Clear Sky Science · it
Un’analisi comparativa delle prestazioni dei grandi modelli linguistici nell’esame di specialità odontoiatrica
Perché i chatbot intelligenti contano per i dentisti del futuro
L’intelligenza artificiale sta cambiando rapidamente il modo in cui medici e odontoiatri apprendono e lavorano. Uno degli strumenti più visibili è il chatbot conversazionale basato su grandi modelli linguistici—lo stesso tipo di tecnologia alla base di molti assistenti AI popolari. Questo studio ha posto una domanda semplice ma importante: se gli studenti di odontoiatria utilizzassero questi strumenti per prepararsi a un esame di specialità altamente competitivo in radiologia orale e maxillo-facciale, quanto bene se la caverebbero effettivamente le macchine?
Testare l’AI su un esame reale
Per scoprirlo, i ricercatori si sono rivolti all’Esame di Ammissione alla Specializzazione in Odontoiatria (DUS) in Turchia, che contribuisce a stabilire chi può accedere ai programmi di formazione avanzata. Da anni passati di questo test nazionale hanno selezionato 208 domande a scelta multipla che coprivano argomenti che gli specialisti di radiologia devono padroneggiare, dalla fisica delle radiazioni e le tecniche di imaging ai tumori mascellari e alle patologie dei seni. La maggior parte delle domande era solo testuale, ma un insieme più piccolo richiedeva l’interpretazione di immagini radiografiche, rispecchiando il lavoro diagnostico reale.
Sette chatbot affrontano la stessa sfida
Il gruppo ha quindi posto ogni domanda, in turco, a sette chatbot AI largamente usati basati su diversi grandi modelli linguistici: due versioni di ChatGPT, oltre a Gemini, Copilot, DeepSeek, Claude e Grok. Ogni domanda è stata inserita con cura e separatamente per evitare qualsiasi effetto di trascinamento tra le conversazioni. Un secondo ricercatore ha confrontato ogni risposta AI con la chiave ufficiale e ha contrassegnato ciascuna come corretta o errata. Infine, gli autori hanno utilizzato test statistici standard per confrontare i modelli nel complesso e all’interno di specifiche aree tematiche.
Chi ha ottenuto il punteggio più alto—e dove hanno inciampato
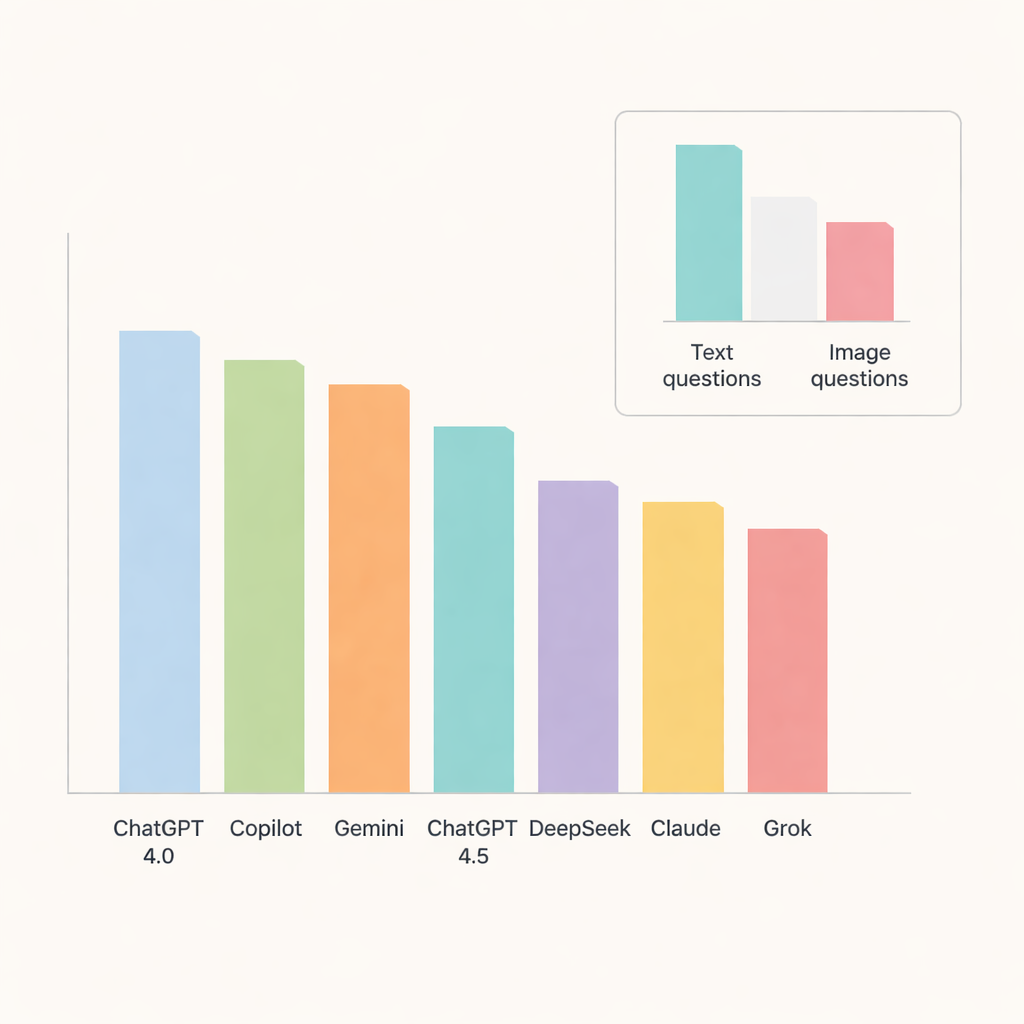
Tra tutti i chatbot, ChatGPT 4.0 si è distinto, rispondendo correttamente a circa il 91 percento delle domande. Copilot e Gemini gli sono seguiti da vicino con accuratezza intorno alla metà-alta degli ottanta, mentre ChatGPT 4.5, DeepSeek, Claude e Grok si sono posizionati un po’ più indietro. Quando i ricercatori hanno esaminato i singoli argomenti, i modelli si sono comportati particolarmente bene in patologia orale e nelle malattie delle ghiandole salivari, dove l’accuratezza si è avvicinata o superata il 90 percento. Al contrario, l’anatomia radiografica e le calcificazioni dei tessuti molli si sono rivelate visibilmente più difficili, abbassando i punteggi attraverso i sistemi e indicando aree in cui l’AI fatica ancora con dettagli di elevata precisione.
Le immagini restano più difficili delle parole
Un test chiave era se i chatbot potessero gestire le immagini tanto quanto il testo. Qui i loro limiti sono diventati evidenti. L’accuratezza è scesa drasticamente nelle domande basate su immagini, anche per i modelli con le migliori prestazioni. ChatGPT 4.0, Gemini e Copilot hanno guidato questa categoria ma hanno comunque risposto correttamente solo a circa due terzi delle domande visive. DeepSeek ha ottenuto i risultati peggiori sulle immagini, con poco più di un terzo corretto. Per la maggior parte dei modelli, la differenza tra le prestazioni su testo e su immagini è stata abbastanza ampia da risultare statisticamente significativa, sottolineando che l’interpretazione delle immagini mediche rimane un compito difficile per le AI generaliste odierne.
Cosa significa per studenti e pazienti
La conclusione dello studio è che i chatbot moderni possono essere potenti assistenti nell’educazione odontoiatrica, specialmente per ripassare concetti e praticare domande in stile esame in radiologia. Tuttavia, anche i sistemi più robusti commettono un numero sufficiente di errori—particolarmente in argomenti visivamente impegnativi o molto specifici—per cui non possono sostituire in sicurezza il giudizio di un esperto. Per studenti e clinici, questi strumenti vanno visti come partner di studio intelligenti o ausili decisionali, non come autorità autonome. Usati con cautela e supervisione appropriate, possono accelerare l’apprendimento e ampliare l’accesso a spiegazioni di alta qualità, mentre la responsabilità finale per diagnosi e trattamento rimane saldamente nelle mani dei professionisti formati.
Citazione: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
Parole chiave: istruzione odontoiatrica, intelligenza artificiale, grandi modelli linguistici, radiologia orale e maxillo-facciale, esami medici