Clear Sky Science · it
Migliorare il recupero cross-modale tramite ottimizzazione del grafo delle etichette e funzioni di perdita ibride
Ricercare in modo più intelligente tra immagini e parole
Ogni giorno scorriamo oceani di foto, video e testi. Trovare esattamente ciò che vogliamo—per esempio, tutte le immagini che corrispondono a una breve didascalia—dipende da quanto bene i computer riescono a collegare immagini e linguaggio. Questo articolo esplora un nuovo modo per rendere quella connessione più accurata, specialmente in scene reali e caotiche dove molte idee e oggetti compaiono contemporaneamente. Il risultato è una generazione di strumenti di ricerca più intelligenti che “comprendono” meglio quello che intendiamo, non solo quello che digitiamo.
Perché in un’immagine possono convivere molti significati
Una singola immagine raramente mostra solo una cosa. Una foto di una balena che salta in mare può coinvolgere insieme oceano, cielo, onde, vento e fauna. Quando etichettiamo un’immagine del genere, spesso le assegnamo diverse etichette correlate in modi sottili. I sistemi di ricerca esistenti di solito trattano queste etichette come se fossero caselle indipendenti. Questa semplificazione getta via indizi utili: se “balena” appare spesso insieme a “mare”, allora vedere una dovrebbe aumentare la probabilità dell’altra. Questo lavoro si concentra nel catturare quei legami nascosti tra le etichette in modo che una ricerca per un’idea possa comunque trovare immagini e testi che esprimono concetti strettamente correlati.

Costruire una rete di etichette connesse
Gli autori introducono una tecnica chiamata Rete Convoluzionale a Grafo a Due Strati, o L2-GCN, per modellare come le etichette si relazionano tra loro. In termini semplici, ogni etichetta (come “cielo” o “balena”) è trattata come un punto in una rete, e i collegamenti tra i punti riflettono quanto frequentemente quelle etichette compaiono insieme. Il metodo permette ripetutamente a ciascuna etichetta di “ascoltare” i suoi vicini, fondendo informazioni dalle etichette correlate pur mantenendo la propria identità. Dopo questo processo, il sistema ottiene descrizioni delle etichette più ricche che catturano meglio la struttura delle scene reali, dalle idee parallele (“mare” e “spiaggia”) a quelle più stratificate (“animale” e “balena”).
Insegnare a immagini e testi a condividere uno spazio comune
Naturalmente, le etichette sono solo metà della storia; il sistema deve anche apprendere dalle immagini e dai testi stessi. Il framework utilizza strumenti consolidati per trasformare pixel grezzi e parole in caratteristiche numeriche, quindi spinge entrambi i tipi di dati in uno spazio condiviso dove i loro significati possono essere confrontati direttamente. Un modulo avversario—ispirato in modo lato al gioco di spinta e trazione delle reti generative avversarie—disincentiva il modello dall’aggrapparsi a particolarità proprie soltanto delle immagini o del testo. Questo aiuta lo spazio condiviso a concentrarsi sul contenuto piuttosto che sul formato, così che la foto di una strada trafficata e una breve didascalia che la descrive risultino vicine in questa mappa comune del significato.
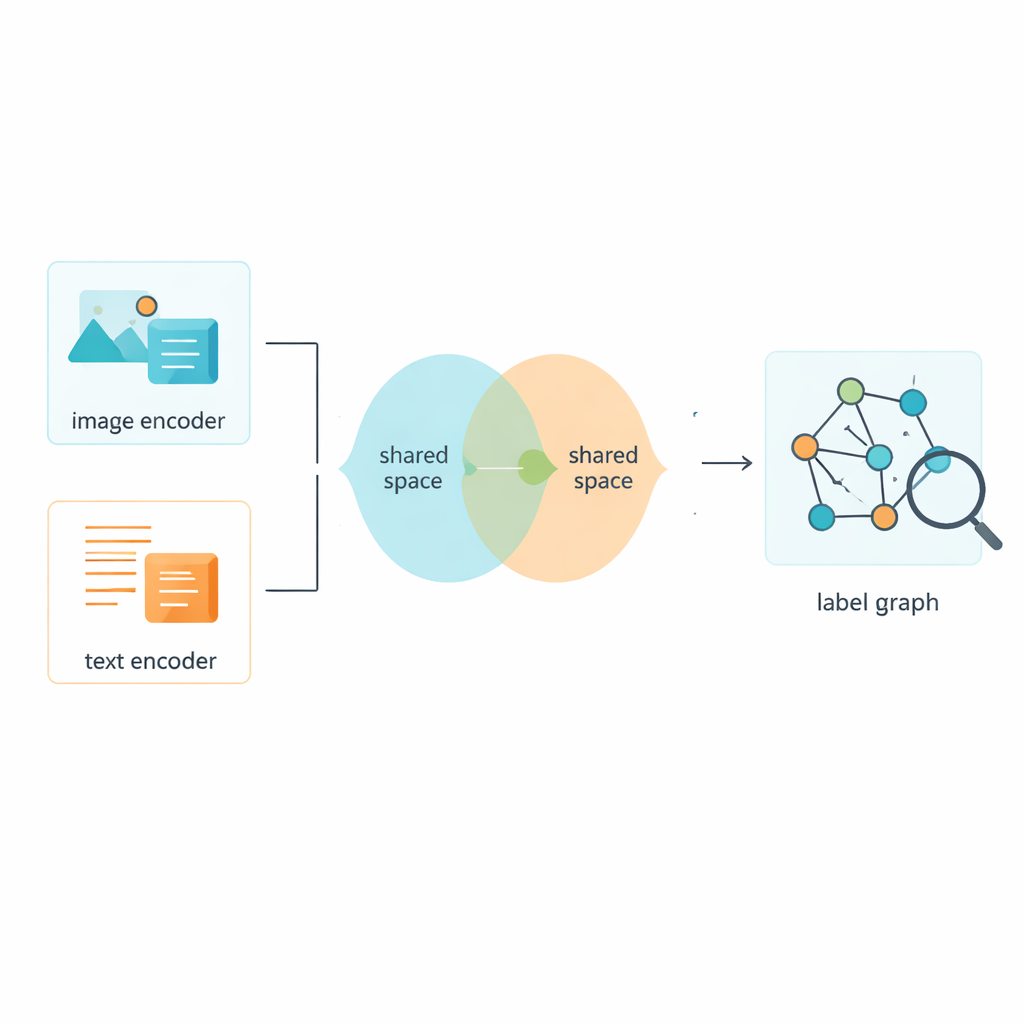
Una strategia di addestramento ibrida per distinzione più netta
Addestrare un sistema del genere richiede più di una sola regola di apprendimento. Gli autori progettano una funzione di perdita combinata, denominata Circle-Soft, che fonde due idee complementari. Una parte incoraggia esempi della stessa categoria a raggrupparsi strettamente mentre spinge via le categorie diverse in modo flessibile e adattativo. L’altra parte si concentra su quanto bene immagini e testi che descrivono la stessa scena si allineano attraverso i formati. Un peso tarabile equilibra questi due obiettivi affinché il modello non sovradatti né ai confini netti delle categorie né al solo allineamento cross-modale. Perdite aggiuntive di classificazione e avversarie incentivano ulteriormente la coerenza tra le etichette raffinate e le caratteristiche condivise immagine–testo.
Quanto migliora la ricerca?
Per verificare se queste idee si traducono in una ricerca migliore, gli autori hanno testato il loro metodo su tre collezioni popolari di coppie immagine–testo del mondo reale: MIRFlickr, NUS-WIDE e MS-COCO. Questi dataset contengono da migliaia a centinaia di migliaia di foto con tag o didascalie associate, coprendo scene quotidiane dalle strade cittadine alla fauna. Su tutti e tre i benchmark, il nuovo approccio ha costantemente superato una vasta gamma di metodi concorrenti, inclusi altri sistemi avanzati che già utilizzano la modellazione delle etichette basata su grafi. I guadagni—circa mezzo punto percentuale fino a un punto percentuale pieno in uno score rigoroso di retrieval—possono sembrare modesti, ma in benchmark maturi anche piccoli miglioramenti segnalano una comprensione più precisa del contenuto. In termini pratici, ciò significa che quando un utente inserisce una breve query testuale o fornisce un’immagine, il sistema è più propenso a mettere in cima ai risultati le corrispondenze cross-modali più rilevanti.
Cosa significa questo per gli utenti quotidiani
Per i non specialisti, il messaggio chiave è che una gestione più intelligente delle etichette e delle regole di addestramento può migliorare in modo evidente il modo in cui le macchine collegano immagini e parole. Trattando le etichette come una rete interconnessa invece che come tag isolati, e plasmando attentamente il punto di incontro tra informazione visiva e testuale in uno spazio condiviso, questo framework rende la ricerca cross-modale più affidabile in scene complesse e multi-tematiche. Nel tempo, tecniche come questa potrebbero potenziare librerie fotografiche più intuitive, piattaforme media e assistenti intelligenti che trovano quello che intendiamo—anche quando le nostre parole non corrispondono perfettamente alle immagini che abbiamo in mente.
Citazione: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
Parole chiave: recupero immagine-testo, ricerca multimodale, reti neurali a grafo, etichette semantiche, apprendimento automatico