Clear Sky Science · it
Pipeline di elaborazione delle immagini per la caratterizzazione di megalibrerie di nanoparticelle guidata dall'IA
Perché le particelle minuscole hanno bisogno dell'aiuto dei big data
La scienza dei materiali moderna fa sempre più affidamento sulla produzione e sul test di enormi numeri di particelle minime per scoprire catalizzatori, batterie e altri materiali avanzati migliori. Nuovi metodi possono ora far crescere milioni di nanoparticelle diverse su un unico chip, ma verificare la qualità di ciascuna tramite microscopio genera molte più immagini di quante un essere umano possa ragionevolmente esaminare. Questo articolo descrive come i ricercatori abbiano costruito una pipeline automatizzata di elaborazione delle immagini e IA che smista rapidamente immagini di nanoparticelle “buone” da quelle “cattive”, riducendo i costi computazionali e accelerando gli esperimenti mantenendo decisioni altamente affidabili.
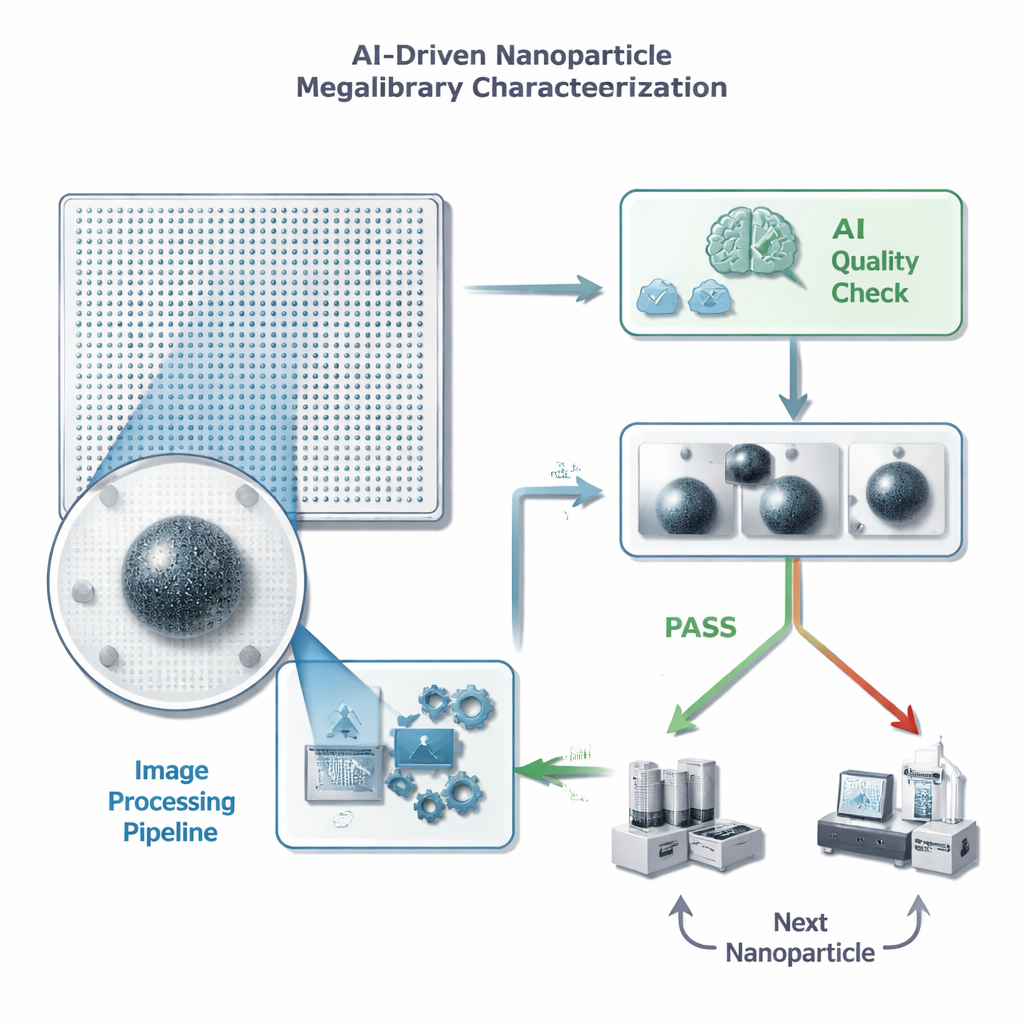
Dalle immagini infinite a decisioni rapide
Ogni nanoparticella in un chip a “megalibreria” si trova in una posizione nota e può essere ripresa con un microscopio elettronico. Prima che gli scienziati investano tempo e misure di follow-up costose su una singola particella, serve un controllo qualità rapido: c'è esattamente una particella ben messa a fuoco nel riquadro, senza ingombri o artefatti che distraggano? Gli autori inquadrano questo come un semplice compito di superamento/scarto per un modello di machine learning, ma con limiti stringenti sul tempo che può impiegare per immagine—meno di mezzo secondo, perché un singolo chip può contenere milioni di particelle. Sottolineano inoltre che i falsi positivi sono particolarmente dannosi: se l'IA accetta per errore un'immagine scadente, spreca tempo e spazio di archiviazione in misure dettagliate inutili, mentre la perdita occasionale di una buona particella è meno dannosa per il progresso complessivo.
Ripulire la visuale prima che l'IA guardi
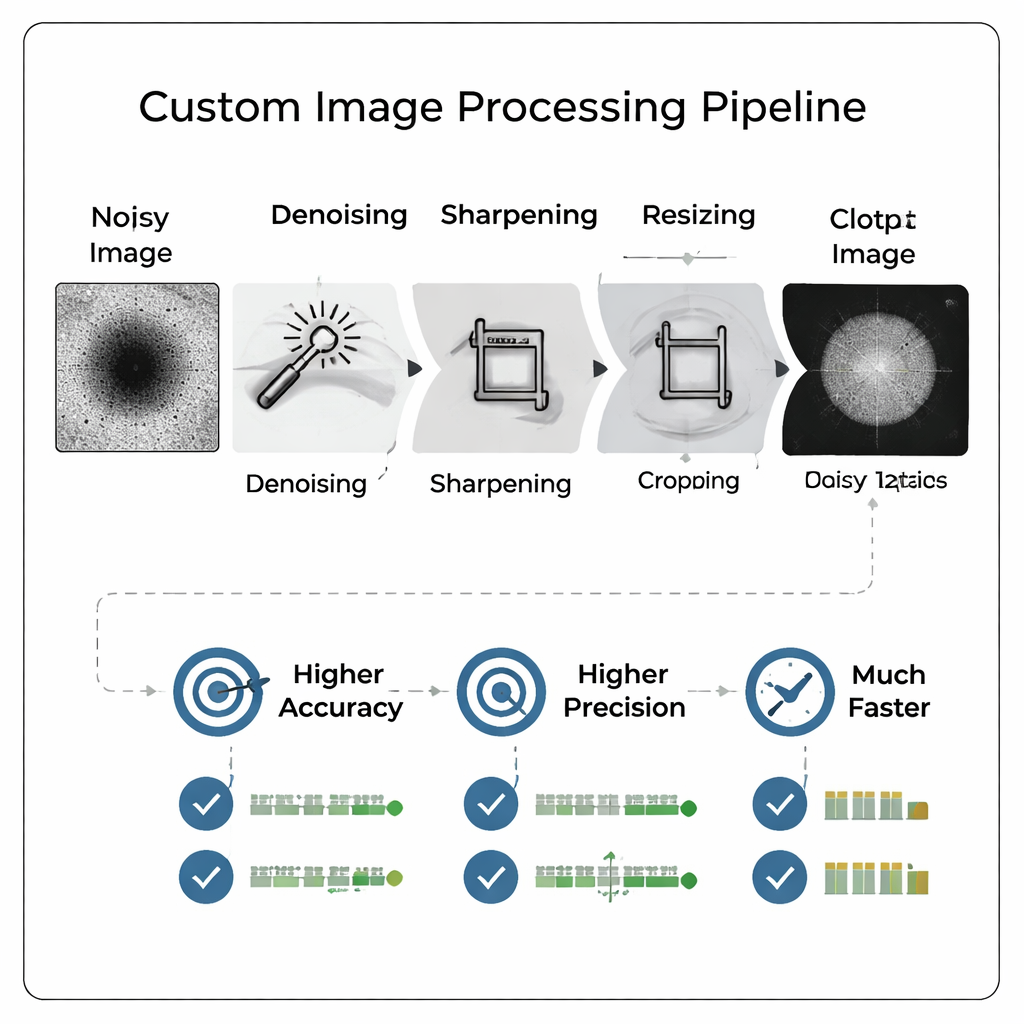
Invece di immettere immagini microscopiche grezze e rumorose direttamente in una grande e complessa rete neurale, il team ha progettato una pipeline di elaborazione delle immagini su misura che prima “ripulisce” le immagini. La pipeline rimuove il rumore di fondo, enfatizza i bordi, ritaglia strettamente intorno alla particella e poi riduce l'immagine a una dimensione molto più piccola. In modo cruciale, questo pre-processamento rende più visibili caratteristiche deboli e imita l'aspetto di un'immagine a ingrandimento maggiore senza dover riprendere il campione. Il risultato è un'immagine compatta ad alto contrasto che può essere fornita a una rete neurale relativamente semplice, riducendo sia i tempi di addestramento che le esigenze di archiviazione pur preservando i dettagli rilevanti per le valutazioni di qualità.
Immagini più intelligenti battono modelli più grandi
I ricercatori hanno confrontato in modo rigoroso molte varianti di pipeline e risoluzioni, addestrando in definitiva 800 modelli diversi per valutare come dimensione e processo delle immagini influenzino le prestazioni. Hanno riscontrato che immagini accuratamente elaborate a risoluzioni moderate (come 128×128 pixel) permettono a una piccola rete neurale convoluzionale di superare un modello precedente molto più grande che era stato trovato tramite ricerca automatica di architettura e addestrato su immagini complete da 512×512. L'accuratezza è migliorata di oltre 13 punti percentuali, mentre il recall—la capacità di individuare correttamente le particelle buone—in è aumentato di più di 18 punti percentuali. La precisione, la misura chiave per evitare sforzi sprecati su particelle cattive, ha raggiunto circa il 96 percento, e anche la metrica combinata preferita dagli autori è migliorata.
Fare di più con molti meno dati
Uno dei risultati più sorprendenti è che l'elaborazione conta più delle dimensioni grezze dell'immagine. Quando il team ha confrontato modelli addestrati su immagini semplicemente “ridotte di scala” rispetto a quelli che usavano l'intera pipeline personalizzata, le immagini processate hanno vinto costantemente—anche quando ridotte a dimensioni estremamente piccole come 16×16 pixel. In effetti, il miglior modello che usava immagini processate 16×16 ha superato il miglior modello con immagini non processate 128×128 su quasi tutte le metriche. La pipeline è stata inoltre più utile alle ingrandimenti microscopici più bassi, dove le immagini sono normalmente più difficili da interpretare. Poiché le immagini a ingrandimento minore sono più rapide da acquisire, questo significa che i laboratori possono scansionare i chip più velocemente senza sacrificare la qualità delle decisioni.
Decisioni più rapide per laboratori a guida autonoma
Combinando un’elaborazione intelligente delle immagini con un modello IA snello, gli autori hanno ridotto i tempi di addestramento da molte ore su un supercomputer a meno di un minuto su un singolo processore grafico. Una volta addestrato, il sistema può elaborare e classificare una nuova immagine in circa 75 millisecondi, ben al di sotto dell'obiettivo di 500 millisecondi e molto più veloce di un revisore umano. In termini pratici, questo si traduce in uno screening rapido e affidabile delle megalibrerie di nanoparticelle, aiutando i ricercatori a concentrare strumenti costosi sui candidati più promettenti. Man mano che i laboratori evolvono verso sistemi di scoperta sempre più automatizzati e “a guida autonoma”, approcci come questo—ripulire prima i dati e poi applicare un'IA snella—offrono un modo potente per trasformare flussi di immagini travolgenti in intuizioni scientifiche praticabili.
Citazione: Day, A.L., Wahl, C.B., dos Reis, R. et al. Image processing pipeline for AI-driven nanoparticle megalibrary characterization. Sci Rep 16, 7675 (2026). https://doi.org/10.1038/s41598-026-37566-z
Parole chiave: nanoparticelle, elaborazione delle immagini, apprendimento automatico, scoperta di materiali, microscopia elettronica