Clear Sky Science · it
DMSCA: attenzione dinamica canale-spaziale multi-scala per una rappresentazione delle feature migliorata nelle reti neurali convoluzionali
Insegnare ai computer a prestare migliore attenzione
I sistemi moderni di riconoscimento delle immagini possono individuare gatti, segnali stradali e tumori nelle scansioni, ma non sempre sanno su cosa concentrarsi all’interno di un’immagine. Questo articolo presenta un nuovo modo per aiutare tali sistemi a concentrarsi sulle parti più importanti dell’immagine, migliorando la precisione e rendendoli più affidabili nelle condizioni disordinate della vita reale. Il metodo, chiamato Dynamic Multi-Scale Channel-Spatial Attention (DMSCA), si integra nelle reti neurali convoluzionali esistenti e le aiuta a interpretare in modo più intelligente sia il “cosa” sia il “dove” in un’immagine.
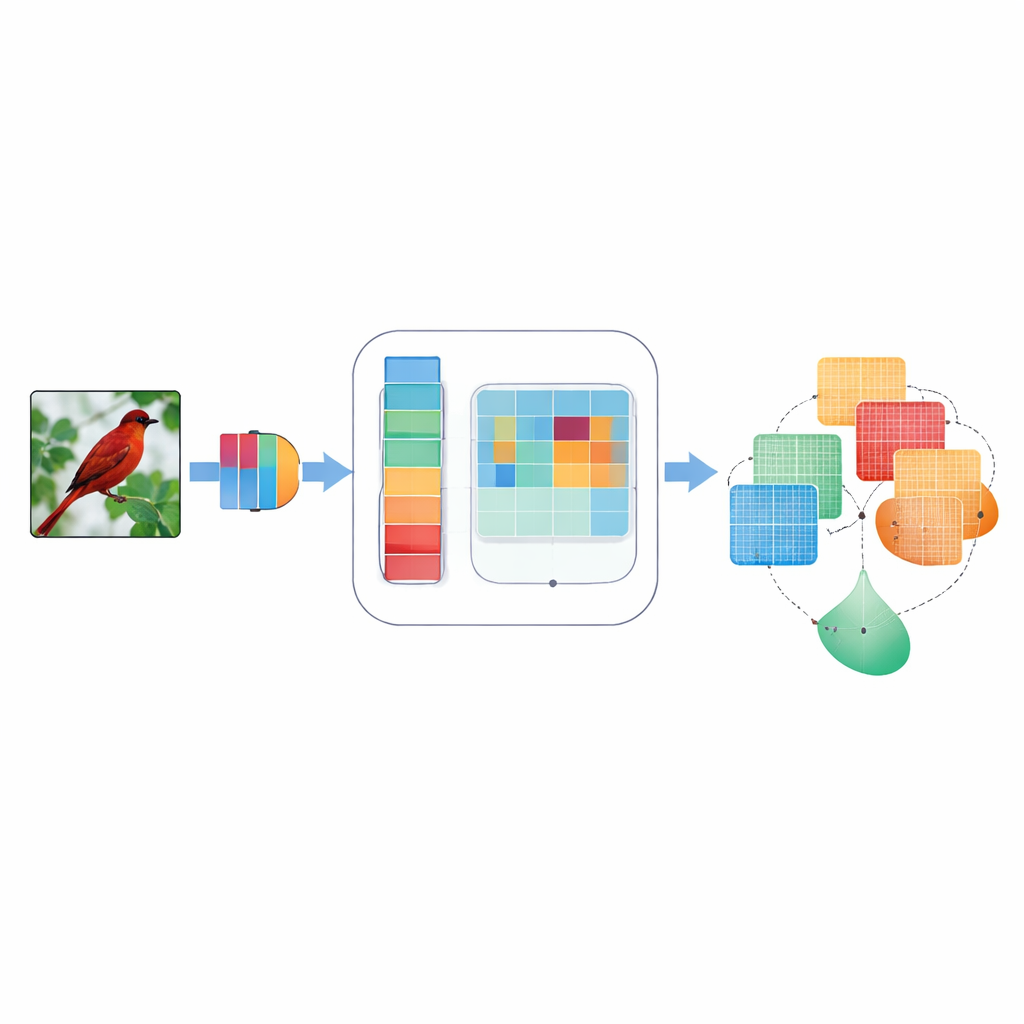
Perché concentrarsi conta nella visione artificiale
Le reti neurali convoluzionali, i cavalli di battaglia di molte applicazioni di visione, trattano normalmente ogni segnale interno come ugualmente importante. Ciò significa che un bordo tenue dell’ala di un uccello e una porzione di cielo possono ricevere un’attenzione simile, anche se solo il primo aiuta a identificare la specie. I precedenti metodi di “attenzione” cercavano di correggere questo pesando alcuni segnali interni più di altri — sia attraverso canali simili al colore sia sulla disposizione bidimensionale dell’immagine. Ma quei metodi spesso usavano regole fisse, progettate a mano, consideravano un solo livello di dettaglio per volta o combinavano le informazioni in modo rigido che non si adattava alle diverse immagini. Di conseguenza, talvolta perdeva dettagli fini, ignoravano direzioni come “orizzontale vs verticale” o faticavano quando le immagini erano rumorose o sfocate.
Un componente di attenzione più intelligente
DMSCA è progettato come un modulo piccolo e collegabile che può essere inserito in reti note come ResNet senza modificarne la struttura complessiva. All’interno coordina sei parti strettamente connesse che lavorano insieme anziché in isolamento. Una parte riassume l’intera immagine per catturare ciò che accade a livello globale, mentre un’altra impara quanto debba contare ciascun canale interno, usando una “temperatura” controllabile che può rendere le decisioni più nette o più morbide a seconda delle necessità. Sul fronte spaziale, DMSCA usa contemporaneamente diverse dimensioni di finestra per catturare sia texture minute sia forme più grandi, e presta esplicitamente attenzione alle direzioni orizzontali e verticali così che bordi lunghi o strisce non vengano annullati. Infine, invece di sommare semplicemente questi segnali, il modulo impara, pixel per pixel, quanto affidarsi all’informazione del “cosa” proveniente dai canali rispetto a quella del “dove” proveniente dallo spazio.
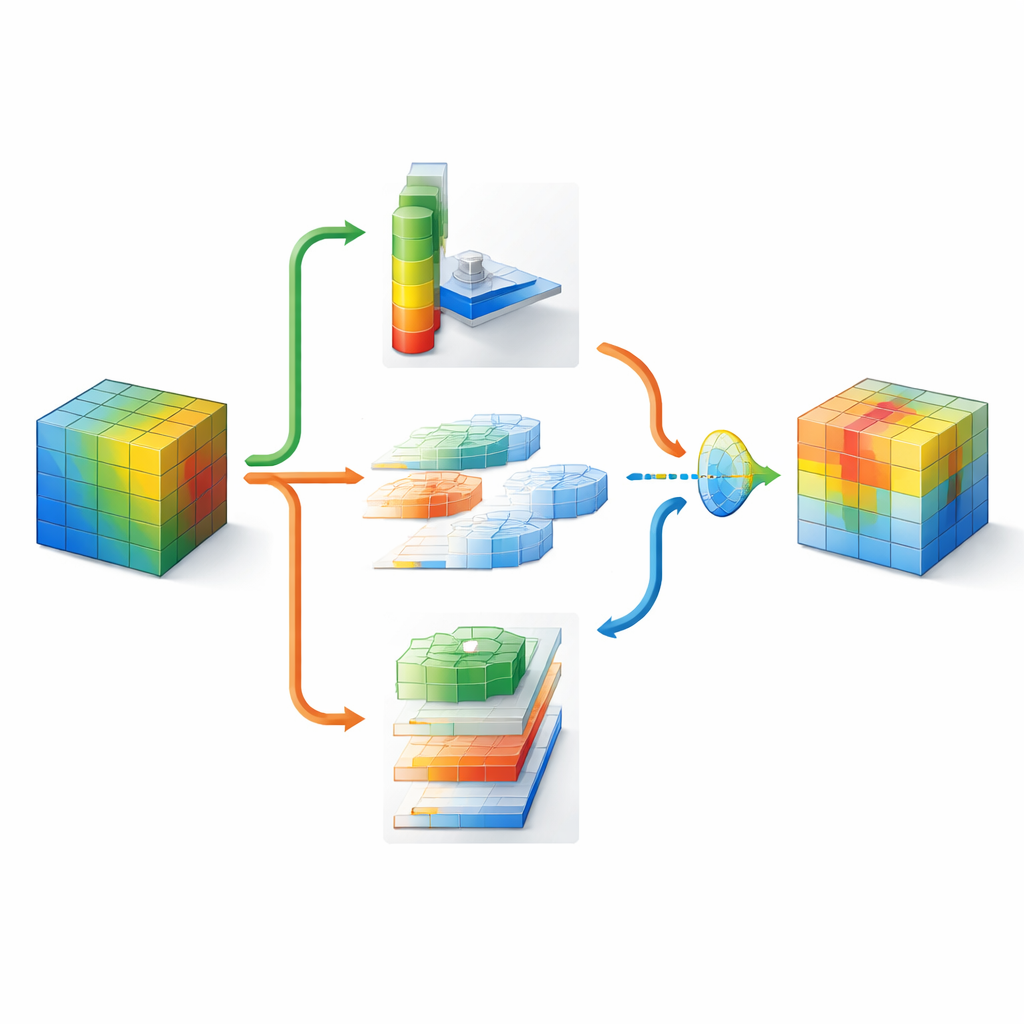
Osservare le immagini a molte scale e direzioni
Per capire dove guardare in un’immagine, DMSCA comprime prima i molti canali interni in una mappa compatta a due livelli che evidenzia sia le tendenze di background sia le caratteristiche salienti. Passa poi questa mappa attraverso diversi filtri paralleli di varie dimensioni. I filtri piccoli cogliono dettagli fini come pelliccia o piume, mentre quelli più grandi catturano forme come teste o corpi interi. In parallelo, un’unità direzionale scansiona righe e colonne separatamente, preservando la posizione esatta delle strutture importanti. Queste viste orizzontali e verticali possono poi interagire, così che un segnale verticale forte, per esempio, possa rinforzare le posizioni orizzontali corrette. Il risultato è una mappa di attenzione ricca che dice alla rete non solo che qualcosa è importante, ma dove si trova e a quale scala.
Lasciare che la rete decida cosa conta di più
Poiché diverse parti di un’immagine possono richiedere strategie differenti, DMSCA non impone una ricetta fissa per combinare informazioni di canale e spaziali. Invece costruisce un piccolo “cancello” che esamina entrambe e decide — in modo indipendente per ogni pixel — quanto peso assegnare a ciascun tipo. In uno sfondo affollato il sistema può fare più affidamento sui canali che emergono, mentre intorno ai contorni netti degli oggetti può enfatizzare indizi spaziali. Una fase finale di attivazione adattiva funge poi da dimmer appreso, potenziando le regioni davvero informative e attenuando il rumore residuo. Questo processo multi-fase aiuta a indirizzare l’attenzione della rete verso regioni coerenti e legate agli oggetti, come confermato da mappe di calore visive e misure quantitative di quanto le aree evidenziate corrispondano agli oggetti di ground truth.
Visione più nitida con uno sforzo aggiuntivo modesto
Gli autori hanno testato DMSCA su diversi benchmark standard, da piccoli insiemi di immagini minute fino al grande dataset ImageNet. Quando aggiunto ai modelli ResNet più diffusi, DMSCA ha migliorato in modo consistente l’accuratezza di classificazione — fino a circa 2 punti percentuali sui set piccoli e 1,5 punti percentuali su ImageNet — superando una serie di metodi di attenzione esistenti. Ha inoltre reso i modelli più robusti a degradi comuni delle immagini come rumore, sfocatura e compressione elevata, e ha migliorato le prestazioni in compiti correlati come il rilevamento di oggetti e l’etichettatura di scene. Questi benefici sono arrivati con solo un modesto incremento di calcolo e memoria. In termini semplici, DMSCA offre alle reti convoluzionali un modo più flessibile e consapevole del contesto per decidere cosa guardare e cosa ignorare, avvicinando la visione artificiale al focus selettivo della vista umana.
Citazione: Zong, L., Nan, S.J., Die, Z.F. et al. DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks. Sci Rep 16, 8044 (2026). https://doi.org/10.1038/s41598-026-37546-3
Parole chiave: meccanismi di attenzione, riconoscimento delle immagini, reti neurali convoluzionali, rappresentazione delle feature, visione artificiale robusta