Clear Sky Science · it
Un framework di deep learning interpretabile per il rilevamento con pochi esempi delle malattie delle colture in riso e canna da zucchero tramite estrazione di caratteristiche basata su CNN
Perché individuare le foglie malate è importante
Il riso e la canna da zucchero nutrono miliardi di persone e sostengono molte comunità agricole. Quando le loro foglie vengono colpite da malattie, interi raccolti possono ridursi, i prezzi degli alimenti possono aumentare e gli agricoltori possono perdere i mezzi di sussistenza. Tuttavia, la diagnosi precoce è difficile: i problemi spesso iniziano come piccole macchie o variazioni di colore che gli agricoltori, presi dal lavoro, possono trascurare, e gli esperti non sono sempre disponibili nelle vicinanze. Questo studio presenta un sistema basato su computer che può apprendere da pochissime foto di foglie, segnalare automaticamente le malattie e mostrare alle persone esattamente cosa nell’immagine ha portato alla diagnosi, aiutando gli agricoltori a intervenire prima e con maggiore fiducia.
Occhi intelligenti per il campo
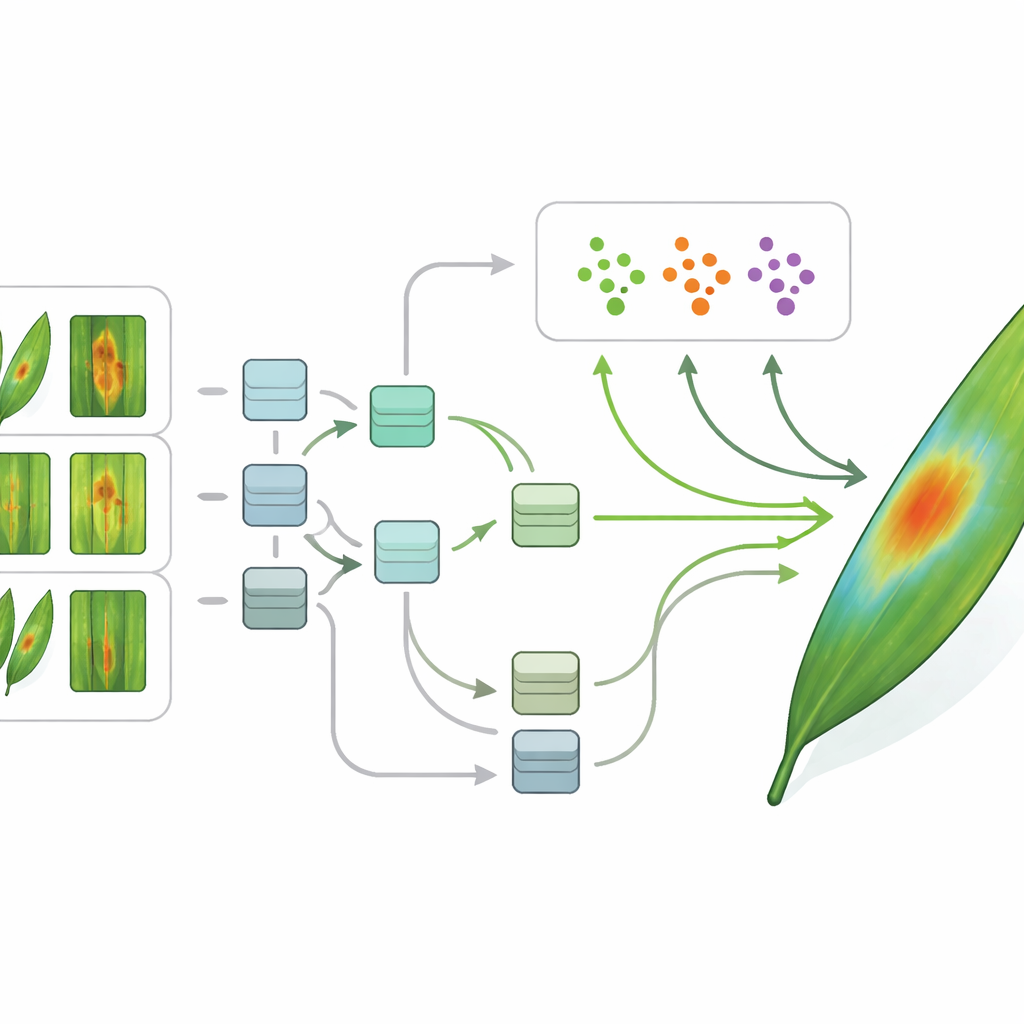
I ricercatori si concentrano su due colture di base: riso e canna da zucchero. Utilizzano due raccolte di immagini pubbliche di foglie, una acquisita in vere piantagioni di canna da zucchero usando vari smartphone e un set più piccolo e controllato di foto di foglie di riso. Ogni immagine mostra una foglia sana o una affetta da una malattia specifica, come macchie brune, pustole color ruggine o striature gialle. Basandosi su questi dataset condivisi invece che su raccolte private, il team punta a metodi che altri gruppi possano testare, riutilizzare e infine integrare in strumenti agricoli reali, dalle app per smartphone ai sensori connessi nei campi intelligenti.

Insegnare alle macchine con pochissimi esempi
L’intelligenza artificiale moderna può essere sorprendentemente abile nel riconoscere le malattie delle piante, ma di solito richiede migliaia di immagini etichettate per ogni condizione — una richiesta impegnativa in agricoltura, soprattutto per focolai nuovi o rari. Per aggirare questo ostacolo, gli autori adottano l’approccio del «few-shot learning», una famiglia di tecniche progettate per apprendere da una manciata di esempi. Il loro framework inizia con passaggi standard di elaborazione delle immagini: pulizia, ridimensionamento e normalizzazione di ogni foto in modo che il computer abbia una visione coerente. Un tipo di modello di deep learning chiamato rete neurale convoluzionale trasforma poi ogni immagine di foglia in un insieme compatto di caratteristiche numeriche che catturano forme, colori e texture rilevanti per la malattia.
Rendere la diagnosi comprensibile
Sopra queste caratteristiche, il team addestra due avanzati metodi few-shot chiamati Prototypical Networks e Model-Agnostic Meta-Learning. Il primo apprende una sorta di “centro” per ogni malattia nello spazio delle caratteristiche e assegna le nuove foglie al centro più vicino; il secondo impara come adattarsi rapidamente a nuovi compiti con pochi passaggi di addestramento. Fondamentale è che gli autori combinano questi metodi con strumenti di IA interpretabile. Usando tecniche in stile heatmap, il sistema può evidenziare quali parti di una immagine di foglia hanno maggiormente influenzato la sua decisione — un gruppo di macchie scure, una striatura gialla lungo la nervatura centrale, o l’assenza di lesioni evidenti in una pianta sana. Questo rende visibile il ragionamento del modello, permettendo agli agronomi di verificare se il computer si sta concentrando su segni di valore medico piuttosto che su elementi di disturbo sullo sfondo.
Quanto bene funziona il sistema
Per valutare se il loro approccio sia realmente utile, i ricercatori lo confrontano con diversi noti modelli di deep learning già impiegati per il rilevamento delle malattie delle piante. Suddividono ogni dataset in parti di addestramento e test e misurano quanto spesso ogni metodo identifica correttamente il tipo di malattia. Sulle foglie di canna da zucchero scattate in campo, il nuovo framework raggiunge circa il 92 percento di classificazioni corrette, superando architetture standard come VGG, ResNet, Xception ed EfficientNet. Sul dataset di riso ottiene risultati ancora migliori, identificando correttamente circa il 98 percento delle immagini di test. Strumenti statistici che esaminano l’equilibrio tra falsi allarmi e casi mancati mostrano che il nuovo metodo si comporta come un eccellente strumento di screening medico piuttosto che come un indovinatore casuale.
Cosa significa questo per gli agricoltori
In parole semplici, lo studio dimostra che un computer può imparare a individuare con precisione diverse malattie di riso e canna da zucchero a partire da un numero limitato di immagini di esempio, e può anche indicare i punti e le striature sulla foglia che hanno guidato il suo verdetto. Questa combinazione di efficienza nei dati e trasparenza è fondamentale per l’uso reale: riduce la barriera per costruire strumenti per nuove colture e malattie emergenti e fornisce agli agricoltori e agli esperti prove visive di cui possono fidarsi. Con ulteriori test in campi reali e interfacce utente più amichevoli, sistemi few-shot interpretabili come questo potrebbero diventare partner quotidiani nell’agricoltura intelligente, aiutando a proteggere i raccolti e riducendo l’uso inutile di pesticidi.
Citazione: El-Behery, H., Attia, AF. & Rezk, N.G. An explainable deep learning framework for few shot crop disease detection in rice and sugarcane using CNN based feature extraction. Sci Rep 16, 8272 (2026). https://doi.org/10.1038/s41598-026-37501-2
Parole chiave: rilevamento delle malattie delle colture, riso e canna da zucchero, deep learning, IA interpretabile, agricoltura intelligente