Clear Sky Science · it
Un framework di deep learning basato su DNABERT per predire i siti di legame dei fattori di trascrizione
Perché è importante prevedere gli interruttori di controllo del DNA
Ogni cellula del tuo corpo porta sostanzialmente lo stesso DNA, eppure i neuroni, le cellule del fegato e le cellule del sistema immunitario si comportano in modo molto diverso. Una ragione è che proteine speciali chiamate fattori di trascrizione fungono da interruttori molecolari, attivando o spegnendo geni ancorandosi a brevi tratti di DNA noti come siti di legame. Scoprire sperimentalmente tutti questi punti di ancoraggio lungo il genoma è lento e costoso. Questo studio presenta TFBS-Finder, un nuovo modello di intelligenza artificiale che può leggere le lettere grezze del DNA e prevedere con maggiore accuratezza dove i fattori di trascrizione si legano, accelerando potenzialmente la ricerca sulla regolazione genica e sulle malattie.
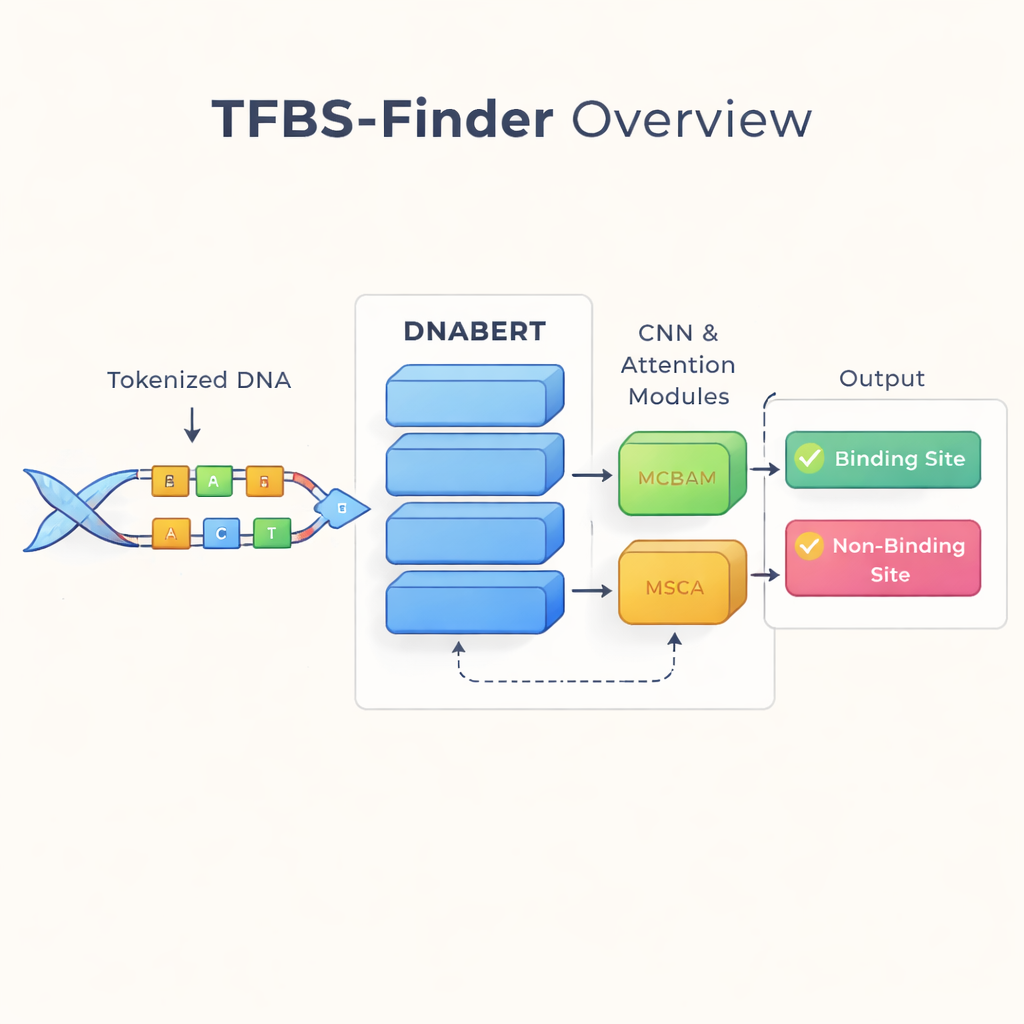
Leggere il DNA come se fosse una lingua
Gli autori si basano su un’idea che ha trasformato la tecnologia del linguaggio: trattare il DNA come se fosse testo. Usano DNABERT, una versione del modello di linguaggio BERT riaddestrata sul DNA umano invece che sulle parole. DNABERT non considera solo singole lettere; suddivide il DNA in “parole” sovrapposte di cinque lettere e impara come questi frammenti tendono a co‑occorrere. Questo permette al modello di catturare il contesto a lungo raggio, per esempio come i pattern a un’estremità di una sequenza si relazionano a pattern lontani, proprio come comprendere il senso di una frase piuttosto che parole isolate.
Trovare pattern locali con attenzione mirata
Se DNABERT è bravo a cogliere il contesto globale, il legame dei fattori di trascrizione dipende spesso da motivi molto brevi e precisi—pattern locali nel DNA. TFBS-Finder quindi aggiunge diversi componenti extra sopra DNABERT. Una rete neurale convoluzionale (CNN) esamina gli embedding della sequenza per evidenziare forme locali ricorrenti, come il software per immagini rileva bordi e angoli. Due moduli di attenzione, chiamati MCBAM e MSCA, agiscono poi come riflettori regolabili, rafforzando le caratteristiche più informative e attenuando il rumore. Insieme, questi blocchi bilanciano la prospettiva d’insieme con i dettagli fini per decidere se un segmento di DNA contiene un vero sito di legame.
Dimostrare che ogni componente è davvero utile
Per verificare se tutti questi componenti siano necessari, il team ha eseguito estese esperienze di “ablation”, rimuovendo o riorganizzando sistematicamente i moduli e riaddestrando il sistema su 165 dataset di riferimento che coprono 29 fattori di trascrizione in 32 tipi cellulari. Usando misure standard di qualità predittiva, il modello completo TFBS-Finder è risultato costantemente il migliore. Versioni più semplici che si basavano solo su DNABERT, o che escludevano uno dei moduli di attenzione, perdevano chiaramente in accuratezza. Test statistici hanno confermato che questi cali di performance non erano dovuti al caso, mostrando che la combinazione di comprensione globale della sequenza e di attenzione progettata con cura ai pattern locali è cruciale.
Funzionare attraverso tipi cellulari e battere strumenti più datati
Una domanda importante è se un modello addestrato in un contesto biologico possa generalizzare in un altro. Gli autori si sono concentrati su un fattore di trascrizione ben studiato chiamato CTCF e hanno addestrato TFBS-Finder su dati di una linea cellulare, testandolo poi su altre. In tutte le combinazioni, il modello ha raggiunto punteggi elevati, suggerendo che cattura caratteristiche fondamentali del legame di CTCF condivise tra i tessuti. Messo a confronto con nove metodi di punta, inclusi modelli deep learning e basati su BERT precedenti, TFBS-Finder ha mostrato una maggiore accuratezza media e ha prodotto classifiche dei siti di legame più affidabili. Ha anche funzionato leggermente più velocemente e consumato meno memoria rispetto al modello precedente più simile, indicando che prestazioni migliori non richiedono calcoli più pesanti.
Visualizzare ciò che il modello ha imparato
I sistemi di IA complessi sono spesso criticati come “scatole nere”. Qui i ricercatori hanno cercato di aprire quella scatola visualizzando quali posizioni del DNA hanno maggiormente influenzato le decisioni di TFBS-Finder. Per due fattori di trascrizione con motivi di legame ben noti, CEBPB e GATA3, hanno generato score di importanza lungo la sequenza e raggruppato i segnali più forti in pattern di consenso. Questi motivi ricostruiti corrispondevano strettamente ai motivi di riferimento presenti in database consolidati, e le regioni di legame predette si sovrapponevano a istanze di motivi rilevate in modo indipendente. Ciò suggerisce che TFBS-Finder non si limita a memorizzare esempi, ma ha appreso regole biologicamente significative su come i fattori di trascrizione riconoscono il DNA.
Cosa significa per genetica e medicina
TFBS-Finder offre un modo più accurato e interpretabile per mappare gli interruttori di controllo incorporati nel nostro DNA. Individuando dove i fattori di trascrizione sono più propensi a legarsi, può aiutare i ricercatori a tracciare reti di regolazione genica, prioritizzare quali varianti genetiche potrebbero interrompere siti di controllo cruciali e progettare esperimenti più mirati. Sebbene il lavoro corrente usi sequenze mescolate come negativi artificiali e si concentri solo sulle lettere del DNA, gli autori prevedono di aggiungere informazioni strutturali sulla forma del DNA ed esplorare sequenze di background più realistiche. Man mano che questi modelli migliorano, potrebbero diventare strumenti potenti per capire come le variazioni nel DNA non codificante contribuiscano allo sviluppo, all’evoluzione e al rischio di malattia.
Citazione: Dutta, P., Ghosh, N. & Santoni, D. A DNABERT based deep learning framework for predicting transcription factor binding sites. Sci Rep 16, 7018 (2026). https://doi.org/10.1038/s41598-026-37483-1
Parole chiave: siti di legame dei fattori di trascrizione, deep learning, DNABERT, regolazione genica, genomica