Clear Sky Science · it
Ricerca su moduli plug-and-play per potenziare la correlazione delle etichette nell’apprendimento profondo multi-etichetta
Insegnare alle macchine a gestire troppe etichette
Negozi online, archivi legali e banche dati mediche fanno tutti affidamento su software in grado di etichettare rapidamente ogni nuovo documento con le etichette appropriate. Ma i sistemi moderni spesso devono affrontare decine di migliaia, o persino milioni, di possibili etichette — dalle categorie di prodotto agli argomenti medici — mentre ogni testo richiede solo una manciata di etichette. Questo articolo presenta un nuovo componente aggiuntivo, chiamato Label Correlation Enhancement Network (LCENet), che aiuta i modelli di deep learning esistenti a sfruttare meglio il modo in cui le etichette compaiono insieme nei dati reali, portando a una etichettatura dei testi più accurata e più rapida.
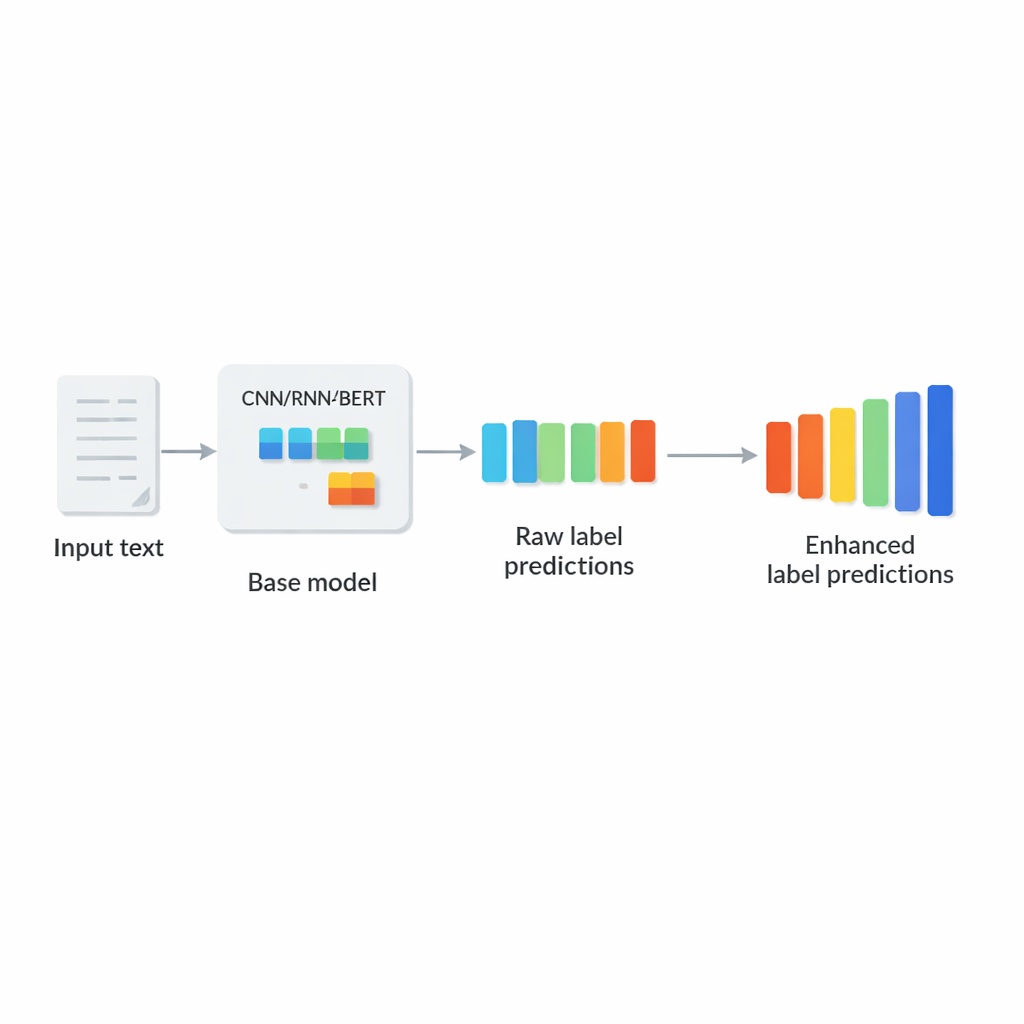
Perché etichettare su scala web è così difficile
Molte applicazioni reali rientrano in quella che i ricercatori chiamano classificazione testuale multi-etichetta estrema: dato un breve riassunto o un documento lungo, il sistema deve scegliere un piccolo sottoinsieme di etichette pertinenti da un catalogo enorme. Esempi includono l’assegnazione di categorie ai prodotti su un sito di e-commerce, l’indicizzazione di articoli biomedici con termini MeSH, l’abbinamento di annunci a pagine web o il mapping di testi legali a codici giuridici dettagliati. Questi scenari condividono tre sfide: l’elenco delle etichette è estremamente ampio, la maggior parte delle etichette è rara e ogni testo usa solo poche etichette. Le tecniche tradizionali o dividono il problema in molti classificatori piccoli oppure comprimono le etichette in vettori a dimensione inferiore, ma spesso si basano su semplici conteggi di parole e non catturano pienamente il significato o le relazioni fra etichette.
Ciò che ai modelli deep standard sfugge ancora
Gli approcci di deep learning moderni, come reti convoluzionali, reti ricorrenti e modelli basati su Transformer come BERT, hanno migliorato notevolmente la comprensione del testo imparando rappresentazioni semantiche ricche. Eppure quasi tutti fanno una semplificazione cruciale nell’ultimo passaggio: una volta che il testo è codificato in un vettore, prevedono ogni etichetta in modo indipendente. In pratica, però, le etichette interagiscono fortemente. Un articolo medico etichettato con “diabete” ha più probabilità di coinvolgere anche “resistenza all’insulina”, e un dispositivo etichettato “smartphone” è solitamente correlato a “elettronica” e “dispositivi di comunicazione”. Ignorare questi schemi significa che i modelli non possono usare etichette ad alta confidenza per sostenere quelle più deboli, e possono perfino produrre combinazioni che non hanno senso insieme.
Un plug-in che apprende le relazioni tra etichette
Gli autori propongono LCENet come un modulo leggero, plug-and-play, che si colloca dopo qualsiasi classificatore testuale profondo esistente. Invece di cambiare il modo in cui il modello di base legge il testo, LCENet prende i punteggi grezzi delle etichette prodotti e li fa passare attraverso un compatto “collo di bottiglia” che costringe il sistema a scoprire una rappresentazione a bassa dimensione in cui le etichette correlate si raggruppano. Funzioni di attivazione non lineari permettono al modulo di catturare associazioni complesse di ordine superiore, non solo semplici legami a coppie. Una connessione residuale, o skip connection, inoltra i punteggi originali direttamente all’output insieme ai punteggi corretti, stabilizzando l’addestramento e garantendo che l’elemento aggiuntivo non possa facilmente peggiorare le cose. Cruciale è che LCENet riduce il numero di parametri aggiuntivi da qualcosa che crescerebbe con il quadrato del numero di etichette a una crescita molto più gestibile e lineare, rimanendo quindi fattibile anche per centinaia di migliaia di etichette.
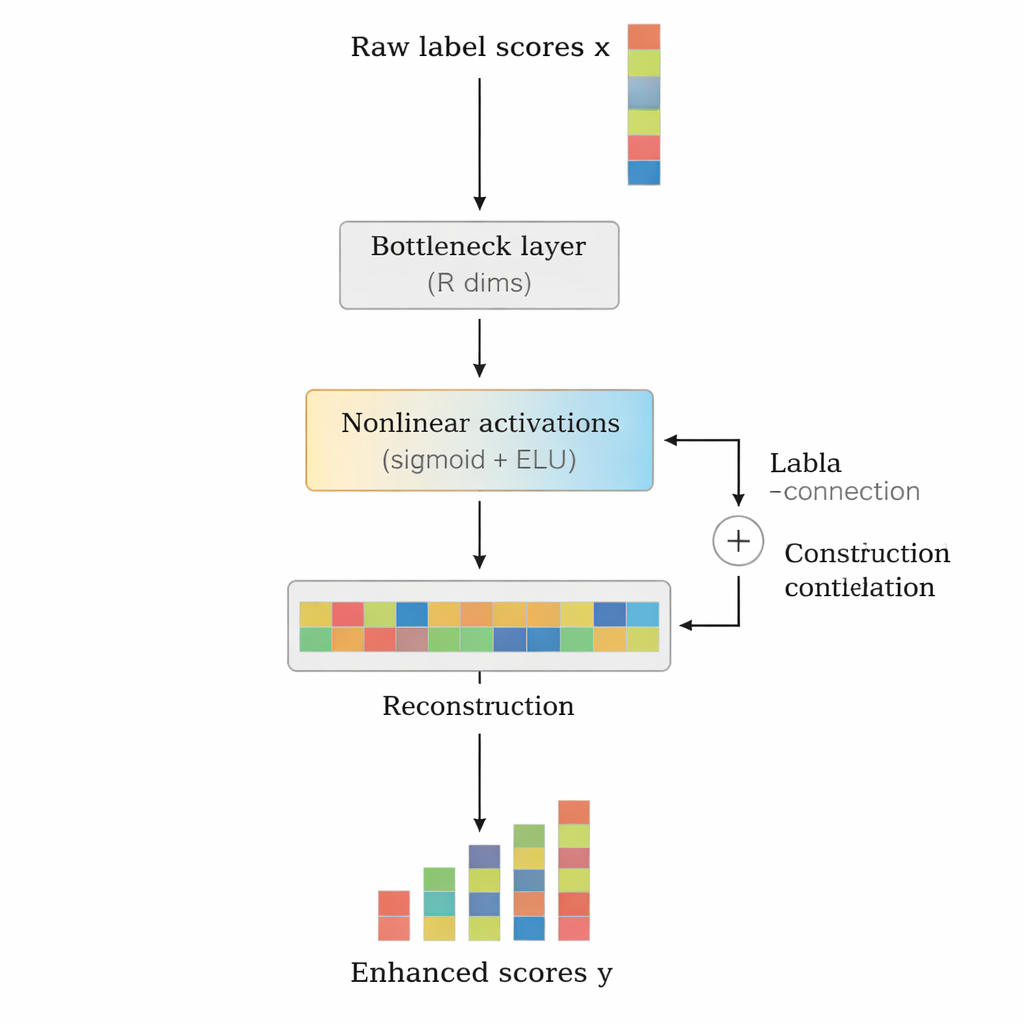
Dimostrare i benefici su modelli e dataset diversi
Per verificare se LCENet è davvero generale, gli autori lo hanno collegato a quattro modelli profondi molto diversi, incluse architetture basate su CNN e su BERT, oltre a sistemi progettati specificamente per contesti biomedici ed estremi. Hanno valutato queste combinazioni su tre dataset di riferimento pubblici: un corpus legale europeo (EUR-Lex), un dataset di prodotti Amazon (AmazonCat-13K) e una massiccia collezione di Wikipedia con oltre mezzo milione di etichette (Wiki-500K). Su tutti i modelli, i dataset e sei metriche focalizzate sul ranking, LCENet ha costantemente migliorato le prestazioni, talvolta aumentando la precisione top-1 di oltre cinque punti percentuali sul dataset più grande. Le curve di addestramento hanno inoltre mostrato che LCENet spesso dimezza il numero di passi di addestramento necessari per raggiungere una certa accuratezza, perché la struttura di correlazione delle etichette aggiunta fornisce segnali di apprendimento più chiari fin dall’inizio.
Perché questo conta per i sistemi di tutti i giorni
Per i praticanti che già si affidano a modelli deep per etichettare testi, LCENet offre un modo pratico per migliorare accuratezza e velocità di addestramento senza riprogettare i sistemi o raccogliere nuovi tipi di annotazioni. Tratta lo spazio delle etichette come una fonte di conoscenza, imparando quali tag tendono a muoversi insieme o si escludono a vicenda, e poi spingendo le previsioni di conseguenza. Pur essendo sviluppata per il testo, la stessa idea di potenziare le previsioni sfruttando relazioni apprese tra output potrebbe essere applicata a immagini, dati multimodali e altri compiti di previsione strutturata. In termini semplici, LCENet aiuta le macchine a “ricordare” come le etichette si relazionano, così che indovinino meno come caselle isolate e più come un essere umano informato che comprende come i concetti si incastrano tra loro.
Citazione: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
Parole chiave: classificazione testuale multi-etichetta estrema, correlazione delle etichette, apprendimento profondo, classificazione di testi, reti neurali