Clear Sky Science · it
Applicazione di XGBoost e regressione logistica nella predizione della mortalità a 90 giorni per pazienti anziani con insufficienza renale acuta grave
Perché questa ricerca è importante per famiglie e pazienti
L’insufficienza renale acuta è una perdita improvvisa della funzione renale che colpisce spesso le persone anziane nelle unità di terapia intensiva. Può trasformare una malattia grave in una crisi potenzialmente letale, e molte famiglie e medici faticano a capire quali pazienti sono più a rischio di morire nelle settimane successive. Questo studio pone una domanda semplice ma importante: gli strumenti moderni basati sui dati possono aiutare i medici a identificare con maggiore accuratezza quali pazienti anziani con insufficienza renale grave sono più a rischio nei tre mesi successivi, in modo da adattare meglio le cure?
Chi è stato studiato e cosa si è proposto il team
I ricercatori hanno analizzato le cartelle di 7.500 persone di età superiore ai 60 anni ricoverate in terapia intensiva a Boston tra il 2008 e il 2019 che hanno sviluppato insufficienza renale acuta grave. Circa 1.150 di questi pazienti sono morti entro 90 giorni, sottolineando quanto questa condizione possa essere letale negli adulti anziani. Utilizzando questo ampio insieme di dati ospedalieri reali, il team ha confrontato due modi di trasformare le informazioni cliniche di letto—come età, pressione arteriosa, produzione di urine e punteggi di gravità della malattia—in una previsione di chi sarebbe stato vivo dopo tre mesi.
Due modi diversi di “leggere” i dati
Il primo metodo, la regressione logistica, è un cavallo di battaglia statistico di lunga data nella ricerca medica. Cerca relazioni lineari tra fattori di rischio e esiti ed è apprezzato perché i medici possono vedere facilmente come ogni fattore, come l’età o la pressione arteriosa, aumenti o diminuisca il rischio. Il secondo metodo, chiamato XGBoost, appartiene a una famiglia più recente di strumenti di machine learning. Invece di una singola linea retta, costruisce molti piccoli alberi decisionali che insieme possono catturare pattern complessi e curvi nei dati—for example, dove il rischio aumenta in modo marcato solo dopo che più fattori di rischio si allineano. Per questo motivo, in teoria XGBoost può estrarre più potenza predittiva dalle stesse informazioni ospedaliere, benché sia più difficile da interpretare a colpo d’occhio.
Cosa hanno trovato i modelli riguardo al rischio
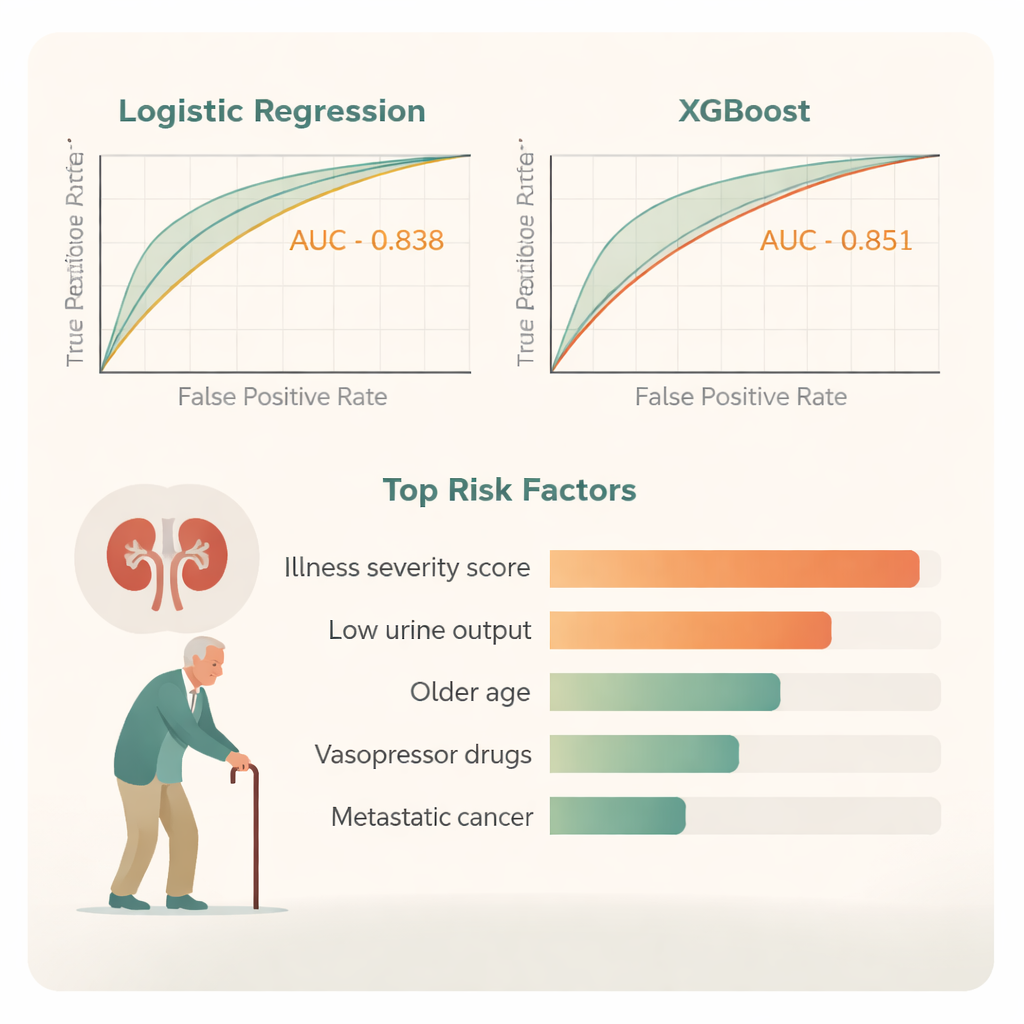
Entrambi gli approcci sono stati alimentati con gli stessi dati accuratamente puliti e testati usando rigorosi controlli incrociati ripetuti per evitare l’overfitting. Diverse caratteristiche sono emerse in modo consistente come fortemente correlate alla morte a 90 giorni. Tra queste c’erano quanto il paziente fosse grave all’arrivo in terapia intensiva (rappresentato da un punteggio chiamato APSIII), la scarsa produzione di urine, l’età avanzata, bassi livelli di ossigeno nel sangue e la necessità di farmaci che innalzano la pressione arteriosa, detti vasopressori. Avere un cancro avanzato con metastasi aumentava anch’esso notevolmente la probabilità di morte. Insieme, questi fattori delineano un quadro di pazienti più fragili i cui corpi lottano su più fronti contemporaneamente.
Quale metodo predittivo ha fatto meglio
Quando i due modelli sono stati confrontati testa a testa, entrambi hanno svolto un buon lavoro nel distinguere i pazienti che sarebbero sopravvissuti da quelli che non lo sarebbero stati. Tuttavia, XGBoost ha performato leggermente meglio: su una misura standard di accuratezza chiamata area sotto la curva ha segnato 0,851, contro 0,838 della regressione logistica. L’analisi della decisione, un modo per giudicare quanto un modello sia utile per scelte reali come l’intensificazione delle cure, ha mostrato che XGBoost offriva un beneficio netto più alto su un più ampio spettro di scenari clinici. Ha inoltre prodotto errori di previsione complessivamente più piccoli. Per rendere questo modello complesso più comprensibile al letto del paziente, il team ha creato un grafico “breakdown” che mostra, per un singolo paziente, come ciascun fattore spinga la previsione del rischio verso l’alto o verso il basso.
Cosa potrebbe significare per l’assistenza
Per un lettore non specialista, il messaggio principale è che i computer possono ora aiutare i medici a stimare, con ragionevole accuratezza, quali pazienti anziani in terapia intensiva con insufficienza renale improvvisa sono a maggior rischio di morire entro tre mesi. In questo studio, il più recente metodo di machine learning ha superato l’approccio tradizionale, soprattutto quando molti fattori di salute interagivano in modi complessi. Restano però il fatto che entrambi gli strumenti si basano su informazioni che gli ospedali già raccolgono—come produzione di urine, età, gravità della malattia, pressione arteriosa e presenza di cancro avanzato—and sono pensati per supportare, non sostituire, il giudizio clinico. Se testati ulteriormente in ospedali diversi, tali modelli potrebbero guidare conversazioni più tempestive sulla prognosi, aiutare a dare priorità alle risorse intensive scarse e incoraggiare un monitoraggio più attento e trattamenti personalizzati per quei pazienti i cui reni, e la salute complessiva, sono più precari.
Citazione: Zeng, J., Zhu, Y., Ye, F. et al. Application of XGBoost and logistic regression in predicting 90 days mortality for elderly severe acute renal failure patients. Sci Rep 16, 7077 (2026). https://doi.org/10.1038/s41598-026-37828-w
Parole chiave: insufficienza renale acuta, pazienti anziani in terapia intensiva, predizione della mortalità, machine learning in medicina, regressione logistica vs XGBoost