Clear Sky Science · it
Un'architettura leggera di reti neurali convoluzionali per il rilevamento della violenza nelle sequenze video
Guardare le folle così gli umani non devono farlo
Dai concerti e gli stadi alle stazioni della metropolitana e ai centri commerciali, le telecamere sorvegliano ormai quasi ogni spazio affollato. Eppure la maggior parte di quei flussi video è ancora monitorata da occhi umani stanchi che possono facilmente perdere i primi segnali di una rissa o di un fuggi‑fuggi. Questo articolo esplora come una forma snella e veloce di intelligenza artificiale possa analizzare video in diretta alla ricerca di comportamenti violenti in tempo reale, anche su hardware a basso costo, aiutando il personale di sicurezza a intervenire rapidamente prima che la situazione sfugga al controllo.
Perché individuare la violenza nei video è così difficile
A prima vista, chiedere a un computer di distinguere “rissa” da “assenza di rissa” sembra semplice: basta riconoscere persone che si colpiscono. In realtà il problema è complesso. L’illuminazione può essere scarsa o cambiare improvvisamente, le folle possono ostruire la visuale e le telecamere sono montate con angolazioni molto diverse. Un concerto affollato sembra caotico anche quando non accade nulla di pericoloso, mentre un incontro di pugilato appare violento ma è perfettamente normale dentro il ring. I sistemi tradizionali di visione analizzavano pattern di movimento e contorni progettati a mano fotogramma per fotogramma e, pur funzionando in laboratorio, spesso risultavano troppo lenti o imprecisi per reti di sorveglianza complesse del mondo reale.
Un cervello più snello per i flussi delle telecamere
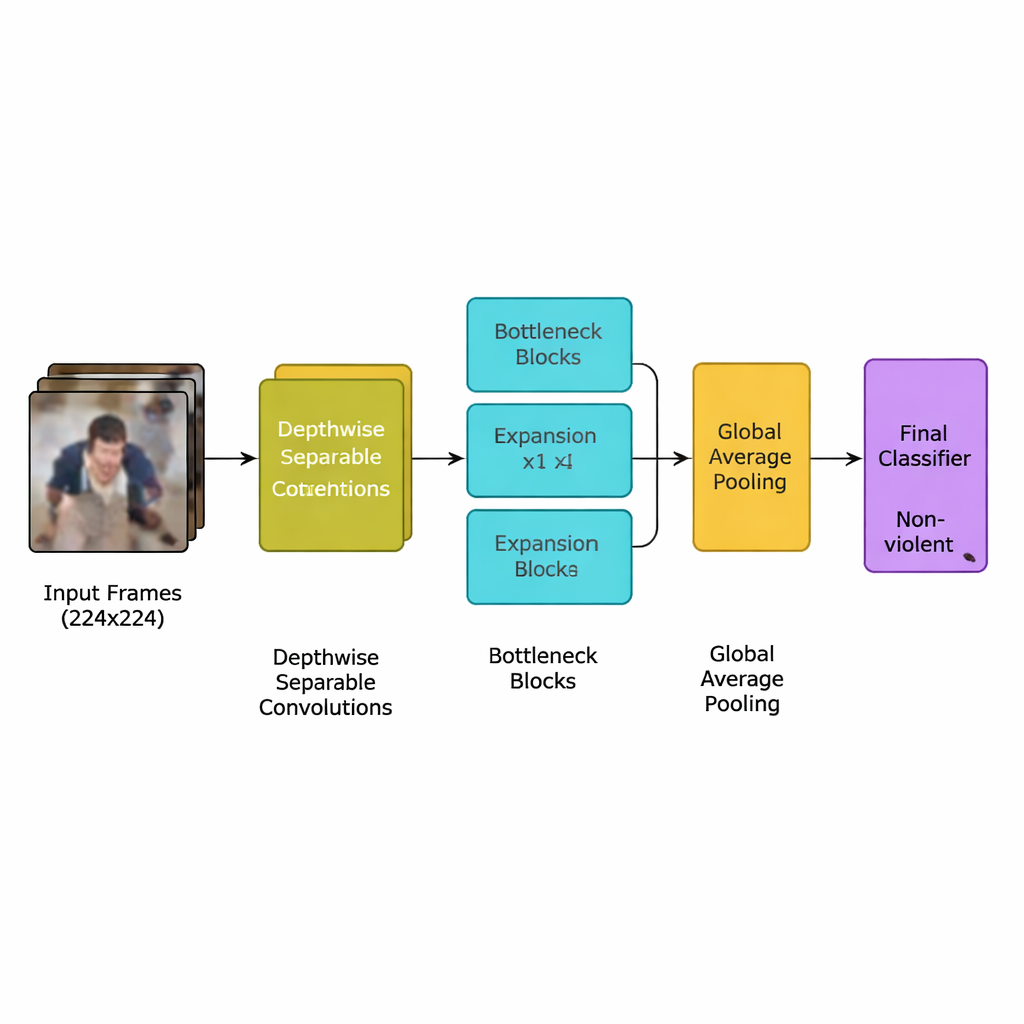
Gli autori presentano un nuovo modello di deep learning progettato specificamente per questo compito: una rete neurale convoluzionale (CNN) leggera derivata da una famiglia efficiente di modelli nota come MobileNetV2. Invece di impiegare numerosi strati pesanti che richiedono potenti processori grafici, la rete si basa su convoluzioni separabili in profondità—calcoli piccoli e mirati che riducono drasticamente il numero di operazioni. Usa inoltre blocchi a “collo di bottiglia invertito”, che espandono brevemente e poi comprimono le informazioni per conservare gli indizi di movimento importanti riducendo le ridondanze. Su questo livello il team aggiunge un meccanismo di attenzione chiamato squeeze‑and‑excitation, che aiuta la rete a concentrarsi sui modelli di movimento spaziali e temporali più tipici degli episodi violenti, ignorando i dettagli di sfondo distraenti.
Dal video grezzo agli allarmi di violenza
Il sistema completo segue una pipeline chiara. Prima, i flussi video vengono suddivisi in fotogrammi e si conserva solo ogni quinto fotogramma per rimuovere quasi‑duplicati mantenendo però i movimenti bruschi che spesso segnalano una rissa. I fotogrammi vengono ridimensionati a una risoluzione standard di 224×224 pixel, lievemente sfocati per ridurre il rumore di fondo e quindi casualmente ribaltati o ruotati durante l’addestramento in modo che il modello impari a gestire diversi punti di vista delle telecamere. Queste immagini preparate alimentano la CNN leggera, che converte gradualmente i pixel grezzi in pattern di comportamento di folla di livello più alto. Dopo un passaggio finale di pooling che sintetizza ogni fotogramma, un piccolo classificatore fornisce una decisione semplice: violento o non violento. Poiché il modello utilizza solo circa 1,94 milioni di parametri—meno dei suoi antenati MobileNet e MobileNetV2—può funzionare in tempo reale su dispositivi modesti collocati vicino alle telecamere invece che in un data center remoto.
Mettere il sistema alla prova
Per verificare se questo design compatto potesse competere con reti più voluminose, i ricercatori lo hanno addestrato e valutato su due benchmark ampiamente usati. Il Real‑Life Violence Situations Dataset contiene 2.000 clip brevi raccolte da YouTube che mostrano sia scene di vita quotidiana sia risse reali in luoghi diversi. L’Hockey Fight Dataset offre 1.000 clip di partite professionistiche di hockey, divise tra gioco ordinario e risse sul ghiaccio. Su questi dataset il modello proposto ha etichettato correttamente circa il 97 percento delle clip in scenari reali e il 94 percento nelle riprese di hockey, eguagliando o superando CNN più grandi come InceptionV3 e VGG‑19 pur usando molte meno risorse di calcolo. I test incrociati tra i due dataset—addestrando su uno e valutando sull’altro—hanno mostrato che il sistema mantiene comunque prestazioni ragionevoli, suggerendo che cattura pattern di movimento generali piuttosto che memorizzare un unico ambiente.
Cosa significa per la sicurezza quotidiana
Per i non esperti, il punto chiave è che oggi è possibile costruire sistemi di telecamere che segnalano automaticamente la probabile violenza in modo rapido ed economico, senza necessità di server giganteschi o sorveglianza umana costante. Lo studio dimostra che una rete neurale accuratamente snellita e ottimizzata può monitorare molteplici flussi contemporaneamente, inviare allarmi quando rileva comportamenti pericolosi e funzionare su hardware a basso consumo adatto a snodi di trasporto pubblico, scuole, ospedali e strade cittadine. Pur restando sfide—come gestire scene molto buie, folle fitte o integrare segnali audio—il lavoro indica una direzione in cui le telecamere intelligenti diventano sensori di allerta precoce instancabili, aiutando le squadre di sicurezza a proteggere le persone in modo più efficace riducendo il carico sugli osservatori umani.
Citazione: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
Parole chiave: rilevamento della violenza, videosorveglianza, CNN leggera, MobileNetV2, sicurezza pubblica