Clear Sky Science · it
Migliorare la rappresentazione della conoscenza medica nei grandi modelli linguistici tramite l’ottimizzazione dei token clinici
Perché una lettura medica più intelligente conta
Dietro ogni assistente medico basato sull’intelligenza artificiale c’è un’abilità semplice ma cruciale: come taglia il testo in pezzi che può comprendere. Quando questo “taglio” fallisce — specialmente per termini medici cinesi complessi — l’IA può perdere idee chiave nelle note dei medici o nelle domande dei pazienti. Questo articolo mostra come una modifica piccola ma mirata a questo primo passo possa rendere i grandi modelli linguistici migliori nel leggere, ragionare e rispondere su dati medici cinesi, senza dover costruire un sistema completamente nuovo.
Spezzare il testo nel modo giusto
I moderni modelli linguistici non leggono direttamente caratteri o parole; convertono prima il testo in unità brevi chiamate token. Per l’inglese questo funziona abbastanza bene, perché gli spazi segnano già i confini delle parole. Il cinese è più complesso: non ci sono spazi e molte espressioni mediche sono frasi lunghe e specializzate. I tokenizer standard, pensati principalmente per l’inglese, tendono a spezzare queste espressioni in molti frammenti arbitrari. Quando un modello vede un nome di malattia o un esame di laboratorio diviso in più parti disgiunte, fatica a imparare cosa significhi davvero quel termine e le sue risposte a domande mediche possono diventare vaghe o inaccurate.
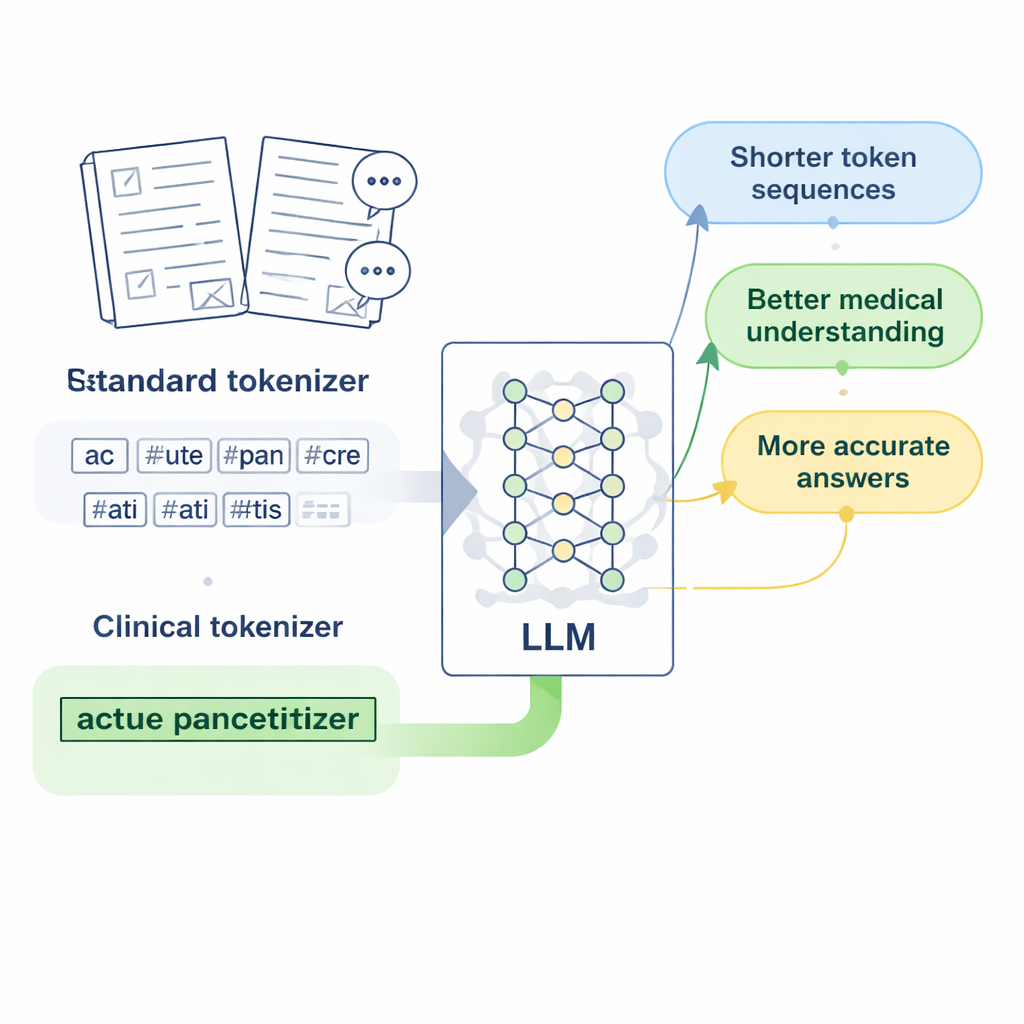
Progettare “token clinici” per la medicina cinese
I ricercatori si concentrano su LLaMA2, un popolare grande modello linguistico open source, e si chiedono: cosa succede se insegniamo semplicemente al suo tokenizer un vocabolario medico più ricco? Raccogliono ampie collezioni di testi medici cinesi, includendo database di medicina tradizionale cinese curati, migliaia di cartelle cliniche e coppie domanda‑risposta medico‑paziente. Usando una versione a livello di byte dell’algoritmo Byte Pair Encoding, implementata con lo strumento SentencePiece, addestrano un nuovo tokenizer che impara a mantenere insieme le espressioni mediche comuni come unità singole. Queste nuove unità, che gli autori chiamano “token clinici”, vengono poi fuse nel vocabolario originale di LLaMA2, ampliandolo per coprire meglio il linguaggio medico cinese senza scartare ciò che il modello già conosce.
Da token migliori a un modello medico migliore
Aggiungere nuovi token è solo il primo passo; il modello deve imparare buone rappresentazioni per essi. Il team adatta lo strato di embedding interno di LLaMA2 in modo che possa memorizzare vettori per il vocabolario ampliato e testa due modi per inizializzare questi nuovi vettori. Un metodo calcola la media dei vettori delle vecchie sub‑parti di ogni parola, mentre l’altro usa valori casuali opportunamente scalati. Controintuitivamente, il metodo casuale dà risultati migliori, probabilmente perché evita di vincolare il modello a una cattiva ipotesi iniziale sul significato di ogni termine. Gli autori continuano poi ad addestrare il modello su testi medici e lo affinano su domande‑risposte mediche in stile istruzionale usando un metodo efficiente in termini di risorse chiamato LoRA, producendo una versione specializzata che chiamano Medical‑LLaMA.
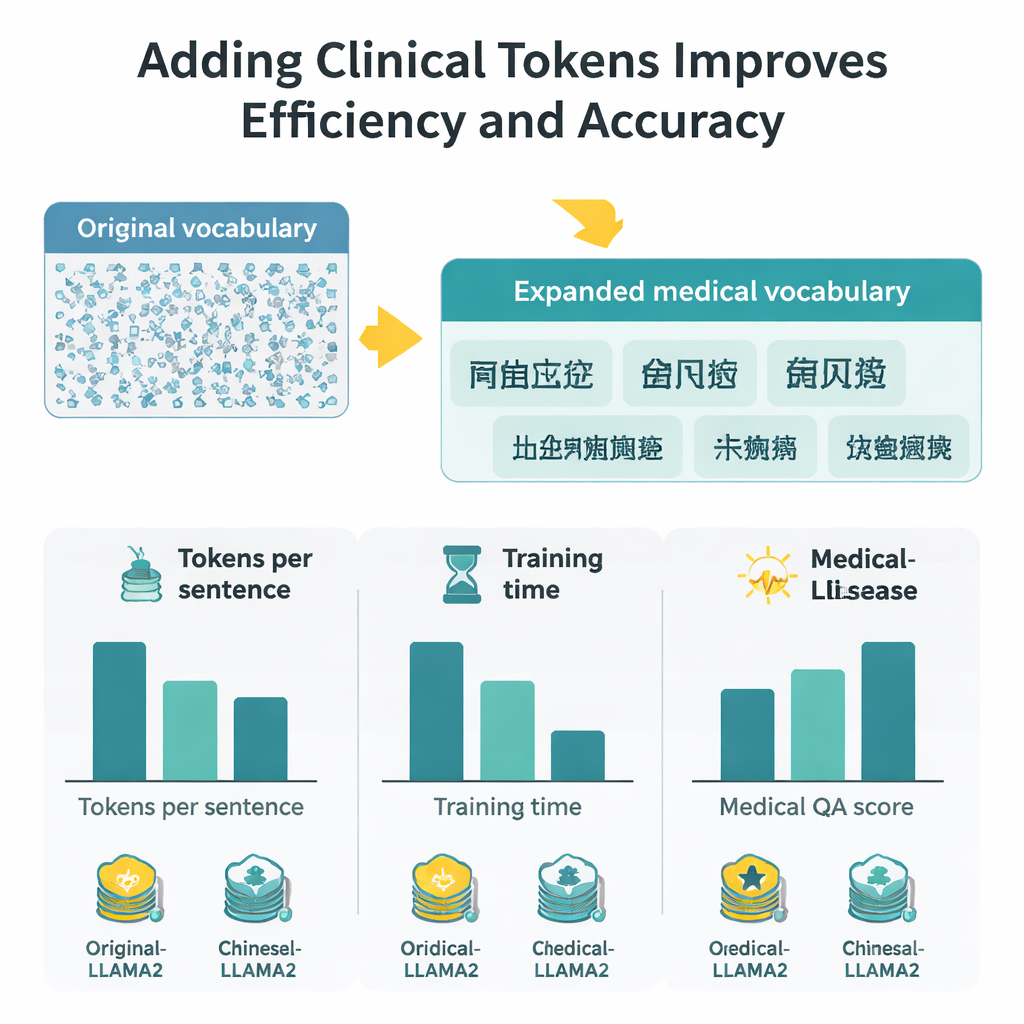
Misurare i guadagni in velocità, contesto e accuratezza
Con il vocabolario ampliato, ogni carattere cinese richiede ora circa la metà dei token di prima, il che significa che il modello può elaborare passaggi più lunghi nella stessa finestra di token fissa. In pratica, la lunghezza di contesto effettiva per il cinese raddoppia approssimativamente e il tempo di fine‑tuning su un grande set di Q&A mediche si riduce di quasi la metà. Per valutare la qualità delle risposte, gli autori combinano due strategie: BERTScore, che misura quanto semanticamente vicina sia una risposta generata a una di riferimento, e un modello di valutazione sofisticato (DeepSeek‑R1) che valuta rilevanza, accuratezza, completezza e fluidità. Su queste misure, Medical‑LLaMA supera costantemente sia l’originale LLaMA2 sia una variante ottimizzata per il cinese che non includeva token specifici per la medicina. Mostra anche miglioramenti piccoli ma costanti in compiti correlati come il riconoscimento delle entità mediche e la classificazione di testi clinici, il tutto preservando le prestazioni su domande generali, non mediche.
Cosa significa per il futuro dell’IA medica
Per i non specialisti, il messaggio chiave è che occhiali di lettura più intelligenti per l’IA — in questo caso, un modo migliore di frammentare il linguaggio medico — possono migliorare in modo evidente la sua capacità di comprendere e rispondere a domande di salute. Inserendo token clinici ben scelti nel vocabolario di un modello esistente, gli autori migliorano sia l’efficienza sia l’accuratezza senza richiedere enormi nuove sessioni di addestramento o architetture completamente nuove. Pur essendo il lavoro limitato a un modello da 7 miliardi di parametri e a testi medici cinesi, indica una ricetta pratica: adattare il livello iniziale dell’elaborazione linguistica al dominio, quindi riaddestrare leggermente. Questa strategia potrebbe aiutare i futuri strumenti di IA medica a diventare partner più affidabili per clinici e pazienti, specialmente in lingue e specialità che i modelli standard faticano a leggere.
Citazione: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
Parole chiave: modelli linguistici medici, testo clinico cinese, tokenizzazione, vocabolario clinico, risposta a domande mediche