Clear Sky Science · it
Modellizzazione e applicazione della previsione di fenotipi complessi nella malattia di Alzheimer basata su apprendimento multi-task
Perché questa ricerca è importante per famiglie e pazienti
La malattia di Alzheimer è una delle diagnosi più temute dei nostri tempi, eppure i medici faticano ancora a prevedere chi declinerà rapidamente, chi resterà stabile per anni e quali segni precoci siano davvero rilevanti. Questo studio pone una domanda semplice ma potente: se consideriamo insieme diversi risultati di test correlati all’Alzheimer e immagini cerebrali, e li combiniamo con le informazioni genetiche di una persona, l’intelligenza artificiale moderna può apprendere schemi che ci aiutino a prevedere il decorso della malattia in modo più accurato?
I molti volti della stessa malattia
L’Alzheimer non è solo perdita di memoria. I pazienti differiscono nelle prestazioni ai test cognitivi, nella capacità di gestire le attività quotidiane e nell’aspetto delle loro immagini cerebrali. Queste diverse misure—come scale comuni di memoria e capacità cognitive, questionari sul funzionamento quotidiano e scansioni PET del metabolismo cerebrale o dell’accumulo di amiloide—sono in parte influenzate dai geni. È importante che condividano anche alcune delle stesse radici genetiche. I metodi di previsione tradizionali si concentrano di solito su una misura per volta, perdendo l’informazione utile che questi tratti sono correlati. Gli autori sostengono che, come un medico che valuta il quadro completo anziché un singolo test, i modelli dovrebbero imparare da più tratti contemporaneamente.
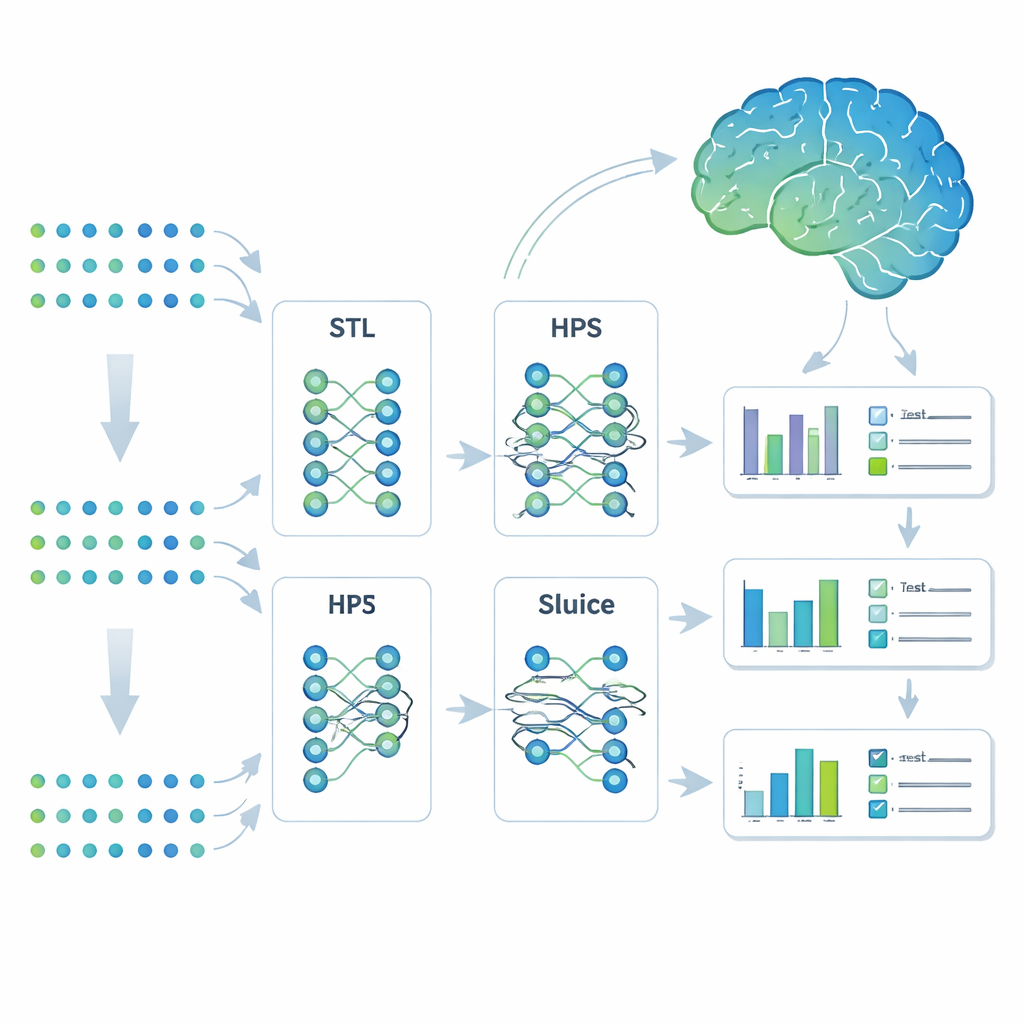
Insegnare a un modello a imparare molte attività correlate
I ricercatori hanno adottato una strategia di machine learning chiamata apprendimento multi-task. Invece di costruire modelli separati per ogni esito, hanno addestrato un unico sistema a predire sette tratti correlati all’Alzheimer simultaneamente. Hanno confrontato quattro approcci: modelli completamente separati (single-task learning), un modello condiviso semplice che si separa solo alla fine (hard parameter sharing), un design a diramazione più flessibile che può suddividere i compiti in sottogruppi, e un’architettura altamente adattabile chiamata Sluice Network che può regolare quanto informazioni vengono condivise a ogni livello della rete. Tutti e quattro i modelli ricevevano gli stessi input genetici; la differenza stava nel modo in cui condividevano ciò che imparavano tra i tratti.
Testare le idee in genomi simulati
Prima di fidarsi di un modello sui pazienti reali, il team ha costruito simulazioni dettagliate usando schemi genetici reali presi dall’Alzheimer’s Disease Neuroimaging Initiative (ADNI) ma con esiti completamente controllabili. Hanno creato scenari in cui tutti i tratti condividevano le stesse cause genetiche, scenari in cui i tratti formavano gruppi sovrapposti e scenari in cui ogni tratto aveva cause distinte. Hanno anche variato l’intensità dei segnali genetici e la quantità di rumore aggiunta, imitando la realtà complessa dei dati umani. In quasi tutte le condizioni, la Sluice Network ha fornito le previsioni più accurate e si è mantenuta stabile anche quando i tratti erano solo debolmente correlati. I modelli condivisi più semplici hanno funzionato bene quando i tratti avevano molti fattori genetici in comune ma hanno mostrato limiti quando questa condivisione era bassa, mentre i modelli completamente separati sono risultati coerenti ma complessivamente meno accurati.
Dati del mondo reale e il vantaggio di raggruppare i geni
Gli autori hanno poi applicato questi modelli ai dati reali ADNI di 463 individui, usando quasi 3.800 marcatori genetici tratti da 56 geni precedentemente associati all’Alzheimer. Qui hanno introdotto una modifica ispirata alla biologia: invece di fornire migliaia di marcatori genetici individuali, hanno prima raggruppato i marcatori per gene e hanno lasciato che la rete imparasse un segnale “riassuntivo” compatto per ciascun gene prima di predire i sette esiti. Questa aggregazione a livello genico ha migliorato le prestazioni per la maggior parte dei modelli e soprattutto per la Sluice Network, che ha circa raddoppiato la correlazione media con gli esiti reali. I miglioramenti sono risultati più netti per le misure di imaging PET e per alcuni punteggi cognitivi e funzionali, suggerendo che effetti genetici sottili diventano più rilevabili quando vengono combinati a livello di gene anziché trattati come marcatori isolati.
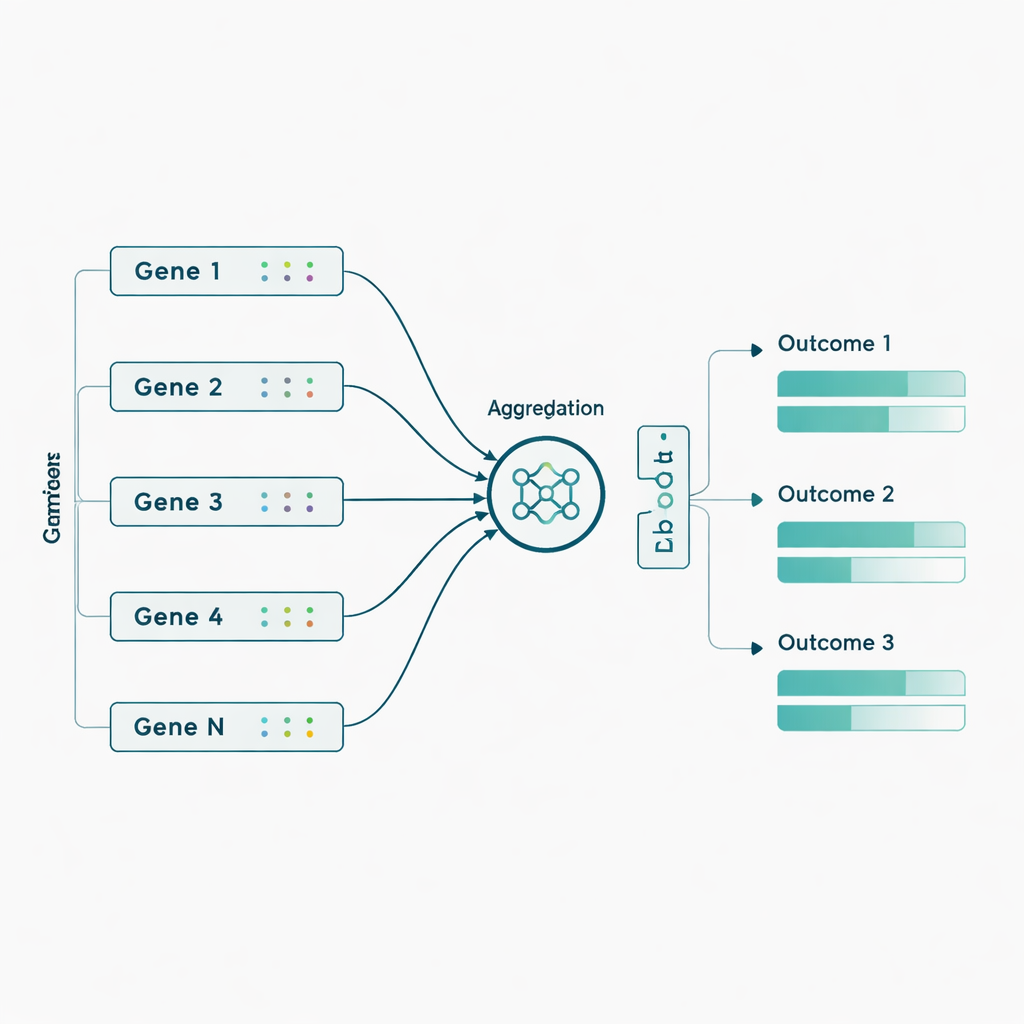
Cosa significa per le future previsioni e la cura
Per un non specialista, il messaggio è che modelli di IA più intelligenti e flessibili possono estrarre maggiori informazioni dagli stessi dati genetici e clinici imparando da più esiti correlati contemporaneamente e rispettando l’organizzazione biologica in geni. Pur essendo i miglioramenti attuali modesti e lontani dal costituire un test clinico, l’approccio indica la strada verso strumenti più affidabili per stimare il profilo di rischio di una persona, seguire la probabile progressione e forse adattare il monitoraggio o le interventi. Nelle malattie complesse come l’Alzheimer, dove molti piccoli effetti genetici interagiscono, metodi che condividono informazioni tra tratti e aggregano segnali deboli possono offrire un quadro più chiaro e informativo rispetto ai tradizionali punteggi un-tratto-alla-volta.
Citazione: Zhou, W., Xue, Z., Liang, J. et al. Modeling and application of alzheimer’s disease complex trait prediction based on multi-task learning. Sci Rep 16, 7749 (2026). https://doi.org/10.1038/s41598-026-37820-4
Parole chiave: Genetica della malattia di Alzheimer, apprendimento multi-task, predizione con deep learning, biomarcatori neuroimaging, aggregazione a livello genico