Clear Sky Science · it
Rilevamento efficiente delle intrusioni nel dataset TON-IoT tramite approccio ibrido di selezione delle feature
Perché proteggere i dispositivi intelligenti è importante
Miliardi di dispositivi quotidiani — dalle telecamere domestiche ai sensori industriali — comunicano oggi attraverso Internet, formando ciò che chiamiamo Internet delle Cose (IoT). Questa connettività porta comodità ed efficienza, ma apre anche nuove vie agli attaccanti. L’articolo qui riassunto affronta una domanda semplice ma cruciale: come possiamo individuare in modo affidabile gli attacchi in queste reti di dispositivi estese senza ricorrere a software di sicurezza pesanti e dispendiosi in termini energetici?
La sfida di individuare intrusioni digitali
Per studiare gli attacchi ai sistemi IoT, i ricercatori spesso si affidano a grandi dataset pubblici che registrano come appare il traffico di rete sia durante il funzionamento normale sia durante i cyberattacchi. Uno dei più usati è il dataset ToN-IoT, che cattura traffico reale da un banco di prova industriale realistico, includendo molti tipi di attacco come denial of service, ransomware, cracking di password e intercettazioni man-in-the-middle. Tuttavia, gli autori mostrano che questo dataset nasconde un’insidia: molti attacchi sono stati lanciati da intervalli fissi di indirizzi IP e numeri di porta. Questo permette a un modello di “barare” imparando chi è l’attaccante anziché come si manifesta un comportamento dannoso. Tali modelli possono ottenere punteggi molto alti in laboratorio ma fallire clamorosamente quando l’attaccante proviene da un indirizzo nuovo.
Da dati ingombranti a una visione snella del comportamento
I dati di rete originali del ToN-IoT includono 44 misure diverse per ogni connessione, che vanno dalle informazioni IP ai dettagli sul traffico web e cifrato. Gestirle tutte aumenta i tempi di calcolo e la memoria richiesta, un problema per gateway IoT e dispositivi edge con risorse limitate. Gli autori usano innanzitutto la loro conoscenza del funzionamento degli attacchi per eliminare feature che sono o distorte (come indirizzi IP e numeri di porta) o poco utili per distinguere gli attacchi. Sostengono che la maggior parte delle minacce IoT si manifesta soprattutto come pattern anomali nel numero di pacchetti e bytes inviati e ricevuti e nella durata delle connessioni — indipendentemente da chi comunica con chi. Questa prima fase riduce il set di feature da 44 a sette statistiche fondamentali sul traffico relative a volume e durata.
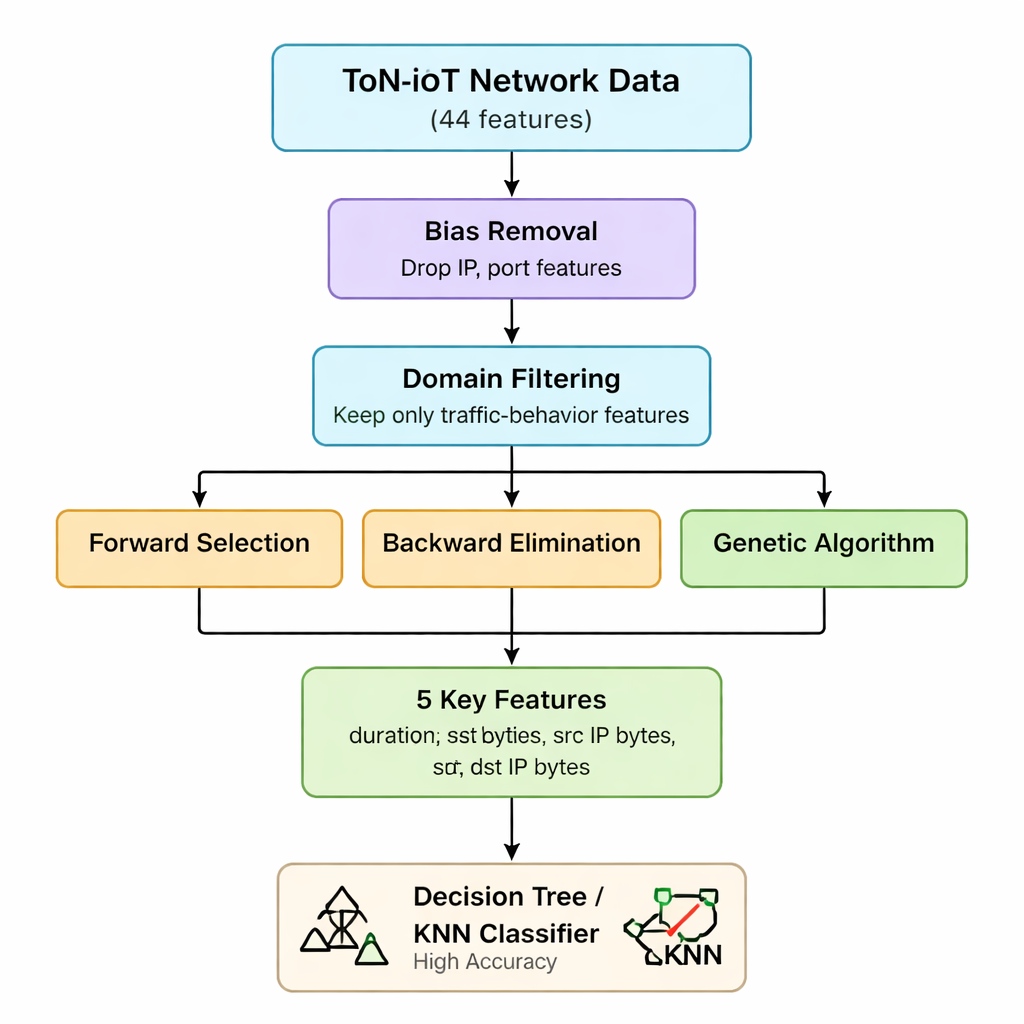
Selezione ibrida delle feature: tre prospettive sugli stessi dati
Successivamente, il team applica tre diversi metodi di tipo “wrapper” che ripetutamente addestrano un modello aggiungendo, rimuovendo o ricombinando feature per vedere quale sottoinsieme conta davvero. La selezione forward costruisce il set partendo da vuoto, mantenendo una feature solo se aumenta l’accuratezza. L’eliminazione backward parte da tutte le sette e rimuove quelle la cui eliminazione non peggiora l’accuratezza. Un algoritmo genetico esplora molte combinazioni in parallelo, evolvendo sottoinsiemi migliori attraverso generazioni. Tutti e tre vengono testati usando un semplice classificatore ad albero decisionale, con l’accuratezza come metro di giudizio. Incrociando i risultati, gli autori giungono a un nucleo stabile di cinque feature: durata della connessione, byte inviati, byte ricevuti e i corrispondenti conteggi di byte a livello IP. Queste cinque variabili catturano efficacemente picchi o squilibri anomali nel traffico che segnalano molti diversi tipi di attacco.
Modelli leggeri che restano performanti
Con questo dataset ridotto e incentrato sul comportamento, i ricercatori valutano quanto bene modelli di apprendimento automatico semplici riescano a distinguere traffico sicuro da attacchi. Usando solo le cinque feature scelte, un albero decisionale raggiunge il 98,6% di accuratezza nella classificazione binaria “attacco vs normale” e il 97,2% quando si distingue tra più categorie di attacco. Un modello k-nearest neighbor ottiene risultati simili, e metodi ensemble più complessi come random forest o gradient boosting offrono solo piccoli miglioramenti richiedendo però più calcolo e memoria. Crucialmente, gli autori confermano tramite test statistici che le feature scelte sono realmente informative, e non artefatti del modo in cui i dati sono stati raccolti. Osservano però che gli attacchi man-in-the-middle sottili — progettati per mimetizzarsi nei flussi normali — restano più difficili da rilevare, suggerendo che lavori futuri potrebbero richiedere segnali di protocollo o temporizzazione più ricchi per questi casi.
Cosa significa per la sicurezza nel mondo reale
Per i non specialisti, la principale conclusione è che non sempre servono modelli massicci o dozzine di misure tecniche per proteggere i sistemi IoT. Eliminando gli indizi che funzionano solo in una specifica configurazione di laboratorio e concentrandosi invece su una manciata di comportamenti del traffico, gli autori dimostrano che algoritmi semplici e rapidi possono comunque intercettare la maggior parte degli attacchi con alta affidabilità. La loro versione a cinque feature del dataset ToN-IoT è più facile da processare su dispositivi vincolati ai margini della rete, rendendola pratica per router, gateway e piccoli hub che devono reagire alle minacce in tempo reale. In breve, lo studio indica una strada verso sistemi di rilevamento delle intrusioni più affidabili e facilmente distribuibili per i dispositivi intelligenti che sempre più ci circondano.
Citazione: Dharini, N., Janani, V.S. & Katiravan, J. Efficient detection of intrusions in TON-IoT dataset using hybrid feature selection approach. Sci Rep 16, 7763 (2026). https://doi.org/10.1038/s41598-026-37834-y
Parole chiave: Sicurezza IoT, rilevamento intrusioni, apprendimento automatico, selezione delle feature, traffico di rete