Clear Sky Science · it
Impronta DNS basata sull’attività dell’utente
Perché le tue visite web lasciano una traccia nascosta
Ogni volta che navighi sul web, il tuo computer interroga silenziosamente un tipo speciale di rubrica, chiamata Domain Name System (DNS), per sapere come raggiungere ogni sito. Quelle richieste non svaniscono. Nel corso di giorni e settimane formano un modello di quali tipi di siti visiti, quando e con quale frequenza. Questo studio mostra che tali schemi sono sufficientemente distintivi da funzionare come un’impronta comportamentale, permettendo ad algoritmi potenti di distinguere gli utenti — anche se il loro indirizzo IP visibile cambia — sollevando sia opportunità per la sicurezza sia seri interrogativi sulla privacy.
La rubrica di Internet e le tue abitudini
Il DNS serve a tradurre indirizzi web leggibili dalle persone, come www.google.com, negli indirizzi numerici IP che i computer usano per comunicare. La maggior parte delle persone non ci pensa mai, ma ogni ricerca, flusso video, controllo della posta o aggiornamento di un’app genera una o più query DNS. Queste query sono tipicamente gestite da server DNS locali o pubblici e registrate come semplici record: quale indirizzo IP ha chiesto di quale dominio e quando. Se si accumulano abbastanza di questi record si ottiene un quadro dettagliato dei tipi di servizi online su cui un utente fa affidamento, dagli strumenti di lavoro e lo storage cloud ai social network e alle piattaforme di streaming. Mentre ricerche precedenti hanno usato queste tracce per individuare malware o identificare tipi di dispositivi, questo studio pone una domanda più diretta: possono esse individuare singoli utenti o macchine esclusivamente dal loro comportamento ricorrente nel DNS?
Trasformare i clic quotidiani in un’impronta comportamentale
Gli autori si basano su un ampio dataset DNS disponibile pubblicamente, raccolto da un provider internet locale per tre mesi. Ogni giorno aggregano l’attività DNS per ogni indirizzo IP attivo in un sommario compatto: il numero totale di query, quante diverse domain sono state contattate e, cosa cruciale, come quei domini si distribuiscono in 75 categorie di contenuto come “General Business”, “Software / Hardware” o “Social Networking”. Mantengono solo gli indirizzi IP che compaiono almeno nell’80 percento dei giorni, garantendo una storia sufficiente per ogni utente, e rimuovono con cura caratteristiche ridondanti o quasi vuote. Applicano anche strumenti statistici per rilevare campi altamente correlati, filtrare outlier estremi nel volume delle query e poi comprimono i dati con l’analisi delle componenti principali in modo che la maggior parte della variazione utile sia preservata in molte meno dimensioni. Visualizzando i dati ripuliti con una tecnica chiamata t‑SNE, osservano che molti indirizzi IP formano cluster stretti e ben separati — un segnale iniziale che la classificazione automatica potrebbe essere fattibile.
Mettere alla prova i modelli di apprendimento automatico
Con questo dataset elaborato, il team tratta l’identificazione dell’utente come un enorme problema di classificazione: dato un giorno di statistiche DNS, decidere a quale dei 1.727 indirizzi IP appartiene. Confrontano una serie di modelli, da metodi classici come Naive Bayes e Random Forest fino a strumenti più avanzati come XGBoost e reti neurali profonde. Ogni modello è addestrato e validato su diverse versioni dei dati (grezzi, riscalati, standardizzati o con riduzione di dimensione) e valutato in base a quanto spesso assegna correttamente la classe giusta, insieme a misure di precisione e richiamo. I modelli tradizionali si comportano abbastanza bene — Random Forest raggiunge circa il 73 percento di accuratezza, e XGBoost supera l’81 percento distinguendo correttamente più del 99 percento di tutte le classi. Ma i migliori risultati arrivano dalle reti neurali, in particolare una rete neurale convoluzionale (CNN) personalizzata che tratta il vettore di caratteristiche come un’immagine unidimensionale del comportamento giornaliero.
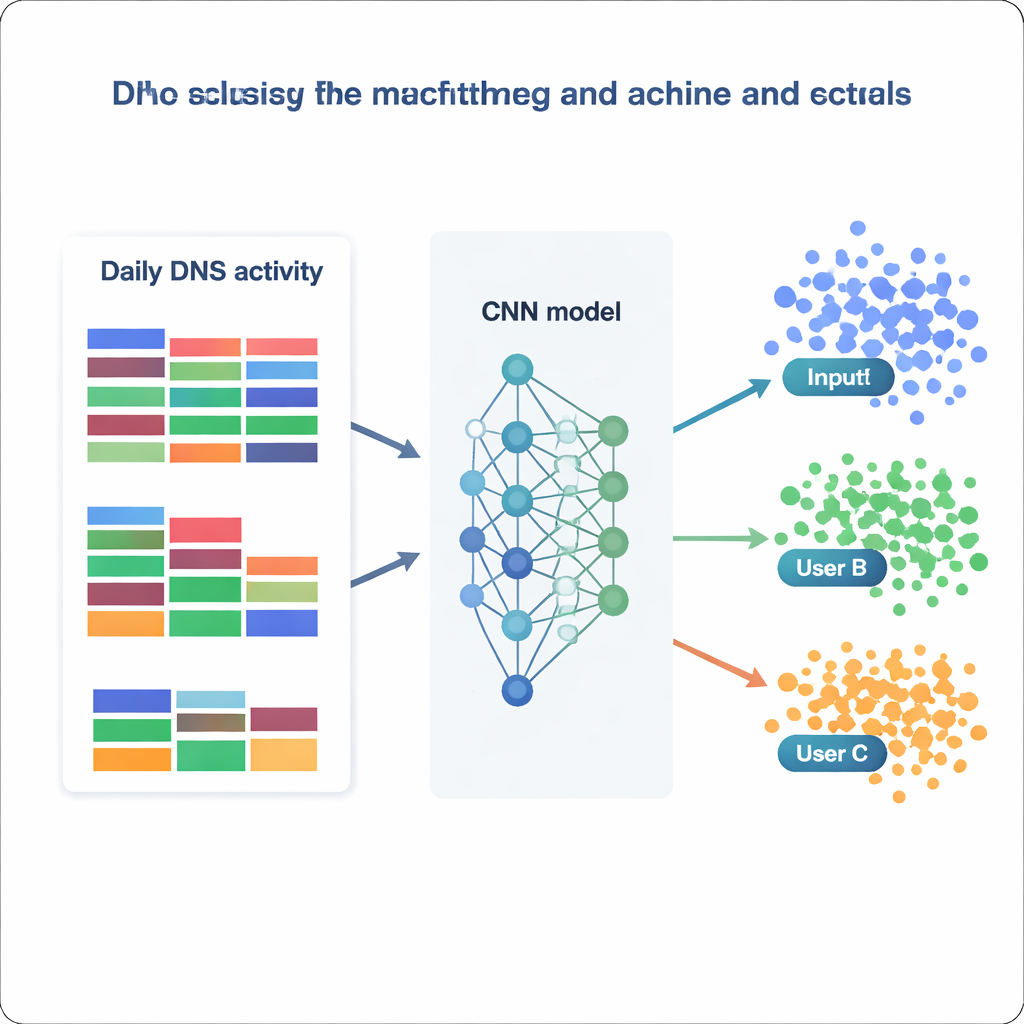
Quanto bene può un modello sapere “chi” sei?
La migliore CNN, addestrata su dati normalizzati, identifica correttamente l’IP sorgente in quasi l’87 percento dei giorni tenuti da parte e predice con successo 1.694 dei 1.727 indirizzi IP distinti. In termini pratici, questo significa che la maggior parte degli utenti — o piccoli gruppi nascosti dietro un IP condiviso — mostra schemi DNS stabili e riconoscibili nel tempo. Esaminando quali caratteristiche i modelli usano maggiormente, gli autori individuano due strategie complementari. Alcuni modelli si affidano pesantemente a categorie molto comuni, come servizi business generali o software, catturando abitudini ampie. Altri, come XGBoost, guadagnano potere extra da categorie rare ma indicative legate alla sicurezza, alla politica o a interessi di nicchia. Nel complesso, questi risultati mostrano che anche statistiche semplici e aggregate — senza esaminare l’elenco completo dei nomi di dominio — possono codificare abbastanza struttura da ri-identificare gli utenti con sorprendente affidabilità.
Promesse, limiti e posta in gioco per la privacy
Per le forze dell’ordine e i difensori della rete, le impronte DNS potrebbero diventare uno strumento prezioso per tracciare recidivi, individuare macchine compromesse o rilevare botnet che usano indirizzi IP variabili per eludere i blocchi. Allo stesso tempo, lo studio evidenzia limiti chiari: le impronte DNS sono più stabili quando un IP pubblico è legato a un singolo utente, condizione più realistica nelle reti IPv6 moderne rispetto all’attuale mondo IPv4 in cui molti utenti condividono un indirizzo tramite NAT. Il cambio frequente di server DNS o l’uso di Wi‑Fi pubblico indebolisce inoltre il segnale. Soprattutto, il lavoro sottolinea un rischio per la privacy che è difficile da percepire per gli utenti comuni. Poiché il logging DNS è in gran parte invisibile e passivo, il tracciamento comportamentale può avvenire senza installare cookie o script intrusivi. Gli autori rilasciano apertamente il loro dataset e i modelli, sostenendo che la ricerca trasparente è necessaria affinché la società possa bilanciare i benefici per la sicurezza della fingerprinting basata su DNS rispetto al suo potenziale di sorveglianza silenziosa e decidere quali protezioni e politiche debbano governare questa potente nuova forma di identificazione online.
Citazione: Morozovič, D., Konopa, M. & Fesl, J. DNS fingerprint based on user activity. Sci Rep 16, 7314 (2026). https://doi.org/10.1038/s41598-026-37631-7
Parole chiave: impronte DNS, tracciamento utenti, privacy su Internet, sicurezza di rete, apprendimento automatico