Clear Sky Science · it
Predizione sostenibile e interpretabile delle malattie cardiache: un approccio di supporto decisionale clinico per applicazioni biomediche
Perché controlli cardiaci più intelligenti contano
Le malattie cardiache sono la principale causa di morte al mondo, eppure molte persone scoprono di essere a rischio solo dopo un evento grave come un infarto. I medici raccolgono già misure semplici—come età, pressione sanguigna, colesterolo e risultati di test di base—ma trasformare queste informazioni in una risposta rapida e affidabile sul rischio di malattia cardiaca è una sfida. Questo studio esplora un nuovo tipo di modello informatico che può apprendere da quei numeri di routine, prevedere con elevata accuratezza chi è probabile abbia una malattia cardiaca e, cosa cruciale, spiegare il proprio ragionamento in termini comprensibili ai medici.
Il peso crescente delle malattie cardiache
Ogni anno le malattie cardiovascolari causano circa 18 milioni di decessi nel mondo. Molte di queste morti potrebbero essere prevenute se i pazienti ad alto rischio fossero identificati prima e trattati tempestivamente. I test diagnostici tradizionali possono essere invasivi, costosi o non sufficientemente accurati nei casi borderline. Parallelamente, gli ospedali oggi archiviano grandi quantità di dati digitali sui pazienti, dall’età e il sesso fino alla pressione sanguigna, al colesterolo e ai risultati di test cardiaci di base. Trasformare questo flusso di informazioni in stime di rischio chiare e affidabili è diventata una delle più grandi opportunità—e delle maggiori sfide—della medicina moderna.
Dalle scatole nere ad assistenti trasparenti
Negli ultimi anni l’intelligenza artificiale ha mostrato promettenti capacità nello scovare pattern sottili nei dati medici che potrebbero sfuggire all’occhio umano. Tuttavia, molti modelli potenti si comportano come «scatole nere»: possono essere accurati, ma non spiegano facilmente perché hanno preso una certa decisione. Questa mancanza di trasparenza è un problema in medicina, dove i medici devono giustificare diagnosi e scelte terapeutiche. Gli autori colmano questo divario progettando un sistema di predizione della malattia cardiaca basato su una rete neurale convoluzionale unidimensionale (1D CNN). Diversamente dai metodi più vecchi che richiedono agli esperti di definire manualmente le caratteristiche da analizzare, questa rete scopre automaticamente pattern utili nelle misure standard dei pazienti, pur essendo progettata per essere sufficientemente efficiente da funzionare in cliniche con risorse di calcolo limitate.
Come il modello impara dai controlli di routine
I ricercatori hanno addestrato il sistema su un dataset di malattia cardiaca ampiamente usato contenente 303 cartelle cliniche, ciascuna con 14 elementi comunemente raccolti come età, sesso, pressione sanguigna, livello di colesterolo, tipo di dolore toracico e risultati di test cardiaci di base. Hanno preparato accuratamente i dati: i valori numerici sono stati standardizzati in modo che nessuna singola misura dominasse il processo di apprendimento, e categorie come il tipo di dolore toracico sono state convertite in forma numerica. Per sfruttare al meglio il dataset relativamente piccolo e per ricreare il rumore naturale delle misure cliniche reali, il team ha aggiunto una piccola quantità di variazione casuale ai dati di addestramento. Hanno quindi alimentato questi record in un’architettura compatta di 1D CNN con due principali strati di rilevamento dei pattern, seguiti da strati che combinano tali pattern in una previsione finale di «malattia» o «assenza di malattia».
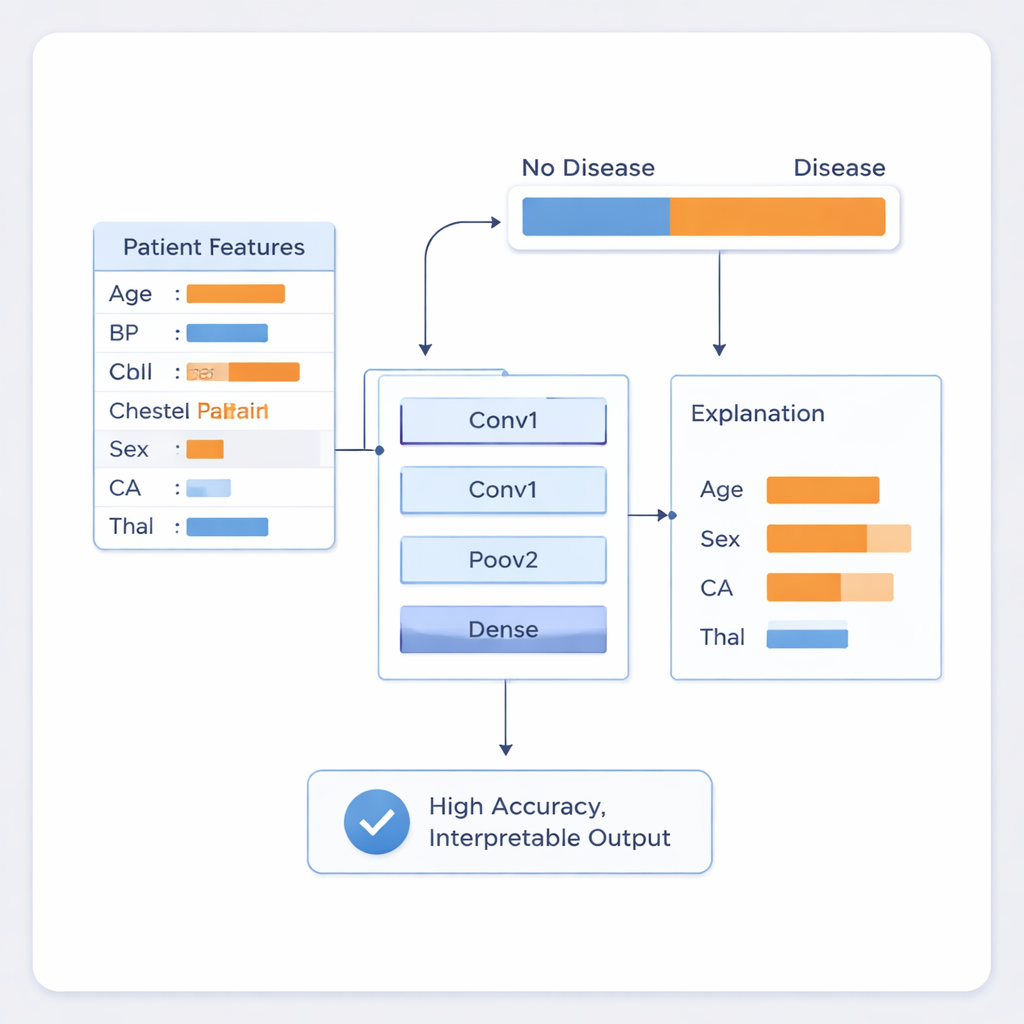
Trasformare i numeri in spiegazioni affidabili
La prestazione da sola non basta in un contesto clinico, quindi gli autori hanno affiancato al loro modello due tecniche di spiegazione note come LIME e SHAP. Questi metodi sondano la rete addestrata per stimare quanto ciascun fattore di input spinga la previsione verso «malattia» o «assenza di malattia» per un singolo paziente. In pratica, ciò significa che il sistema può dire al medico non solo che un paziente è ad alto rischio, ma anche che, per esempio, il risultato è guidato principalmente da una combinazione di sesso, numero di vasi ristretti e una condizione ematica chiamata talassemia. Le caratteristiche evidenziate corrispondono alla conoscenza medica consolidata sul rischio di malattia cardiaca, il che aiuta i clinici a giudicare quando fidarsi del modello e quando invece metterlo in discussione.
Risultati che potrebbero arrivare nelle cliniche di tutti i giorni
Sui dati di test mai visti prima, il modello ha classificato correttamente lo stato di malattia cardiaca in circa 98 pazienti su 100, ha raggiunto precisione perfetta nell’etichettare i casi di malattia (non ha prodotto falsi allarmi in questo campione) e ha mostrato una capacità quasi perfetta di separare cuori malati da cuori sani nel complesso. Altrettanto importante, il sistema è risultato leggero: si è addestrato in pochi minuti su hardware cloud standard e ha prodotto risposte in una frazione di secondo, suggerendo che potrebbe funzionare su normali computer ospedalieri anziché su supercalcolatori specializzati. Sebbene lo studio si basi su un dataset storico e richieda test più ampi attraverso ospedali e popolazioni diverse, indica un futuro in cui i dati dei controlli di routine, combinati con un’IA trasparente, possono offrire ai medici un «secondo parere» affidabile per cogliere le malattie cardiache prima, specialmente in contesti sanitari con risorse limitate.
Citazione: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Sustainable and interpretable heart disease prediction: a clinical decision support approach for biomedical healthcare applications. Sci Rep 16, 7213 (2026). https://doi.org/10.1038/s41598-026-37840-0
Parole chiave: predizione delle malattie cardiache, IA spiegabile, supporto decisionale clinico, reti neurali convoluzionali, analisi dei dati medici