Clear Sky Science · it
Super-risoluzione di volti reali basata su reti generative avversarie e di allineamento facciale
Volti più nitidi a partire da foto sfocate
Chiunque abbia provato a ingrandire il volto in un vecchio video di sorveglianza o in una piccola foto dei social sa quanto sia frustrante: più si ingrandisce, più il volto si trasforma in una macchia pixellata. Questo articolo presenta un nuovo approccio di intelligenza artificiale in grado di trasformare immagini facciali di bassa qualità del mondo reale in versioni molto più nitide, conservando meglio l'identità e l'espressione della persona. Le implicazioni sono evidenti per telecamere di sicurezza, analisi forense delle foto e perfino per app quotidiane di miglioramento delle immagini.
Perché è così difficile riparare volti sfocati
Far sembrare nitida un'immagine facciale piccola e sfocata non è solo una questione di «aggiungere pixel». I metodi tradizionali si basavano su regole manuali o schemi semplici, e le tecniche di deep learning più recenti spesso apprendono da immagini degradate artificialmente: si prende un volto pulito ad alta risoluzione, lo si sfoca e riduce, poi si insegna a una rete a invertire il processo. Il problema è che le immagini del mondo reale—come quelle delle telecamere di sorveglianza o dei video compressi—sono degradate in modi disordinati e imprevedibili. Sfocatura, rumore e artefatti di compressione raramente corrispondono ai puliti esempi sintetici usati in fase di addestramento, quindi modelli che funzionano bene in laboratorio spesso falliscono su filmati reali. Peggio ancora, possono creare volti che appaiono plausibili ma non somigliano più alla persona originale.
Un ciclo di apprendimento bidirezionale per immagini reali
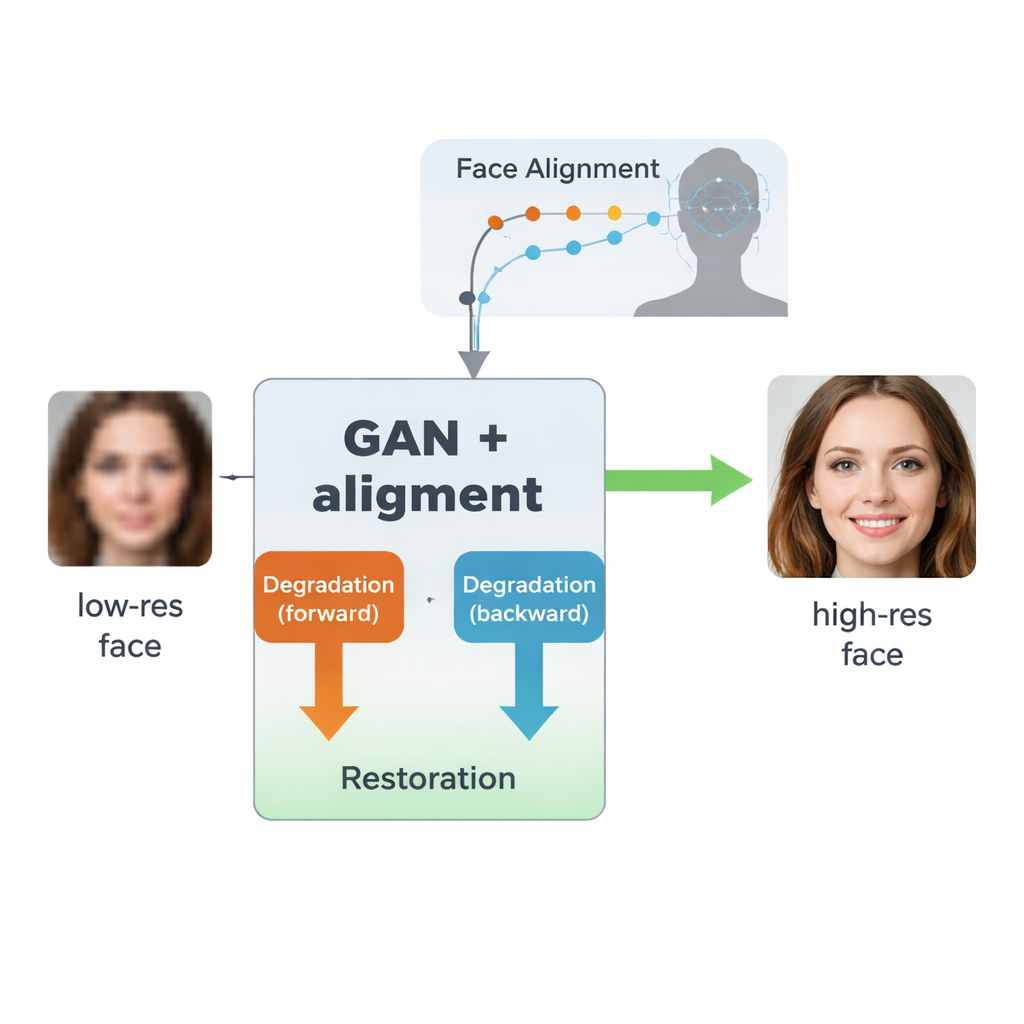
Gli autori si basano su un tipo di IA chiamata rete generativa avversaria (GAN), che impara a creare immagini realistiche mettendo in competizione due reti neurali: una genera immagini, l'altra valuta quanto appaiono reali. La loro architettura, ispirata a un modello precedente chiamato SCGAN, usa una struttura a «semi-ciclo» con due loop complementari. Nel loop in avanti, volti reali ad alta risoluzione vengono intenzionalmente degradati da un ramo per produrre versioni sintetiche a bassa risoluzione, poi restaurati da un ramo di restauro condiviso. Nel loop all'indietro, volti realmente di scarsa qualità del mondo reale vengono migliorati dallo stesso ramo di restauro e poi degradati nuovamente da un altro ramo per assomigliare a immagini reali a bassa risoluzione. Forzando la coerenza in entrambe le direzioni—degradare poi restaurare, o restaurare poi degradare—il sistema apprende un modello realistico di come i volti si deteriorano nella pratica e come invertire quel processo senza mai aver bisogno di coppie perfettamente abbinate di immagini reali a bassa e alta qualità.
Insegnare alla rete com'è davvero un volto
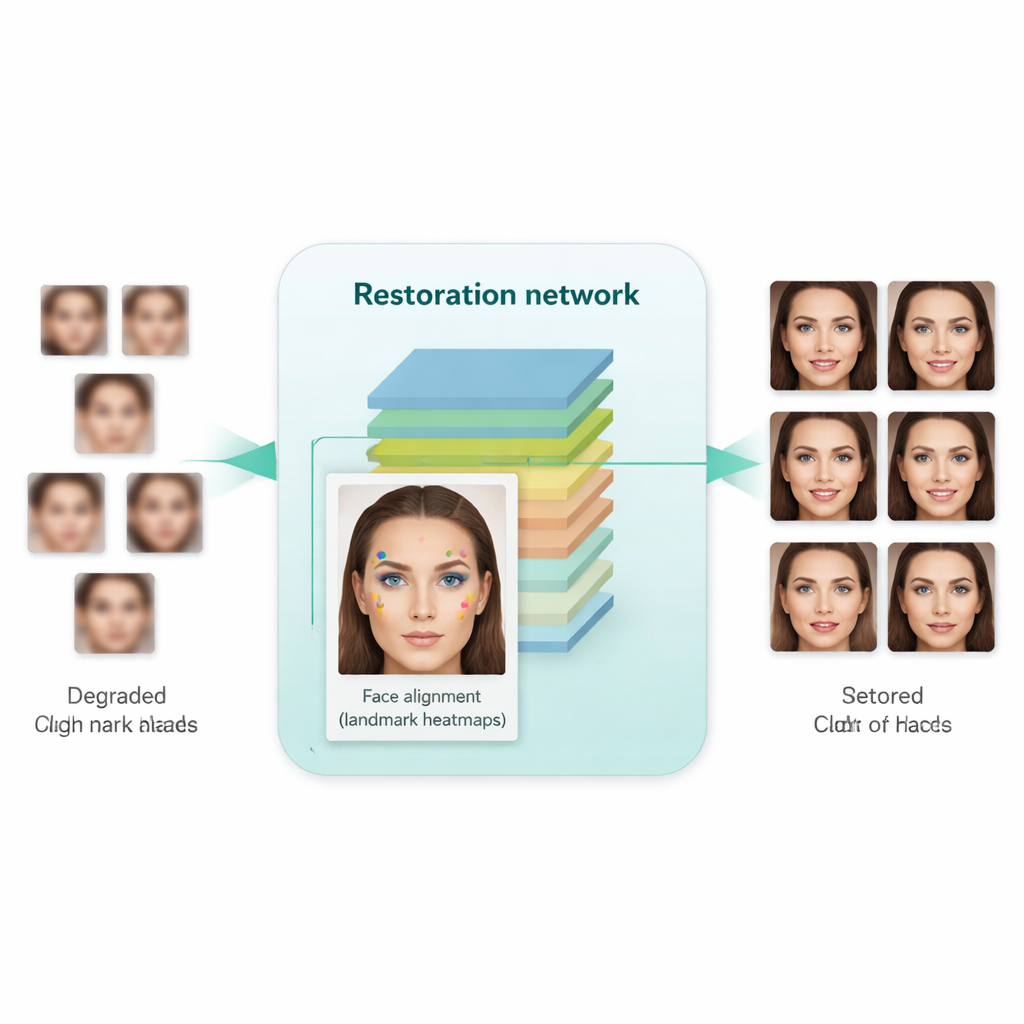
Una innovazione chiave in questo lavoro è insegnare al sistema non solo a rendere le immagini più nette, ma a rispettare la struttura sottostante del volto umano. Per farlo, gli autori integrano una rete separata di allineamento facciale, originariamente progettata per localizzare punti di riferimento come gli angoli degli occhi, la punta del naso e il contorno della bocca. Questa rete di allineamento predice «mappe di calore» che evidenziano dove ciascun punto dovrebbe trovarsi. Durante l'addestramento, il modello confronta le mappe di calore dell'immagine restaurata con quelle di un volto reale ad alta risoluzione della stessa persona e penalizza le discrepanze. Cruciale è che si utilizzi un modello di allineamento pre-addestrato e non siano necessarie etichette manuali per i punti di riferimento in ogni immagine di addestramento. Il risultato è una sorta di guida geometrica: la rete di miglioramento viene spinta a collocare occhi, naso e bocca nelle posizioni e nelle forme corrette, invece di limitarsi a dipingere sulla sfocatura texture generiche simili a un volto.
Quanto funziona bene nella pratica?
I ricercatori hanno addestrato il loro sistema su una vasta raccolta di volti di alta qualità e su un insieme separato di volti veramente di bassa qualità provenienti da dataset del mondo reale. Lo hanno poi testato sia su benchmark sintetici (dove sono disponibili immagini di riferimento pulite) sia su immagini reali (dove si possono usare solo valutazioni visive e misure statistiche). Rispetto ai metodi precedenti—inclusi strumenti noti come Real-ESRGAN, GFPGAN e l'SCGAN originale—il nuovo approccio ha prodotto immagini che non solo apparivano più naturali e meno distorte, ma hanno anche migliorato le prestazioni in compiti pratici. Quando le immagini migliorate sono state elaborate da rilevatori di volti standard e da un modello popolare di riconoscimento facciale (FaceNet), l'accuratezza di rilevamento e verifica è aumentata in modo significativo, indicando che i dettagli legati all'identità erano meglio preservati. Allo stesso tempo, metriche automatiche di qualità suggerivano che i volti generati erano più vicini per distribuzione alle fotografie reali ad alta risoluzione.
Cosa significa per l'uso quotidiano
In termini semplici, questo lavoro mostra che è possibile ottenere volti più nitidi e più affidabili da immagini di scarsa qualità combinando due idee: apprendere un modello realistico di come le immagini vengono rovinate nel mondo reale e usare informazioni sui punti di riferimento facciali per mantenere intatta la struttura del volto. Invece di limitarsi a «indovinare» un volto dall'aspetto migliore, il sistema è guidato a ricostruire la persona giusta con occhi, bocca e forma complessiva più chiari. Questo rende il metodo particolarmente promettente per applicazioni come sicurezza, forense e restauro d'archivio, dove sia la chiarezza visiva sia l'identità corretta sono fondamentali e dove le versioni originali ad alta qualità delle immagini sono raramente disponibili.
Citazione: Fathy, H., Faheem, M.T. & Elbasiony, R. Real-world face super-resolution based on generative adversarial and face alignment networks. Sci Rep 16, 7492 (2026). https://doi.org/10.1038/s41598-026-37573-0
Parole chiave: super-risoluzione del volto, reti generative avversarie, allineamento facciale, riconoscimento facciale, restauro dell'immagine