Clear Sky Science · it
Una rete leggera ibrida per il miglioramento percettivo nella super-risoluzione di immagini a infrarossi
Visione termica più nitida per la tecnologia di tutti i giorni
Le camere a infrarossi ci permettono di “vedere” il calore al buio, attraverso la nebbia o all’interno delle macchine, ma le immagini che producono sono spesso sfocate e con pochi dettagli. Questo articolo presenta un nuovo metodo per rendere più nitide quelle immagini termiche sfocate usando l’intelligenza artificiale, così che telecamere di sicurezza, scanner medici e strumenti di controllo industriale possano fornire informazioni più chiare e affidabili senza richiedere hardware più ingombrante o costoso.
Perché è difficile rendere chiare le immagini a infrarossi
A differenza delle fotocamere per smartphone, i sensori a infrarossi catturano radiazione termica invisibile anziché luce visibile. Questo li rende preziosi per sicurezza, difesa, medicina e monitoraggio degli impianti, dove possono rilevare persone di notte, individuare infiammazioni o rivelare parti surriscaldate. Tuttavia, i sensori infrarossi hanno tipicamente bassa risoluzione perché i rivelatori di alta gamma sono costosi e energivori. I metodi software chiamati super-risoluzione cercano di trasformare un’immagine grezza a bassa risoluzione in una più nitida. Le reti neurali tradizionali basate su convoluzioni sono efficaci nell’individuare pattern locali come piccoli bordi, ma faticano a comprendere le relazioni tra parti distanti dell’immagine. Le reti più recenti basate su transformer catturano un contesto più ampio ma sono pesanti, lente e tendono a perdere dettagli fini come linee sottili e trame—esattamente le caratteristiche importanti per bersagli piccoli nelle scene a infrarossi.
Fondere due modi di vedere
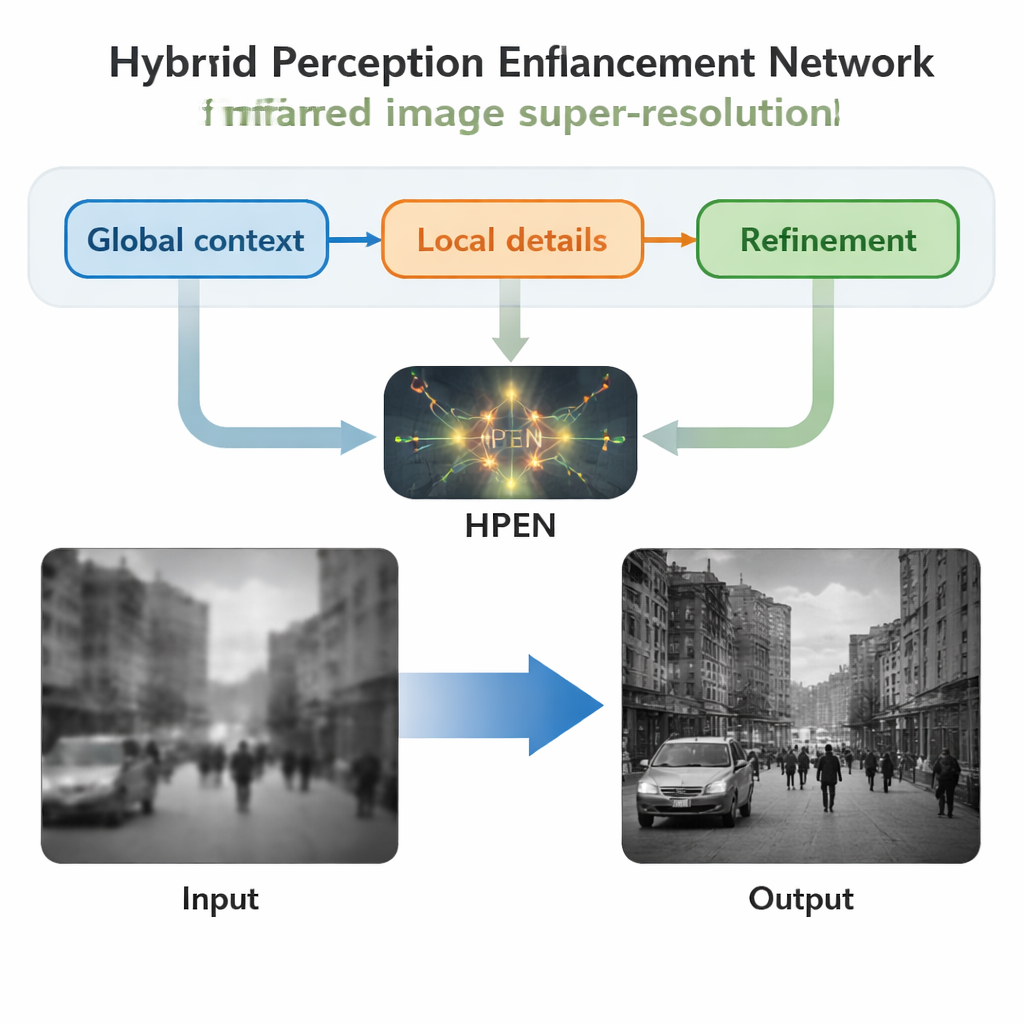
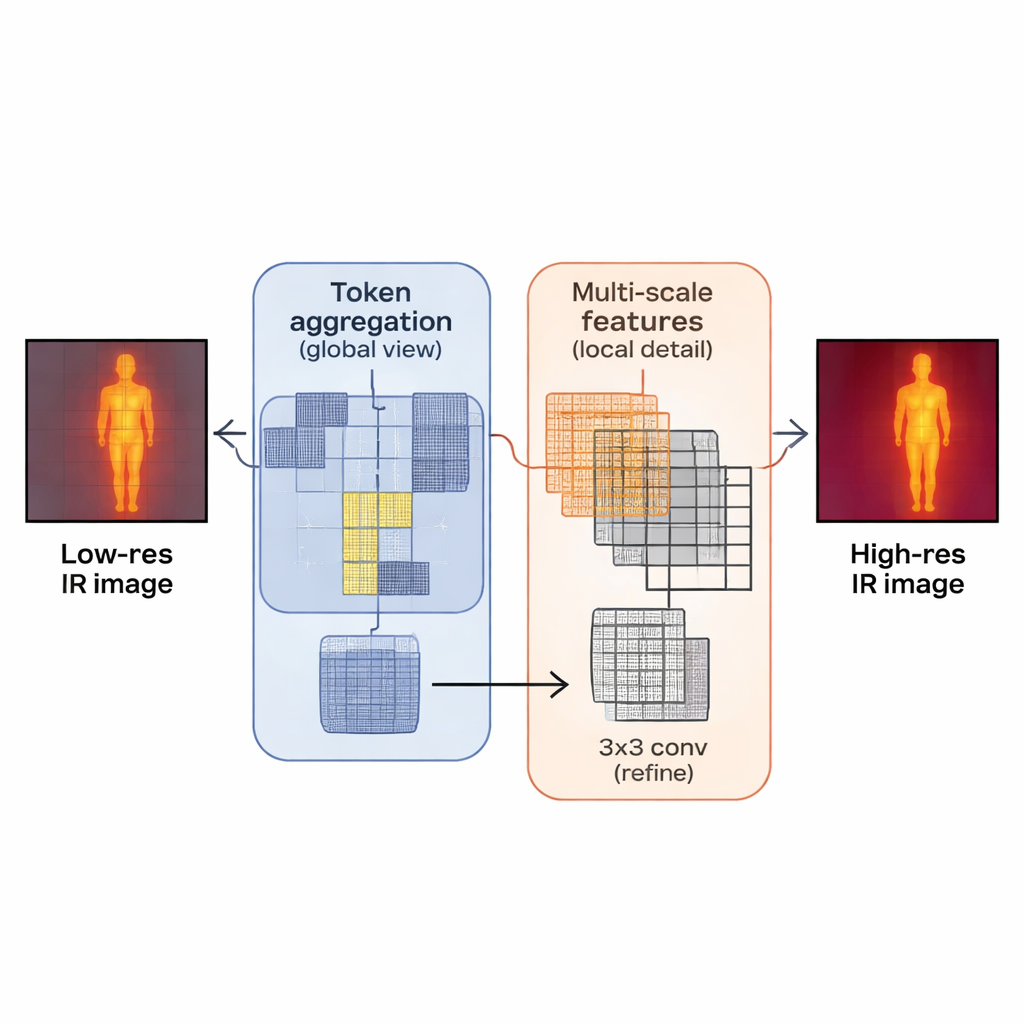
Gli autori propongono un nuovo modello, la Hybrid Perception Enhancement Network (HPEN), progettato specificamente per bilanciare dettaglio ed efficienza nelle immagini a infrarossi. Il suo blocco centrale, l’Hybrid Perception Enhancement Block, combina tre idee in sequenza. Primo, una fase di “aggregazione dei token” raggruppa patch simili attraverso l’immagine in modo che la rete possa ragionare sulla scena a livello globale, quasi come raggruppare regioni correlate prima di interpretarle. Secondo, una fase a “caratteristiche multi-scala” usa percorsi di elaborazione paralleli per osservare sia strutture piccole e fini sia vicinanze leggermente più ampie, aiutando la rete a mantenere contemporaneamente bordi, texture e forme più estese. Infine, un semplice filtro 3×3 affina e pulisce le caratteristiche, evitando gli effetti di smussamento che le operazioni globali possono introdurre.
All’interno del nuovo motore di sharpening
Guardando il sistema HPEN nella sua interezza, il processo inizia con un’elaborazione leggera dell’immagine a bassa risoluzione per estrarre pattern di base. Queste informazioni vengono poi passate attraverso una serie di blocchi ibridi, ciascuno dei quali approfondisce la comprensione della scena combinando relazioni a lunga distanza con dettagli su scala ridotta. Una connessione shortcut permette all’informazione originale e grossolana di bypassare questi strati profondi, così la rete può concentrarsi sulla ricostruzione del contenuto ad alta frequenza mancante—elementi come bordi nitidi e piccoli punti caldi. Nella fase finale, un modulo di upsampling compatto porta le caratteristiche alla risoluzione target, convertendole in un’immagine a infrarossi più nitida della stessa dimensione di un riferimento ad alta qualità. In tutto il progetto, il design è intenzionalmente leggero, mantenendo il numero di operazioni e l’utilizzo di memoria sufficientemente bassi per un impiego pratico su comuni processori grafici.
Quanto bene funziona il metodo nella pratica
Per testare HPEN, gli autori lo hanno addestrato e valutato su diversi dataset pubblici a infrarossi che includono scene urbane, vegetazione, veicoli, pedoni e condizioni notturne. Lo hanno confrontato con numerosi metodi di super-risoluzione “leggeri” recenti che mirano a essere sia accurati sia efficienti. HPEN ha costantemente eguagliato o leggermente superato questi concorrenti sulle misure standard di qualità che valutano quanto l’immagine migliorata sia vicina a un riferimento ad alta risoluzione. Si è dimostrato particolarmente efficace nella difficile impostazione di ingrandimento quattro volte, dove trasformare un’immagine molto piccola in una molto più grande spesso mette in evidenza artefatti. Nonostante questa accuratezza, HPEN ha richiesto sostanzialmente meno calcoli, molta meno memoria della GPU e ha offerto tempi di elaborazione più rapidi rispetto a forti competitor basati su transformer. Test aggiuntivi che valutano la qualità percepita, in modo simile al giudizio umano, hanno mostrato che i risultati di HPEN apparivano più simili alle vere immagini a infrarossi ad alta risoluzione, con meno bordi slavati e texture meglio preservate.
Cosa significa per gli usi nel mondo reale
Per un pubblico non specialista, il messaggio chiave è che HPEN offre un modo più intelligente per “migliorare lo zoom” delle camere termiche senza cambiare l’hardware. Combinando con cura contesto globale (comprendere l’intera scena) e dettaglio locale (preservare piccoli bordi e texture) in un pacchetto efficiente, il metodo produce immagini a infrarossi più nitide e informative mantenendo sotto controllo i costi di calcolo. Questo potrebbe aiutare i sistemi di sorveglianza a individuare persone o veicoli più chiaramente al buio, permettere agli ispettori industriali di vedere crepe sottili o punti caldi sui macchinari e fornire ai medici pattern termici più chiari durante screening non invasivi—il tutto usando sensori esistenti che improvvisamente vedono più di quanto vedessero prima.
Citazione: Liu, Z., Tian, J., Liu, C. et al. A lightweight hybrid perception enhancement network for infrared image super-resolution. Sci Rep 16, 6572 (2026). https://doi.org/10.1038/s41598-026-37763-w
Parole chiave: immagini a infrarossi, super-risoluzione, apprendimento profondo, miglioramento delle immagini, visione artificiale