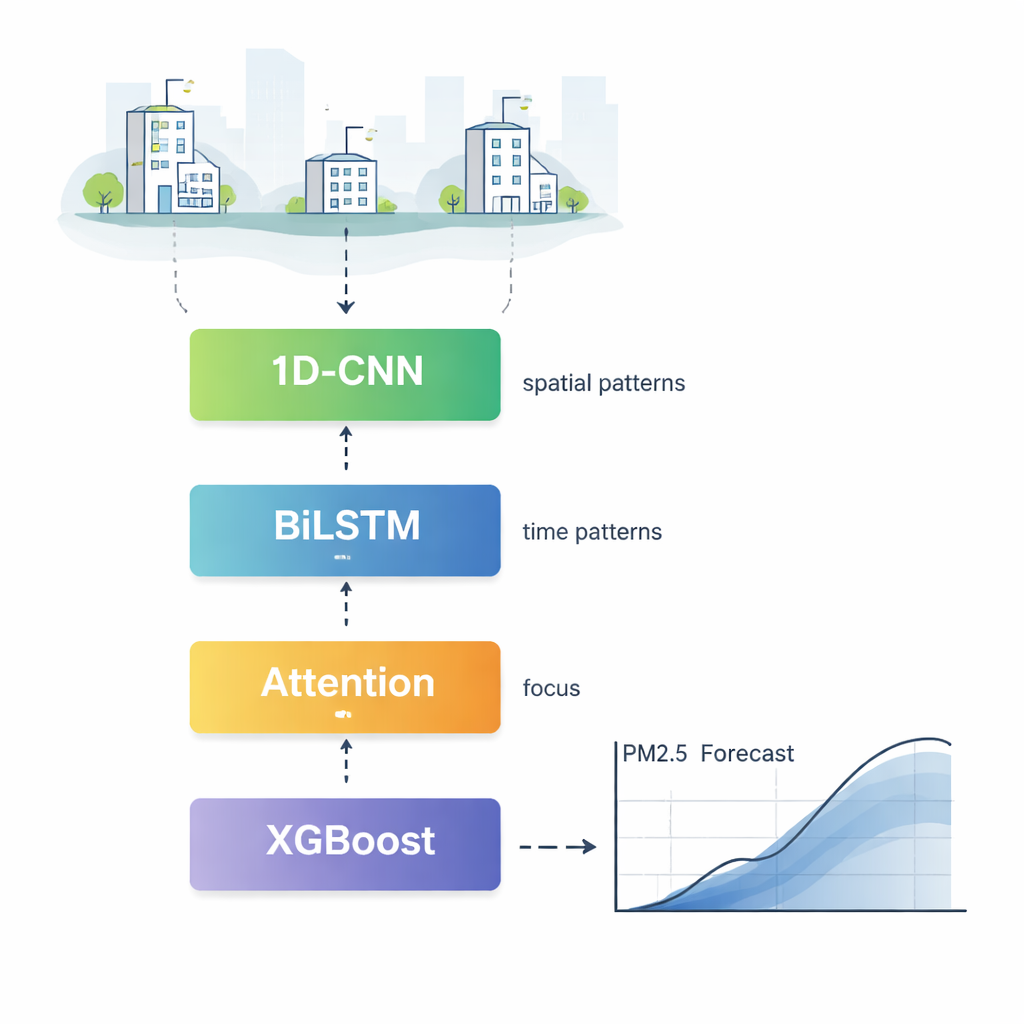
Come funziona il nuovo motore di previsione
CBLA agisce come una squadra stratificata di specialisti che analizzano i dati di inquinamento da prospettive diverse prima di votare su una previsione finale. Per prima cosa, un componente noto come rete convoluzionale monodimensionale scansiona le misure di molte stazioni di monitoraggio per individuare schemi che si ripetono nello spazio, ad esempio come il fumo tende a propagarsi da un quartiere all'altro. Poi, una rete a memoria bidirezionale legge le serie temporali dell'inquinamento avanti e indietro nel tempo, apprendendo come i livelli di oggi dipendano sia dalle condizioni recenti sia da quelle un po' più vecchie. Un meccanismo di attenzione mette quindi in evidenza le ore e le caratteristiche più influenti, permettendo al modello di concentrarsi maggiormente, per esempio, sullo spike netto di ieri o sui forti venti piuttosto che su letture più lontane e meno rilevanti.
Aggiungere la meteorologia per affinare il quadro
L'inquinamento non si muove in isolamento; si sposta insieme al tempo atmosferico. Per integrare queste informazioni in modo efficace, gli autori aggiungono una seconda fase che alimenta sia la previsione preliminare della rete neurale sia i dati meteorologici dettagliati — come velocità del vento, umidità e temperatura — in un potente algoritmo a base di alberi chiamato XGBoost. Questa fase si comporta come un esperto previsore che verifica la stima iniziale alla luce del meteo attuale, correggendo la previsione verso l'alto o verso il basso. I test mostrano che questa combinazione riduce gli errori tipici di previsione e migliora l'adesione dell'output del modello ai valori misurati realmente sul campo, specialmente durante improvvisi accumuli di inquinamento e fasi di dispersione.
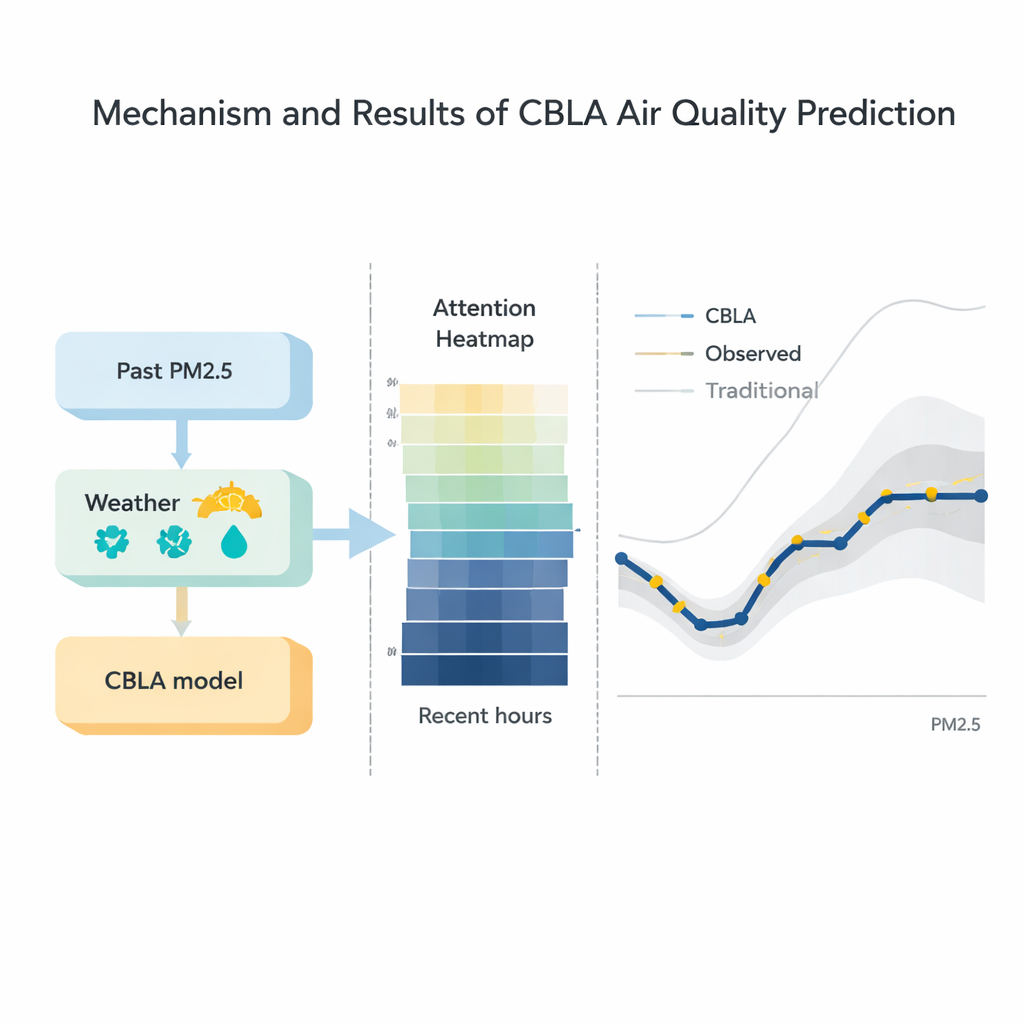
Test confrontati con modelli concorrenti
I ricercatori hanno confrontato CBLA con un'ampia gamma di alternative, dalle tecniche classiche come regressione e modelli ARIMA per serie temporali a ibridi di deep learning sofisticati che combinano reti a grafo e trasformatori. Su tre dataset reali, CBLA ha prodotto costantemente l'errore medio più basso e la migliore corrispondenza ai livelli osservati di PM2.5. È importante che abbia raggiunto un'accuratezza paragonabile ad alcuni dei modelli moderni più avanzati richiedendo solo circa un terzo del loro tempo di addestramento su hardware standard. Le visualizzazioni del meccanismo di attenzione hanno rivelato che il modello assegna naturalmente il peso maggiore alle poche ore più recenti di dati e a fattori fisicamente significativi come la velocità del vento e i livelli passati di PM2.5, offrendo una finestra su come le sue decisioni si allineino con l'intuizione meteorologica.
Cosa significa per la vita quotidiana
In termini pratici, lo studio dimostra che combinare con cura più tecniche di IA può produrre uno strumento di previsione dell'inquinamento non solo più accurato ma anche più rapido e più facile da interpretare. I gestori urbani potrebbero usare un tale modello per attivare avvisi sanitari, regolare restrizioni al traffico o ridurre preventivamente l'attività industriale ore prima dei picchi di smog pericolosi. Per i cittadini, previsioni migliori significano indicazioni più chiare su quando indossare mascherine, usare purificatori d'aria o tenere i bambini in casa. Pur essendo il lavoro focalizzato sulle città cinesi e sul PM2.5, lo stesso framework potrebbe essere adattato ad altre regioni e inquinanti, indicando un futuro in cui previsioni guidate dai dati aiutano milioni di persone a respirare un po' più facilmente.
Citazione: Yin, C., Li, W., Li, T. et al. Air quality prediction model based on deep learning hybrid framework. Sci Rep 16, 7084 (2026). https://doi.org/10.1038/s41598-026-37896-y
Parole chiave: previsione della qualità dell'aria, PM2.5, deep learning, inquinamento urbano, meteorologia