Clear Sky Science · it
Rilevamento dello spam SMS cross-lingua usando aumentazione basata su GAN per dataset squilibrati
Perché i tuoi messaggi di testo hanno ancora bisogno di protezione
La maggior parte di noi si fida che i messaggi indesiderati finiscano silenziosamente in una cartella spam, ma dietro le quinte si tratta di un problema molto difficile. Lo spam reale è raro rispetto ai messaggi quotidiani e si presenta sempre più spesso in molte lingue simultaneamente. Questo articolo presenta un nuovo modo di individuare gli SMS pericolosi combinando potenti modelli linguistici con un ingegnoso generatore di “dati falsi”, così i filtri possono imparare da molti più esempi di messaggi dannosi senza mettere a rischio la tua privacy.
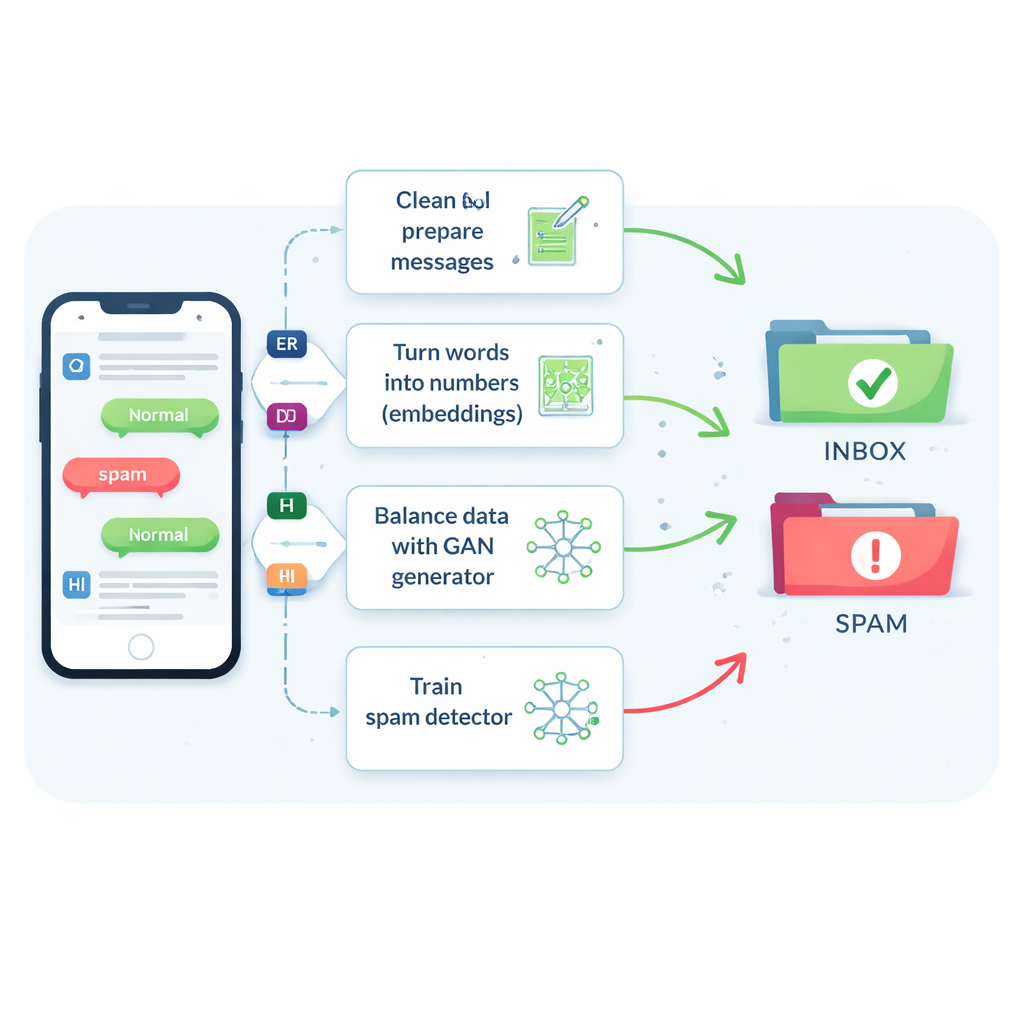
Il problema dello spam raro e mutevole
I messaggi di spam rappresentano solo circa uno su sette messaggi, ma mancare anche una piccola frazione di essi può esporre le persone a truffe, malware e furto d’identità. I filtri tradizionali faticano perché gli SMS sono brevi, pieni di gergo e abbreviazioni, e arrivano in tempo reale con poco contesto aggiuntivo. Di conseguenza, molti sistemi tendono a classificare i messaggi come sicuri, il che mantiene gli utenti soddisfatti ma lascia filtrare testi più dannosi. Vecchi stratagemmi che duplicano semplicemente i messaggi di spam o ne inventano di nuovi modificando le parole possono aiutare un po’, ma spesso confondono il filtro o creano esempi irrealistici che non corrispondono a ciò che i criminali inviano realmente.
Insegnare alle macchine a comprendere il significato dei messaggi
Gli autori iniziano confrontando otto diversi algoritmi di apprendimento, da strumenti noti come macchine a vettori di supporto e alberi decisionali fino a reti neurali più avanzate che leggono il testo come sequenza, come le reti LSTM (long short-term memory). Testano anche cinque modi di trasformare le parole in numeri utilizzabili dal computer. I conteggi semplici di quanto appare ogni parola (noti come bag-of-words o TF–IDF) sono veloci ma incapaci di cogliere il significato. I più recenti “embedding” come Word2Vec e GloVe collocano parole con significati simili vicine in uno spazio numerico. I più avanzati sono i modelli basati su transformer come BERT, che adattano la rappresentazione di una parola in funzione della frase circostante, aiutando il sistema a distinguere, per esempio, un promemoria amichevole da una truffa convincente.
Usare uno “spam finto” intelligente per correggere un dataset sbilanciato
L’innovazione centrale riguarda il modo in cui lo studio affronta la carenza di esempi di spam. Invece di generare frasi false complete, il team addestra un tipo di rete neurale chiamata Generative Adversarial Network (GAN) direttamente sugli embedding numerici dei messaggi di spam. Una parte della GAN, il generatore, impara a creare punti sintetici simili allo spam in questo spazio ad alta dimensione, mentre un’altra parte, il discriminatore, impara a distinguerli da quelli reali. Attraverso questa rivalità, il generatore produce nuovi embedding di spam realistici che ampliano il set di addestramento. Un controllo di qualità basato sulla somiglianza assicura che vengano conservati solo esempi sintetici che somigliano strettamente allo spam genuino, riducendo il rischio di dati senza senso che potrebbero fuorviare il classificatore.
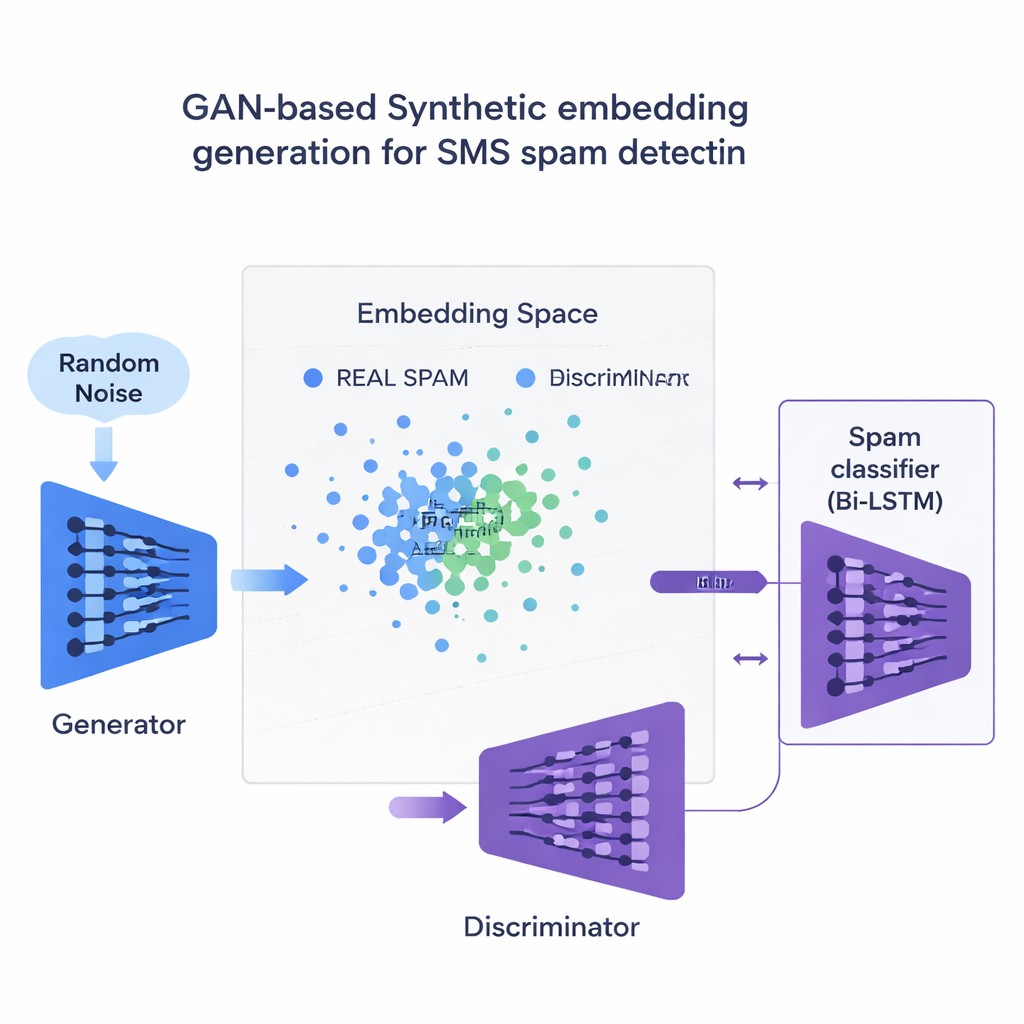
Risultati attraverso lingue e dispositivi
I ricercatori testano 120 diverse combinazioni di modelli, embedding e metodi di bilanciamento dei dati, sia su un dataset di SMS in inglese sia su una versione multilingue tradotta in francese, tedesco e hindi. In generale, gli embedding contestuali come BERT superano gli approcci più vecchi basati sul conteggio delle parole. La migliore configurazione — una LSTM bidirezionale alimentata con embedding BERT e addestrata con esempi di spam generati da una GAN — raggiunge un F1-score intorno al 97,6% sui messaggi in inglese e il 94,4% sul set multilingue, superando i sistemi allo stato dell’arte esistenti. Fondamentale, lo fa mantenendo i falsi positivi estremamente bassi, un requisito importante affinché password usa e getta e avvisi bancari non vengano nascosti agli utenti. Lo studio confronta inoltre questa strategia basata su GAN con strumenti di bilanciamento più comuni come SMOTE e ADASYN, rilevando che la GAN produce dati di addestramento più puliti e realistici e prestazioni complessive leggermente migliori.
Cosa significa per gli utenti quotidiani
Per i non specialisti, la conclusione è che i filtri anti-spam stanno cominciando a comprendere il significato e il contesto dei tuoi messaggi, non solo le singole parole, e possono essere “istruiti” con dati sintetici accuratamente costruiti anziché vedere più dei tuoi testi reali. Lavorando direttamente nello spazio in cui è codificato il significato del messaggio, il metodo proposto offre ai sistemi di sicurezza un quadro più ricco di come appare lo spam in molte lingue, senza inondarli di falsi maldestri. Questo aumenta la probabilità che i messaggi pericolosi vengano intercettati e che quelli genuini siano consegnati, offrendo una protezione più solida e adattabile per gli utenti mobili mentre i truffatori continuano a cambiare tattiche.
Citazione: Filali, A., Shorfuzzaman, M., Abdellaoui Alaoui, E. et al. Cross-lingual SMS spam detection using GAN-based augmentation for imbalanced datasets. Sci Rep 16, 7128 (2026). https://doi.org/10.1038/s41598-026-37769-4
Parole chiave: Rilevamento spam SMS, Aumentazione dati GAN, Embedding testuali BERT, Sicurezza informatica multilingue, Phishing mobile