Clear Sky Science · it
AE-LFOG-YOLO: rilevamento robusto dei caschi di sicurezza tramite ancore adattive e apprendimento invariabile all’illuminazione
Perché i controlli intelligenti dei caschi sono importanti
Nei grandi cantieri e nelle gallerie sotterranee, un semplice casco di sicurezza può fare la differenza tra un episodio senza conseguenze e una lesione che cambia la vita. Tuttavia, nel caos dei cantieri reali le persone a volte dimenticano o evitano di indossarlo, e i supervisori umani non possono sorvegliare ogni angolo in ogni momento. Questo studio esplora come costruire un sistema automatico a telecamera che individui in modo affidabile chi indossa o meno il casco, anche quando la galleria è buia, invasa da riverberi delle lampade o affollata di lavoratori a distanze molto diverse dalla camera.
Le difficoltà di vedere con illuminazione difficile in galleria
I cantieri di galleria sono ambienti visivamente estremi. Fari intensi generano abbagliamento, mentre profonde zone d’ombra nascondono i dettagli. Le persone si avvicinano e si allontanano dalla telecamera, perciò i caschi appaiono a dimensioni molto variabili. I rilevatori di intelligenza artificiale standard spesso falliscono in queste condizioni: non individuano i caschi nelle aree scure, confondono altri oggetti arrotondati con i caschi o faticano con lavoratori molto piccoli o lontani. Molti sistemi esistenti cercano di risolvere il problema schiarendo o pulendo le immagini prima della rilevazione o aggiustando alcuni componenti dei popolari modelli YOLO. Poiché però questi interventi sono di solito soluzioni esterne e non fanno parte di un unico processo di apprendimento, lasciano sul tavolo performance potenziali e non sono robusti quando cambiano illuminazione o disposizione della scena.
Un nuovo modo per insegnare alle telecamere a ignorare le cattive condizioni di illuminazione
Gli autori propongono un sistema migliorato chiamato AE‑LFOG‑YOLO, costruito sul diffusissimo rilevatore YOLOv8. La prima idea chiave è un Modulo Invariante all’Illuminazione, una piccola unità inserita nella rete che impara a separare “ciò che fa la luce” da “come sono realmente gli oggetti”. Divide le mappe di caratteristiche in una parte che riflette principalmente i pattern di illuminazione e una parte che cattura la forma e la texture più stabili, come il bordo curvo di un casco. Usando operazioni di gating speciali e un ramo focalizzato su bordi e angoli, il modulo attenua le oscillazioni di luminosità e valorizza la geometria stabile. Poiché questo avviene all’interno del rilevatore e non in un passaggio di pre‑elaborazione separato, l’intero sistema può essere addestrato end-to-end per mantenere l’attenzione sui caschi anziché essere ingannato da chiazze di abbagliamento o oscurità.
Lasciare che il modello evolva le proprie abitudini di visione
La seconda idea principale riguarda come il rilevatore ipotizza dove possono apparire gli oggetti. Molti rilevatori partono da un insieme fisso di “box di ancoraggio” che suggeriscono dimensioni e forme probabili degli oggetti; questi vengono di solito scelti una volta dai dati di addestramento e poi non aggiornati. In galleria, però, la dimensione apparente di un casco può variare drasticamente con la distanza e l’angolo di ripresa. AE‑LFOG‑YOLO sostituisce le ancore statiche con un processo dinamico chiamato Adaptive Evolutionary – Light Field Optimized Generation. Alla fine di ogni epoca di addestramento, il sistema perturba leggermente le sue ancore, valuta quanto bene corrispondono ai caschi reali di tutte le dimensioni e verifica anche se le loro proporzioni hanno senso alla luce di principi ottici di base—quanto grande dovrebbe apparire un casco sul sensore alle distanze di lavoro tipiche. Gli insiemi di ancore con punteggi migliori sopravvivono al turno successivo. Col tempo, il rilevatore “evolve” ancore che sia si adattano ai dati sia rispettano il modo in cui le camere effettivamente riprendono il mondo.
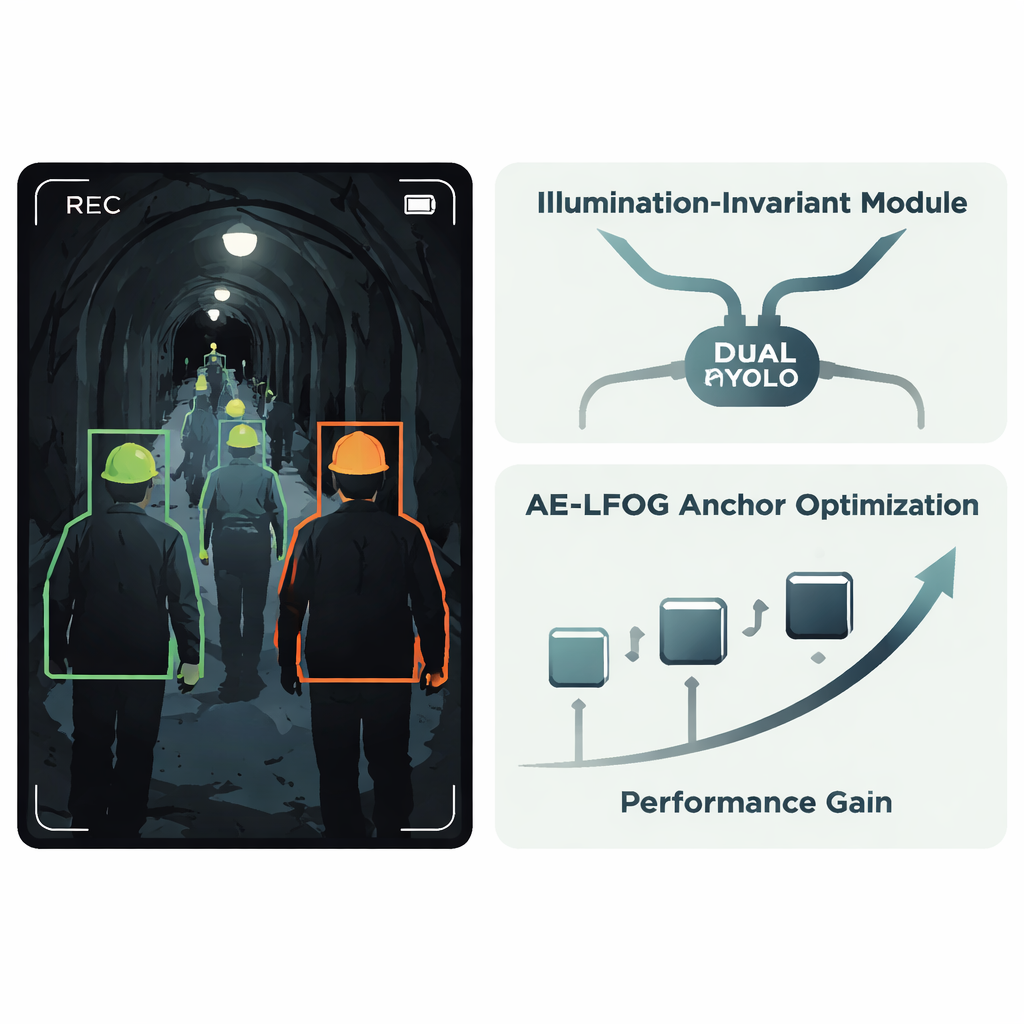
Adattare l’addestramento alla qualità reale delle immagini
Oltre a cambiare cosa il modello cerca, gli autori modificano anche come impara. Introducono una strategia di addestramento che presta più attenzione al posizionamento preciso delle casse di delimitazione quando la qualità dell’immagine è scarsa, e più attenzione alla classificazione casco/non casco quando le condizioni sono buone. Un punteggio basato sulla fisica, derivato ancora una volta dai principi dell’imaging con telecamera, indica al sistema quanto siano affidabili le immagini in ogni fase. Se illuminazione o fuoco sono cattivi, il processo di addestramento aumenta automaticamente l’importanza di ottenere i bounding box corretti; se le condizioni migliorano, sposta il peso verso la classificazione. Questo crea un ciclo di feedback in cui il modello aggiusta continuamente le proprie priorità per adattarsi all’ambiente fisico che incontrerà nelle gallerie reali.
Cosa mostrano i test nella pratica
I ricercatori testano il loro approccio su un dataset reale di caschi per gallerie e lo confrontano con diversi metodi avanzati basati su YOLO. AE‑LFOG‑YOLO rileva i caschi con precisione molto elevata, identificando correttamente circa il 95 percento dei caschi a una soglia standard di sovrapposizione e superando il baselines YOLOv8 sia in precisione sia in richiamo. Gira abbastanza velocemente per l’uso in tempo reale e si dimostra particolarmente robusto quando la luminosità è pesantemente manipolata per simulare oscurità estrema o sovraesposizione. In queste condizioni difficili il nuovo modello mantiene una confidenza più alta, rileva più lavoratori piccoli e distanti e opera su un intervallo di luminosità più di un terzo più ampio rispetto al baseline, il che significa che rimane affidabile in un insieme molto più vasto di scene reali.
Come questo aiuta a mantenere i lavoratori più sicuri
Per i non specialisti, la conclusione è semplice: insegnando a un sistema di IA a comprendere non solo i pixel ma anche la fisica di come le telecamere vedono in ambienti difficili, questo lavoro offre un sorvegliante sul muro della galleria più intelligente e più affidabile. AE‑LFOG‑YOLO sa meglio ignorare l’illuminazione fuorviante e adattarsi a viste variabili, riducendo rilevazioni mancate e falsi allarmi. Installato per mesi su una linea tranviaria operativa, ha già dimostrato di poter supportare i team per la sicurezza nel garantire che i lavoratori portino il casco, offrendo un passo pratico verso cantieri più sicuri e più sorvegliati.
Citazione: Liu, S., Wang, J. AE-LFOG-YOLO: robust safety helmet detection via adaptive anchors and illumination invariant learning. Sci Rep 16, 6402 (2026). https://doi.org/10.1038/s41598-026-37326-z
Parole chiave: rilevamento caschi di sicurezza, costruzione di gallerie, visione artificiale, imaging in condizioni di bassa luminosità, YOLOv8