Clear Sky Science · it
Applicazione dell’apprendimento contrastivo auto-supervisionato gerarchico nell’adattamento di dominio per l’allineamento di immagini telerilevate multimodali
Osservare la Terra con occhi diversi
I satelliti meteorologici, le missioni radar e le telecamere ad alta risoluzione nello spazio guardano tutti lo stesso pianeta in modi molto diversi. Questa diversità è un vantaggio per compiti come il monitoraggio delle inondazioni, la mappatura delle città o il controllo delle foreste—se riusciamo ad allineare le immagini in modo affidabile. L’articolo qui riassunto introduce un nuovo metodo di intelligenza artificiale che insegna ai computer a confrontare queste viste molto differenti della Terra in modo più accurato e con molte meno etichette umane, aprendo la strada a un monitoraggio ambientale più rapido e robusto.
Perché è così difficile mettere in corrispondenza immagini diverse
Le immagini di telerilevamento provengono da molti tipi di sensori: telecamere ottiche che vedono come i nostri occhi, sistemi radar che misurano la rugosità della superficie e strumenti multispettrali che catturano sottili differenze cromatiche. Poiché ogni sensore ha il suo modo di “vedere”, lo stesso edificio, nave o campo può apparire completamente diverso da un’immagine all’altra—granuloso nel radar, nitido nell’ottico o con tinte insolite nelle viste multispettrali. I metodi di matching tradizionali si basano o su caratteristiche visive costruite a mano o su reti profonde completamente supervisionate che richiedono grandi quantità di dati accuratamente etichettati. Entrambi gli approcci tendono a fallire quando il divario di aspetto tra i sensori è ampio, o quando gli esempi etichettati scarseggiano, come spesso accade durante le catastrofi o in regioni remote.
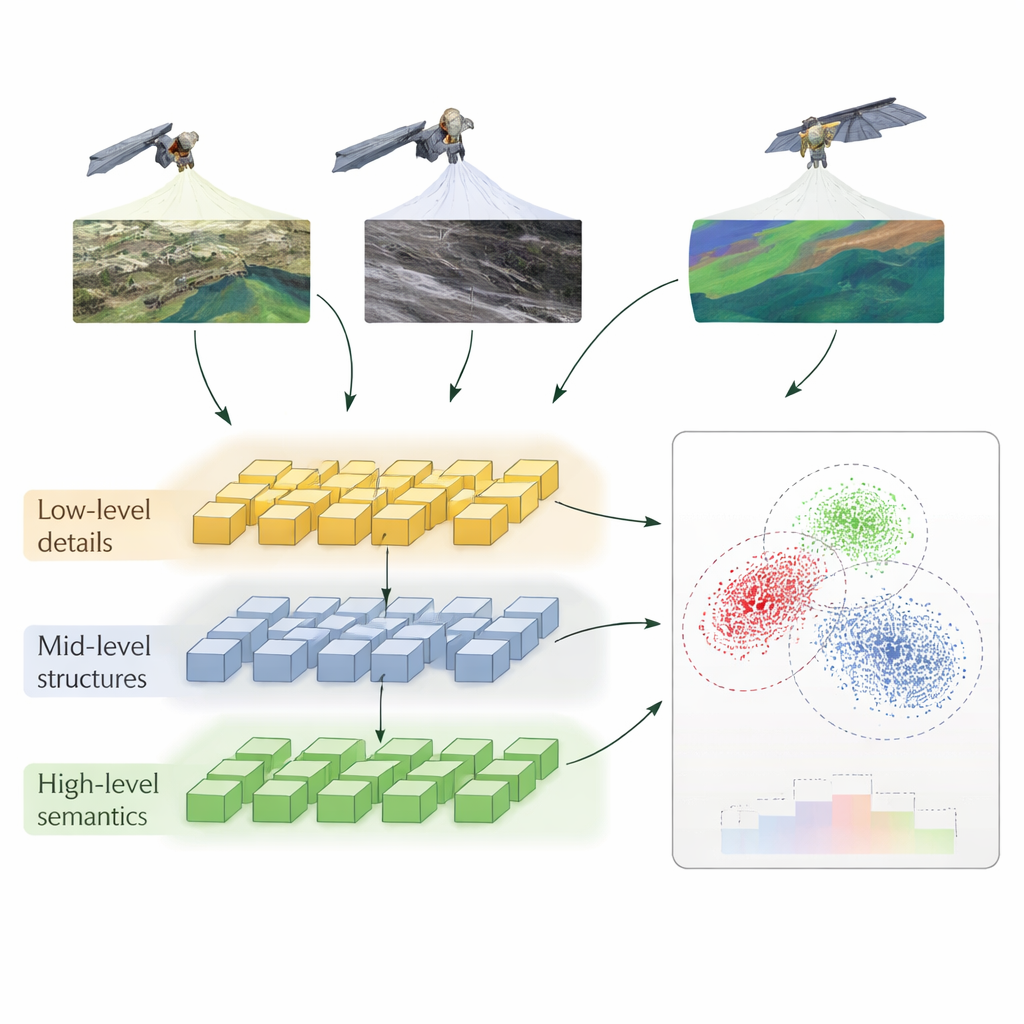
Un modo stratificato per insegnare ai computer a confrontare
Gli autori propongono un metodo chiamato Apprendimento Contrastivo Auto‑Supervisionato Gerarchico (HSSCL), che modifica il modo in cui una rete neurale impara a confrontare le immagini. Invece di guardare solo a un singolo riassunto di ciascuna immagine, la rete estrae informazioni su tre livelli: dettagli fini come bordi e texture, pattern a scala media come strade e profili degli edifici, e pattern più ampi come la disposizione urbana o i tipi di copertura del suolo. A ogni livello, il sistema incoraggia le caratteristiche provenienti da sensori diversi che ritraggono la stessa area a diventare più simili, mentre allontana le caratteristiche che vengono da aree non correlate. Questo addestramento “contrastivo” avviene senza etichette umane: il modello sfrutta l’accoppiamento noto di immagini di sensori diversi sulla stessa localizzazione, oltre a esempi simili trovati automaticamente, per costruire una ricca nozione di cosa significhi “lo stesso luogo” tra le modalità.
Pulire il rumore e preservare la geometria
I dati di telerilevamento del mondo reale sono disordinati—le immagini radar contengono rumore a granulosità (speckle), le immagini ottiche possono essere sfocate e tutte possono essere disallineate di alcuni pixel. HSSCL affronta questo dividendo innanzitutto le immagini in piccoli blocchi e applicando una denoising mirata, che aiuta la rete a concentrarsi sulle strutture significative piuttosto che sulle fluttuazioni casuali. Poi alimenta le caratteristiche provenienti da diversi blocchi in un modulo basato su grafo che tratta ogni regione come un nodo e collega regioni vicine e visivamente simili. Operando su questo grafo, una rete neurale specializzata rafforza la coerenza geometrica delle corrispondenze, rendendo più probabile che strade si allineino con strade e edifici con edifici, anche in condizioni difficili.
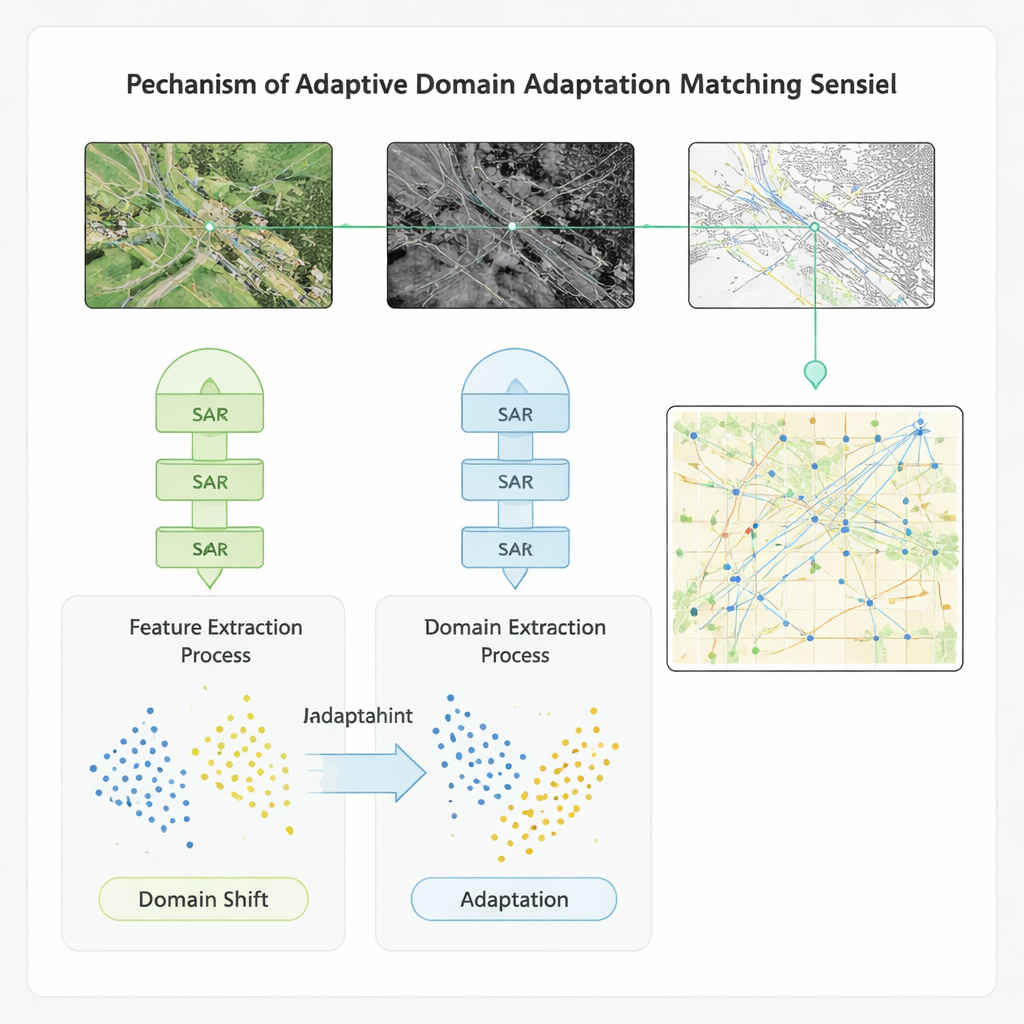
Adattarsi tra dataset e condizioni
Per garantire che il metodo funzioni oltre un singolo benchmark, gli autori integrano lo schema di apprendimento in un modello di adattamento di dominio. Questo componente riduce esplicitamente il divario tra le proprietà statistiche delle caratteristiche provenienti da sensori e dataset diversi, in modo che un modello addestrato su una regione o strumento possa essere applicato a un’altra con una perdita minima di accuratezza. Testato su quattro dataset pubblici che includono immagini multispettrali globali, coppie radar‑ottico ad alta risoluzione, scene di copertura del suolo e immagini di navi, il nuovo approccio supera diversi metodi di riferimento avanzati. Migliora accuratezza, recall e F1 di circa 20 punti percentuali, accelera il matching di oltre il 20% e aumenta l’accuratezza nel rilevamento di difetti in stile video—importante per monitorare i cambiamenti nel tempo—di oltre il 40%. Il metodo mostra inoltre maggiore resilienza al rumore e agli spostamenti tra condizioni di addestramento e di impiego.
Cosa significa per il monitoraggio nel mondo reale
Dal punto di vista del pubblico, lo studio dimostra come i computer possano essere addestrati a riconoscere “questo è lo stesso luogo” tra immagini che agli occhi umani non sembrano affatto simili. Imparando a più livelli di dettaglio, eliminando il rumore e adattandosi esplicitamente a nuovi sensori e regioni, il metodo HSSCL rende più semplice combinare molti flussi di dati satellitari in un quadro coerente. Questo, a sua volta, può aiutare gli operatori di emergenza ad allineare più rapidamente immagini radar e ottiche dopo una tempesta, supportare i pianificatori nel monitorare come città o foreste cambiano nel tempo e favorire il tracciamento continuo delle navi in mare. Pur riconoscendo che rumori estremi e distorsioni molto grandi restano una sfida, il loro lavoro offre un percorso promettente e pratico verso un matching più veloce e più affidabile dei molti “occhi” che abbiamo in orbita.
Citazione: Li, Y., Luo, Z., Zhu, G. et al. Application of hierarchical self-supervised contrastive learning in domain adaptation matching of multimodal remote sensing image. Sci Rep 16, 6445 (2026). https://doi.org/10.1038/s41598-026-37312-5
Parole chiave: telerilevamento, immagini multimodali, apprendimento auto-supervisionato, apprendimento contrastivo, adattamento di dominio