Clear Sky Science · it
Valutazione delle prestazioni di un trasformatore generativo pre-addestrato sull’Esame Nazionale per l’Abilitazione Veterinaria in Giappone
Perché esami veterinari più intelligenti interessano tutti
Dietro ogni visita all’ospedale veterinario ci sono anni di formazione rigorosa e un esame nazionale ad alta posta in gioco. In Giappone, i futuri veterinari devono superare l’Esame Nazionale per l’Abilitazione Veterinaria (NVLE), che valuta tutto, dalla biologia di base al complesso giudizio clinico. Questo studio ha posto una domanda attuale: i moderni modelli linguistici avanzati di AI, gli stessi che alimentano i chatbot più diffusi, possono risolvere questo impegnativo esame in giapponese — e cosa potrebbe significare questo per l’educazione veterinaria e la cura degli animali?
Testare l’AI su un vero esame di abilitazione veterinaria
I ricercatori si sono concentrati su tre generazioni di modelli linguistici di grandi dimensioni di OpenAI: GPT‑4o, o1 e o3. Questi sistemi sono progettati per leggere e generare testo simile a quello umano, ma non sono mai stati addestrati specificamente per la medicina veterinaria. Per metterli alla prova, il team ha usato il 74° NVLE del Giappone (2023) come riferimento. L’esame è diviso in cinque sezioni, incluse domande solo testuali e domande basate su immagini che mostrano radiografie, foto o diagrammi. Tutte le domande sono a scelta multipla con cinque opzioni, proprio come l’esame reale sostenuto dagli studenti. I modelli hanno ricevuto ogni domanda tramite uno script informatico standardizzato e dovevano rispondere soltanto con il numero dell’opzione scelta, senza possibilità di “spiegare” o negoziare per ottenere credito.
Quale modello AI è risultato il migliore?
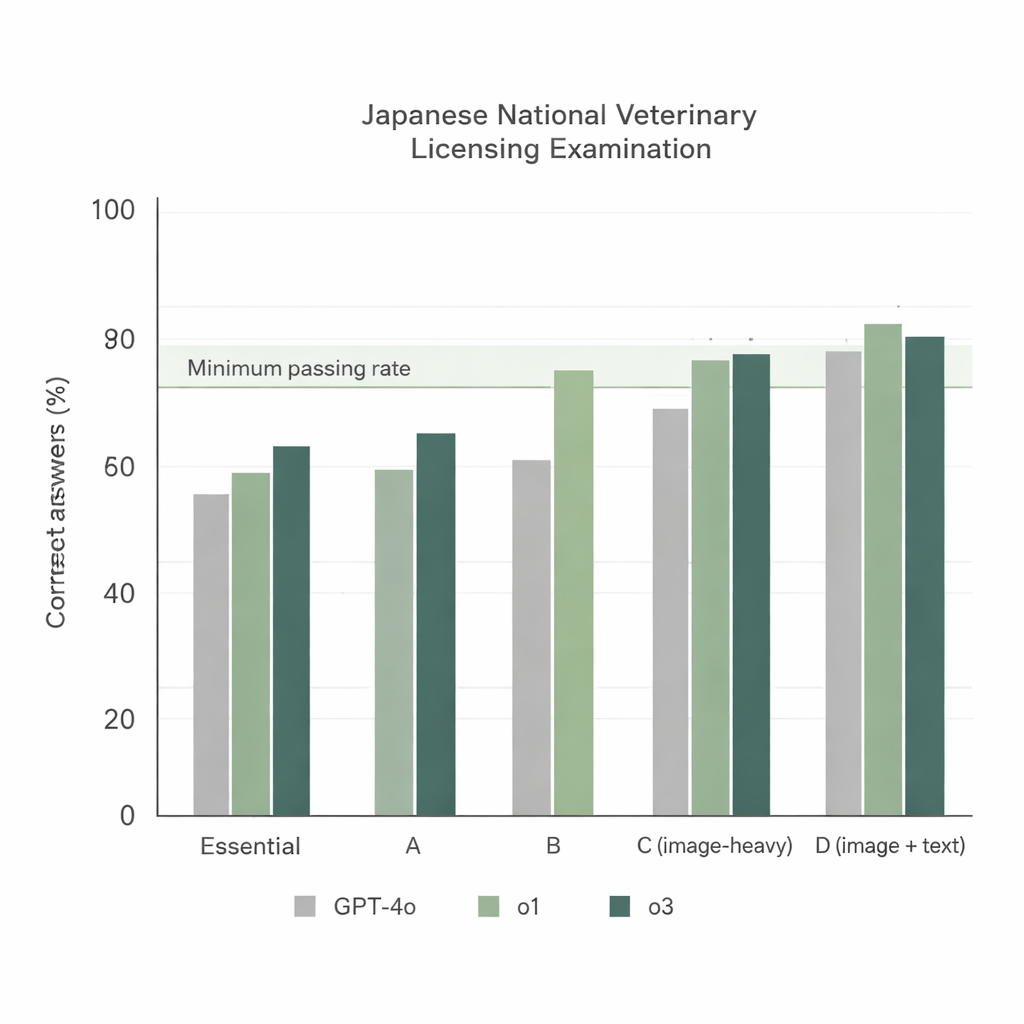
Quando i tre modelli hanno affrontato il 74° NVLE usando la configurazione più semplice — domande in giapponese e un prompt di istruzione diretto — sono emerse due tendenze chiare. Primo, tutti i modelli hanno reso bene nelle sezioni basate su testo, ma o1 e o3 hanno sistematicamente superato GPT‑4o. Secondo, le prestazioni sono calate nelle sezioni ricche di immagini, tuttavia o1 e o3 sono rimasti sopra la soglia minima ufficiale di superamento, mentre GPT‑4o è rimasto sotto in una di queste sezioni. Complessivamente, GPT‑4o ha risposto correttamente a circa il 78% delle domande, mentre o1 ha raggiunto circa il 92% e o3 circa il 93%. Poiché o3 ha superato leggermente o1 nel punteggio totale, i ricercatori hanno scelto o3 per il resto degli esperimenti.
I prompt o le traduzioni aiutano davvero?
Si è scritto molto sul “prompt engineering” — ovvero la creazione di istruzioni elaborate per ottenere risposte migliori dall’AI — e sulla traduzione delle domande locali in inglese per allinearle ai dati di addestramento dei modelli. Lo studio ha testato direttamente queste idee con il modello o3, confrontando un prompt di risoluzione di base con un prompt più dettagliato e ottimizzato, e le domande in giapponese con versioni prima tradotte in inglese dallo stesso modello. Sorprendentemente, nessuna di queste varianti ha avuto un impatto significativo: o3 ha superato l’esame in modo netto in tutte e sei le combinazioni, e l’approccio più semplice (testo originale in giapponese con il prompt di base) ha funzionato altrettanto bene delle configurazioni più complicate. Ciò suggerisce che, almeno per queste domande veterinarie, i modelli più recenti comprendono già il giapponese in modo affidabile e non richiedono prompt intricati per ottenere prestazioni elevate.
Quanto sono stabili le prestazioni su esami più recenti?
Per verificare se i risultati elevati fossero un caso, il team ha poi sottoposto o3 al 75° (2024) e al 76° (2025) NVLE, usando ancora una volta solo le domande originali in giapponese e il prompt normale. Il modello ha ottenuto punteggi complessivi superiori al 92% in entrambi gli esami e ha superato la soglia di superamento in ogni sezione, incluse le aree con molte immagini. La maggior parte delle domande ha ricevuto la stessa risposta in tre esecuzioni indipendenti, dimostrando che le risposte di o3 erano generalmente stabili anche quando si permetteva un certo grado di casualità. Analizzando gli errori del modello, i ricercatori hanno rilevato che gli sbagli si concentravano in due ambiti: conoscenze veterinarie pratiche (come le leggi veterinarie giapponesi) e medicina clinica, che richiedono regole specifiche del paese e ragionamenti a più passaggi piuttosto che semplice richiamo di fatti.
Cosa significa — e cosa non significa — tutto questo
Lo studio conclude che i modelli di tipo GPT all’avanguardia possono ora superare l’esame di abilitazione veterinaria del Giappone in giapponese, senza trucchi di traduzione o prompt complessi. Per le scuole veterinarie e gli studenti, questo apre la strada all’uso dell’AI come partner di studio, generatore di domande o spiegatore di argomenti d’esame. Per il pubblico, segnala che l’AI sta diventando uno strumento potente per organizzare e condividere conoscenze veterinarie. Tuttavia, gli autori sottolineano che questi sistemi non sono pronti a sostituire i veterinari o a prendere decisioni mediche in autonomia. I modelli possono ancora fraintendere le immagini, avere difficoltà con giudizi clinici sfumati e talvolta inventare fatti. Usati con cautela, possono diventare assistenti preziosi nell’educazione veterinaria e nel supporto informativo — ma la responsabilità per la salute degli animali resterà saldamente nelle mani degli esseri umani.
Citazione: Kako, T., Kato, D., Iguchi, T. et al. Performance evaluation of generative pre-trained transformer on the National Veterinary Licensing Examination in Japan. Sci Rep 16, 4306 (2026). https://doi.org/10.1038/s41598-026-37300-9
Parole chiave: esami di abilitazione veterinaria, modelli linguistici di grandi dimensioni, intelligenza artificiale in medicina, prestazioni di GPT, formazione veterinaria giapponese