Clear Sky Science · it
MSRCTNet: una nuova rete tripletto a capsule multi-scala per la rimozione efficiente di fotogrammi ridondanti nei video di videocapsule endoscopiche wireless
Ingoiare una telecamera, annegare nelle immagini
Immaginate di diagnosticare malattie intestinali inghiottendo una telecamera grande come una vitamina che fotografa in silenzio l’intero tratto digerente. L’endoscopia con videocapsula wireless rende già tutto questo possibile, ma ogni esame produce circa 55.000 immagini, la maggior parte delle quali appaiono quasi identiche. I medici devono setacciare questo diluvio visivo per individuare piccole macchie di sanguinamento, infiammazione o tumori. Lo studio alla base di MSRCTNet pone una domanda semplice ma cruciale: un sistema intelligente può eliminare in modo sicuro i fotogrammi simili, così che i medici vedano solo ciò che è davvero importante?
Perché troppe immagini possono essere un problema
L’endoscopia convenzionale richiede un tubo flessibile inserito attraverso la bocca o il retto, una procedura che molti pazienti trovano sgradevole e che non raggiunge sempre l’intero intestino tenue. La videocapsula risolve questo problema lasciando che una pillola‑telecamera scorra lungo l’intestino, scattando foto a ogni secondo. Lo svantaggio è il sovraccarico: solo circa l’1% dei fotogrammi contiene informazioni chiaramente utili, mentre il resto ripete per lo più le stesse pieghe di tessuto. Revisionare tali volumi è lento e stancante, aumentando il rischio che un clinico esausto possa perdere una lesione sottile. Metodi informatici precedenti hanno cercato di aiutare raggruppando fotogrammi simili, comprimendo i dati o basandosi su semplici indizi di colore e texture, ma spesso fallivano quando cambiava l’illuminazione, l’intestino si muoveva in modo complesso o le anomalie rare comparivano in pochi esempi.
Un modo più intelligente per rilevare la ripetizione
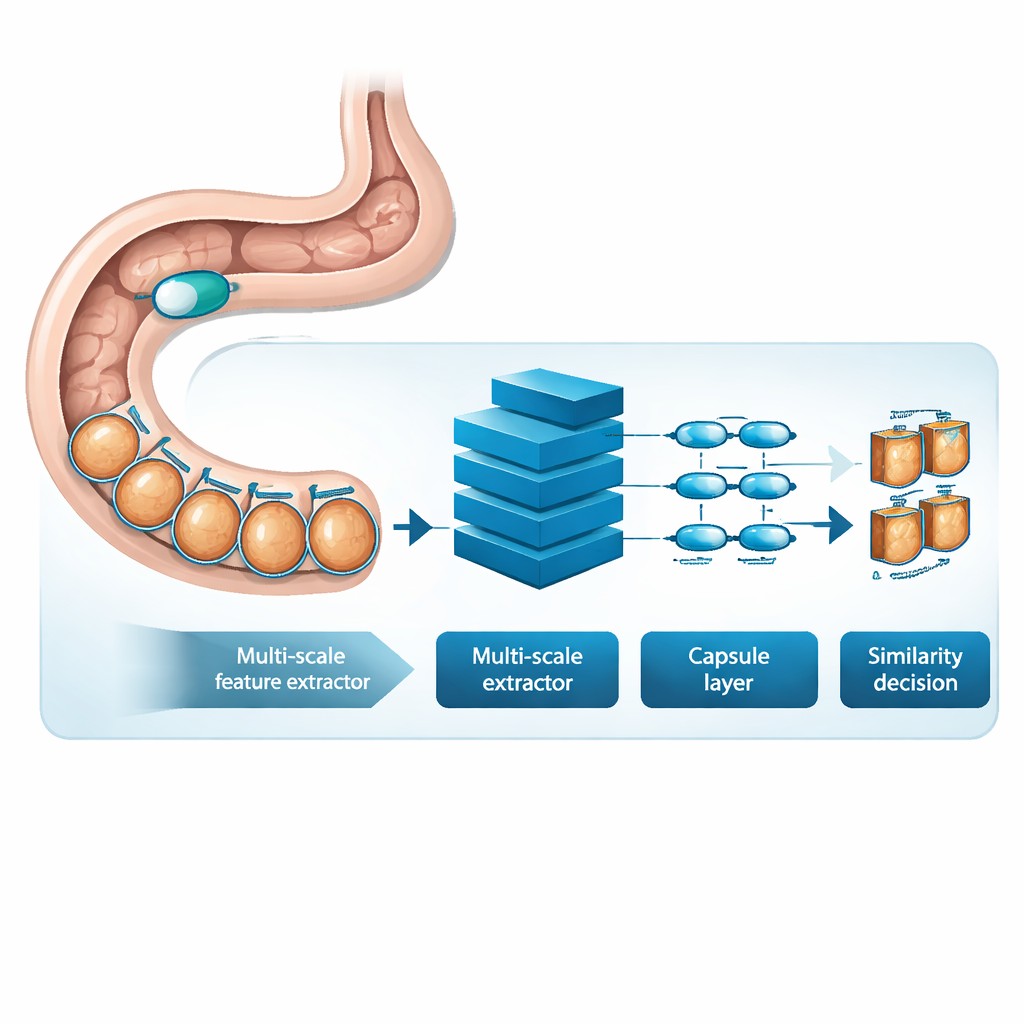
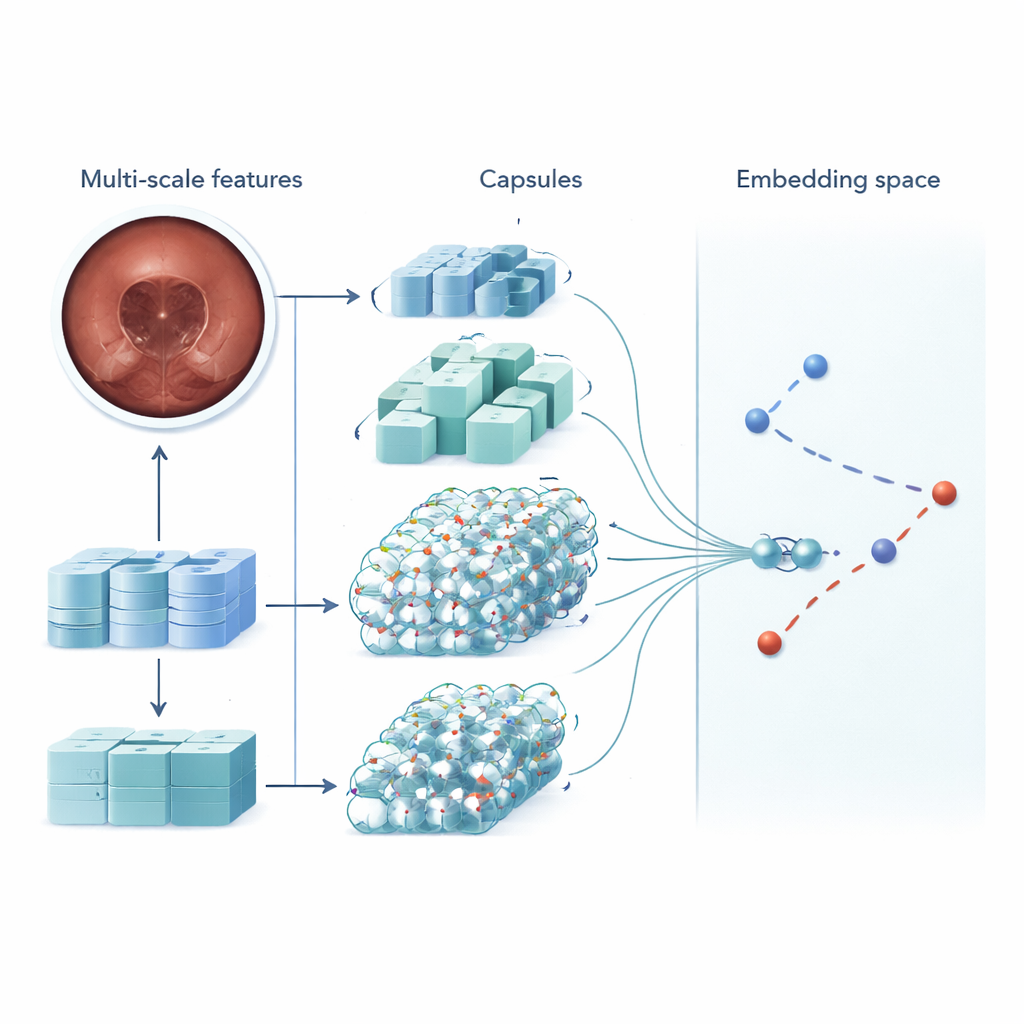
MSRCTNet (Multi‑Scale Capsule Triplet Network) è un sistema di deep learning progettato per agire come filtro intelligente per i video da videocapsula. Piuttosto che trattare ogni immagine come una semplice fotografia piatta, il sistema esamina simultaneamente pattern a più scale—dalle trame fini del rivestimento intestinale alle forme più ampie della parete—utilizzando un meccanismo di attenzione per enfatizzare i dettagli più informativi. Queste caratteristiche arricchite vengono poi passate a uno strato in stile capsule che preserva come le parti dell’immagine si relazionano spazialmente, come l’orientamento e la disposizione di pieghe o lesioni. Infine, un modulo di similarità specializzato confronta triplette di fotogrammi—un’immagine di riferimento, una che dovrebbe essere simile e una che dovrebbe essere diversa—per apprendere una rappresentazione in cui i fotogrammi realmente ridondanti si raggruppano strettamente e quelli distintivi rimangono separati.
Apprendere da esami reali sui pazienti
Per testare MSRCTNet, i ricercatori hanno raccolto un ampio dataset di 257.362 immagini provenienti da 60 esami con videocapsula eseguiti in un ospedale in Cina. Le immagini includevano tessuto normale, regioni oscurate da bolle e anomalie evidenti come sanguinamento e infiammazione, tutte etichettate da clinici esperti. Il sistema è stato addestrato a giudicare se coppie di fotogrammi fossero simili o meno, usando una combinazione di due obiettivi di apprendimento: uno che avvicina i fotogrammi della stessa categoria e allontana quelli di categorie diverse, e un altro che insegna alla rete a dire direttamente se una coppia è simile. Una volta addestrato, il modello esamina un video tre fotogrammi alla volta e decide quali delle immagini vicine sono veramente ridondanti. Applicando semplici regole a queste decisioni di similarità, scarta le visuali ripetute mantenendo fotogrammi chiave rappresentativi.
Velocità, accuratezza e meno problemi mancati
Nei dati di test, MSRCTNet ha gestito correttamente la ridondanza dei fotogrammi in circa il 96% dei casi, con un tasso di falsi allarmi sotto il 3% e un tasso di fotogrammi mancati inferiore allo 0,2%. In pratica, per un esame da 50.000 fotogrammi questo corrisponde a meno di 100 fotogrammi potenzialmente rilevanti non individuati—una quantità tale che le immagini circostanti forniscono ancora contesto a sei fotogrammi al secondo. Rispetto a diverse tecniche precedenti basate su clustering, analisi del movimento o reti neurali più semplici, MSRCTNet è risultata sia più accurata sia più robusta quando i dati erano sbilanciati, cioè quando le immagini normali superavano di gran lunga le lesioni rare. Il sistema è risultato anche veloce: circa 0,02 secondi per fotogramma, ovvero circa 15 minuti per ridurre un esame completo a circa 2.500 fotogrammi chiave, un volume molto più gestibile per la revisione umana.
Cosa significa per pazienti e medici
Per i pazienti, il progresso descritto in questo articolo non cambia la capsula che ingeriscono, ma potrebbe rendere il loro esame più efficace. Eliminando automaticamente immagini quasi duplicate senza soglie tarate a mano o euristiche fragili, MSRCTNet consente ai clinici di concentrare l’attenzione su un sommario conciso e ricco di informazioni del viaggio attraverso l’intestino. L’approccio preserva le scoperte clinicamente importanti riducendo affaticamento e tempo alla postazione di lettura, rendendo potenzialmente gli esami non invasivi con videocapsula più attraenti e diffusi. In sostanza, il metodo trasforma un torrente di immagini in una sequenza curata di punti salienti, avvicinando la promessa dell’intelligenza artificiale alla cura quotidiana delle malattie digestive.
Citazione: Li, Q., Wang, S., Cheng, Z. et al. MSRCTNet: a novel multi-scale capsule triplet network for efficient redundant frame removal in wireless capsule endoscopy videos. Sci Rep 16, 6902 (2026). https://doi.org/10.1038/s41598-026-37669-7
Parole chiave: endoscopia con videocapsula wireless, riassunto di video medici, apprendimento profondo, rimozione di fotogrammi ridondanti, imaging gastrointestinale