Clear Sky Science · it
Modellizzazione longitudinale della condizione post-COVID-19 in tre anni: un approccio di machine learning con marcatori clinici, neuropsicologici e fluidi
Perché i sintomi persistenti del COVID continuano a essere importanti
Milioni di persone nel mondo continuano a sentirsi male mesi o anche anni dopo aver contratto il COVID‑19. Questa condizione, spesso chiamata long COVID o Condizione Post‑COVID‑19, può causare una stanchezza debilitante, “brain fog”, disturbi del sonno e altri sintomi difficili da rilevare con i test medici standard. Lo studio qui descritto ha seguito un gruppo di adulti per tre anni dopo l’infezione e ha utilizzato tecniche computazionali moderne per cercare nel sangue, nelle visite cliniche e nei test delle capacità cognitive dei pattern che rivelino come il long COVID cambia nel tempo e quali misure monitorano meglio il recupero o la persistenza della malattia.
Seguire i pazienti nel lungo periodo
I ricercatori in Germania hanno arruolato 93 adulti con infezione da SARS‑CoV‑2 confermata e con persistenti disturbi neurologici o neuropsicologici. Questi partecipanti, per lo più in età adulta di mezza età, sono stati esaminati quattro volte: approssimativamente a 6, 14, 23 e 38 mesi dall’infezione iniziale. A ogni visita hanno compilato questionari dettagliati su affaticamento, umore e sonno; hanno svolto test brevi e più estesi di attenzione, memoria e velocità mentale; e hanno fornito campioni di sangue per un ampio pannello di misurazioni di laboratorio. Queste includevano marcatori standard di salute, segnali di infiammazione, attività del sistema immunitario e proteine specializzate rilasciate quando le cellule cerebrali sono danneggiate.
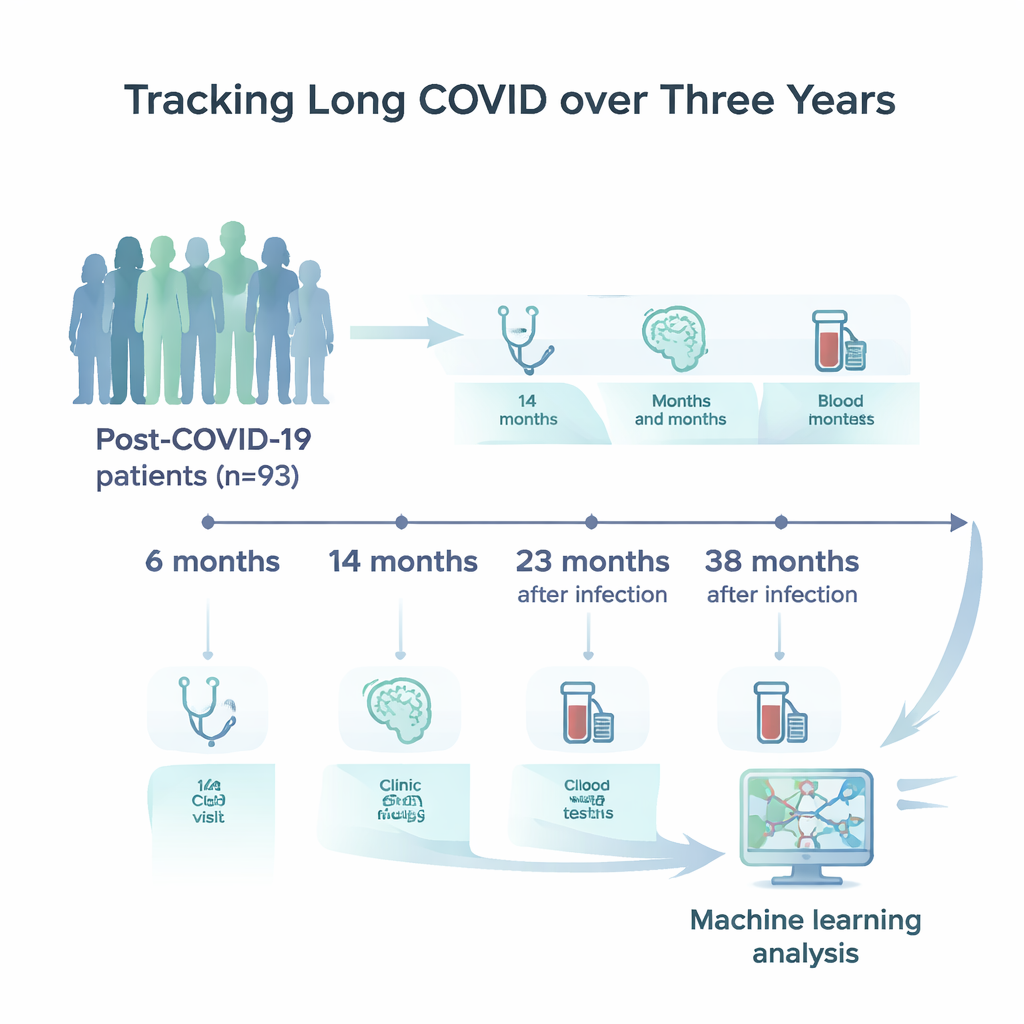
Lasciare che i computer trovino pattern nascosti
Invece di esaminare un sintomo o un esame del sangue alla volta, il team si è rivolto al machine learning, un ramo dell’intelligenza artificiale capace di analizzare molte variabili contemporaneamente e individuare relazioni sottili. Hanno addestrato una serie di modelli computazionali per rispondere a una domanda precisa: dato il dataset combinato di una singola visita clinica, l’algoritmo è in grado di determinare a quale anno di follow‑up appartiene quella visita? In altre parole, il profilo complessivo di una persona a 6 mesi è misurabilmente diverso dal suo profilo a 2 o 3 anni? I ricercatori hanno gestito con cura i valori mancanti, hanno usato la cross‑validation per evitare l’overfitting su un campione ridotto e hanno confrontato diverse famiglie di modelli, dagli alberi decisionali semplici ai metodi avanzati di gradient boosting.
Quali segnali indicano meglio il tempo trascorso
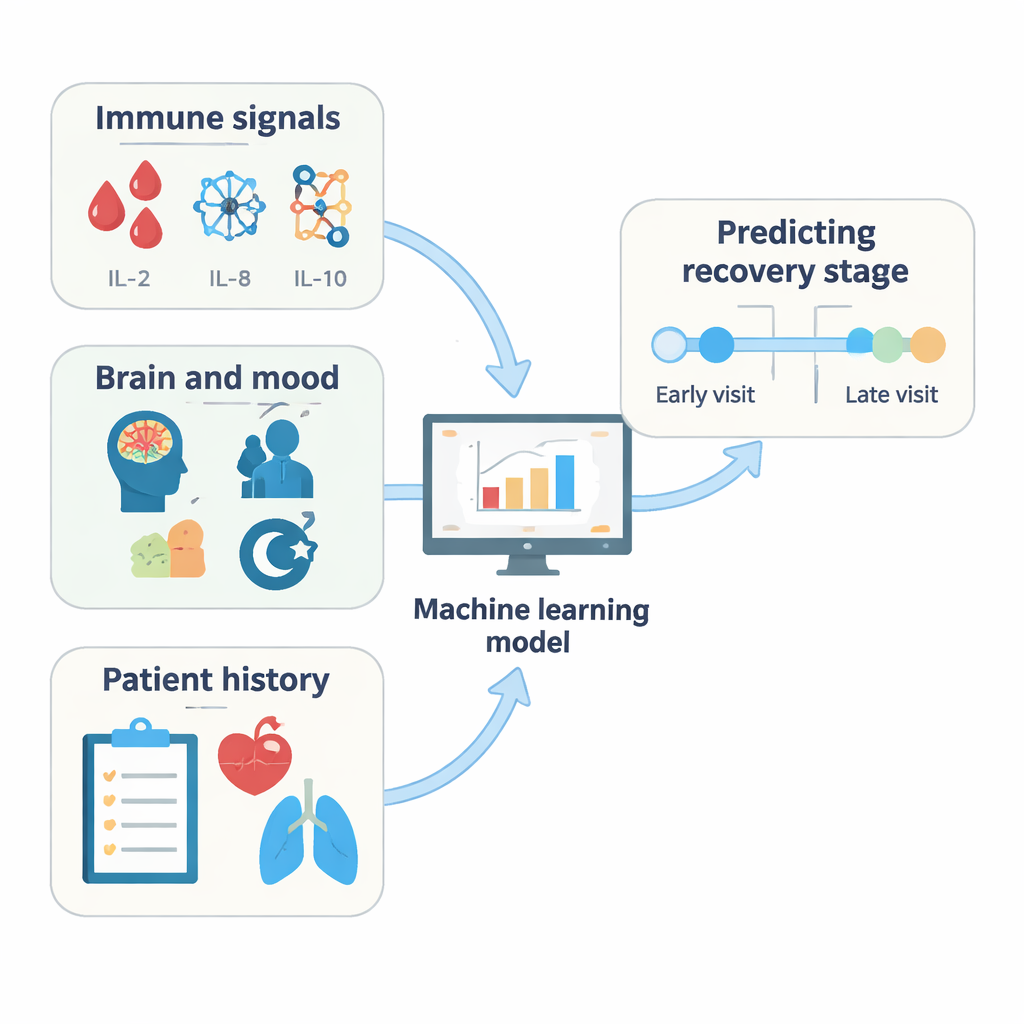
I modelli hanno ottenuto prestazioni impressionanti. Confrontando visite più distanti nel tempo — come la prima e la quarta — alcuni algoritmi hanno assegnato correttamente l’anno in ben oltre il 90 percento dei casi. Anche tra punti temporali più ravvicinati, l’accuratezza è rimasta elevata, calando solo in misura minore tra la terza e la quarta visita, suggerendo che i profili dei pazienti cambiano più lentamente nelle fasi successive. I metodi con migliori prestazioni sono risultati essere i modelli di gradient boosting basati su alberi, particolarmente efficaci nell’individuare pattern non lineari. Per aprire la “scatola nera” e capire cosa guidasse queste decisioni, il team ha utilizzato strumenti di explainability chiamati SHAP e LIME che classificano le caratteristiche che spingono una previsione in una direzione o nell’altra.
Indizi immunitari, brain fog e importanza variabile
Da diverse analisi è emerso un quadro coerente. I livelli di molecole infiammatorie nel sangue — in particolare alcune interleuchine come IL‑2, IL‑8 e IL‑10 — sono risultati tra gli indizi più forti per distinguere i follow‑up precoci da quelli successivi. Anche le misure della risposta anticorpale all’virus, in particolare gli anticorpi diretti contro la proteina spike (che riflettono anche la vaccinazione nel tempo), sono risultate indicatori potenti. Sul versante cognitivo, i test di memoria verbale e di ricerca delle parole, insieme ai punteggi relativi ad affaticamento e sonnolenza, hanno fornito informazioni importanti, soprattutto nelle fasi iniziali dopo l’infezione. Col passare del tempo, i marcatori immunitari tendevano a guadagnare peso nei modelli, mentre alcune misure neuropsicologiche diventavano meno centrali, suggerendo che i fattori biologici alla base del long COVID possano evolvere nel corso degli anni.
Implicazioni per i pazienti e la cura
Per i non specialisti, il messaggio chiave è che il long COVID non è solo una vaga raccolta di lamentele. Quando viene monitorato con attenzione per diversi anni, segnali oggettivi nel sangue e nei test delle capacità cognitive cambiano in modi che i computer riescono a riconoscere in modo affidabile. Questo studio suggerisce che una combinazione di marcatori immunitari, livelli di anticorpi e valutazioni mirate della cognizione e dell’affaticamento potrebbe aiutare i medici a monitorare chi sta recuperando, chi rimane a rischio di problemi duraturi e quali pazienti potrebbero beneficiare maggiormente dei trattamenti emergenti che mirano al sistema immunitario. Pur richiedendo studi più ampi e numerosi prima che questi strumenti entrino nella pratica clinica di routine, il lavoro mostra come l’intelligenza artificiale possa contribuire a trasformare la realtà complessa del long COVID in informazioni più chiare e utili per pazienti e clinici.
Citazione: Walders, J., Wetz, S., Costa, A.S. et al. Longitudinal modeling of Post-COVID-19 condition over three years: A machine learning approach using clinical, neuropsychological, and fluid markers. Sci Rep 16, 6517 (2026). https://doi.org/10.1038/s41598-026-37635-3
Parole chiave: long COVID, machine learning, infiammazione, sintomi cognitivi, biomarcatori immunitari