Clear Sky Science · it
Un quadro ibrido di selezione delle caratteristiche e interpretabilità per la previsione dell’ossigeno disciolto negli impianti di trattamento dell’acqua potabile
Perché l’ossigeno nell’acqua potabile è importante
L’ossigeno disciolto — le piccole bolle di gas ossigeno mescolate all’acqua — influenza in modo discreto ma decisivo se la nostra acqua potabile rimane limpida, sicura e dal gusto gradevole. Una quantità insufficiente di ossigeno nell’acqua grezza può liberare metalli come ferro e manganese, favorire microrganismi dannosi e rendere il trattamento più difficile e costoso. Questo studio mostra come l’uso intelligente dei dati operativi reali e delle moderne tecniche di apprendimento automatico possa prevedere i livelli di ossigeno in un grande impianto di acqua potabile, aiutando gli operatori a mantenere alta la qualità dell’acqua risparmiando tempo, energia e costi di laboratorio.
Dare respiro al trattamento dell’acqua
In molti bacini e fiumi i livelli di ossigeno variano con le stagioni, l’inquinamento e il movimento delle acque. Quando l’acqua ristagna o è sovraccarica di nutrienti, l’ossigeno può diminuire, creando condizioni che liberano sostanze indesiderate dai sedimenti e favoriscono microrganismi problematici. Negli impianti di trattamento dell’acqua potabile, mantenere livelli di ossigeno adeguati è particolarmente importante per i filtri biologici e per prevenire il rilascio di metalli e di altri composti difficili da rimuovere. Tuttavia, la maggior parte degli studi precedenti si è concentrata sui fiumi o sugli impianti di trattamento delle acque reflue, lasciando una lacuna di conoscenza per i sistemi di acqua potabile trattata, dove fasi di processo come coagulazione, filtrazione e clorazione modificano il comportamento dell’ossigeno in modi peculiari.
Un decennio di dati dal fiume al rubinetto
I ricercatori hanno utilizzato dieci anni di registrazioni giornaliere provenienti da un impianto di trattamento su scala reale ad Ahvaz, in Iran, che tratta l’acqua del fiume Karun per circa 450.000 persone. Hanno impiegato sette proprietà misurate routinariamente nell’acqua in ingresso filtrata — ossigeno disciolto storico, nitrito, cloruro, conducibilità elettrica, torbidità, pH e temperatura — per prevedere il livello di ossigeno nel bacino di uscita dell’impianto. Dopo un attento controllo dei dati, la gestione degli outlier e la standardizzazione delle misure, hanno addestrato due diffusi modelli di apprendimento automatico basati su alberi, Random Forest e XGBoost. Questi modelli apprendono i pattern costruendo molti alberi decisionali e combinandone i risultati, permettendo di catturare relazioni complesse e non lineari senza bisogno di equazioni costruite a mano. 
Trovare i segnali che contano davvero
Una sfida chiave è stata decidere quali delle sette misure in ingresso guidano veramente il comportamento dell’ossigeno e quali invece introducono rumore o complessità non necessaria. Anziché affidarsi a un unico metodo di classificazione, il team ha costruito una pipeline di selezione “ibrida” che ha esaminato i dati da più prospettive. L’Informazione Mutua ha evidenziato le variabili più strettamente legate all’ossigeno, la Riduzione Media dell’Impurità (Mean Decrease in Impurity) ha catturato quali misure sono state più utili all’interno degli alberi, e l’Importanza per Permutazione ha testato quanto peggiorassero le previsioni quando i valori di una variabile venivano mescolati casualmente. Su questo si è aggiunto il metodo SHAP, che ha spiegato, caso per caso, come ciascuna caratteristica ha spostato la previsione verso l’alto o verso il basso, offrendo sia una visione globale sia approfondimenti specifici per istanza. Attraverso queste quattro tecniche, tre input si sono distinti chiaramente: il livello di ossigeno del giorno precedente, la temperatura dell’acqua e la torbidità. Misure come il pH e il nitrito, pur scientificamente rilevanti, hanno contribuito poco a migliorare le previsioni in questo impianto.
Previsioni accurate con modelli più snelli
Concentrandosi sugli input più informativi e scartando quelli meno utili, i ricercatori hanno ridotto la complessità del modello fino al 70 percento mantenendo l’accuratezza quasi invariata. Sia Random Forest che XGBoost hanno riprodotto i livelli misurati di ossigeno in uscita con elevata precisione, spiegando oltre il 93 percento della variabilità e mantenendo errori tipici sotto 0,3 milligrammi per litro — ben entro l’intervallo utile per le operazioni quotidiane. XGBoost ha mostrato prestazioni leggermente migliori nel complesso, ma entrambi i modelli si sono dimostrati robusti anche con un set di input ridotto. Questa efficienza è importante nella pratica: meno misure richieste significano costi di monitoraggio inferiori e previsioni più rapide e affidabili che possono essere integrate nei sistemi di controllo dell’impianto. 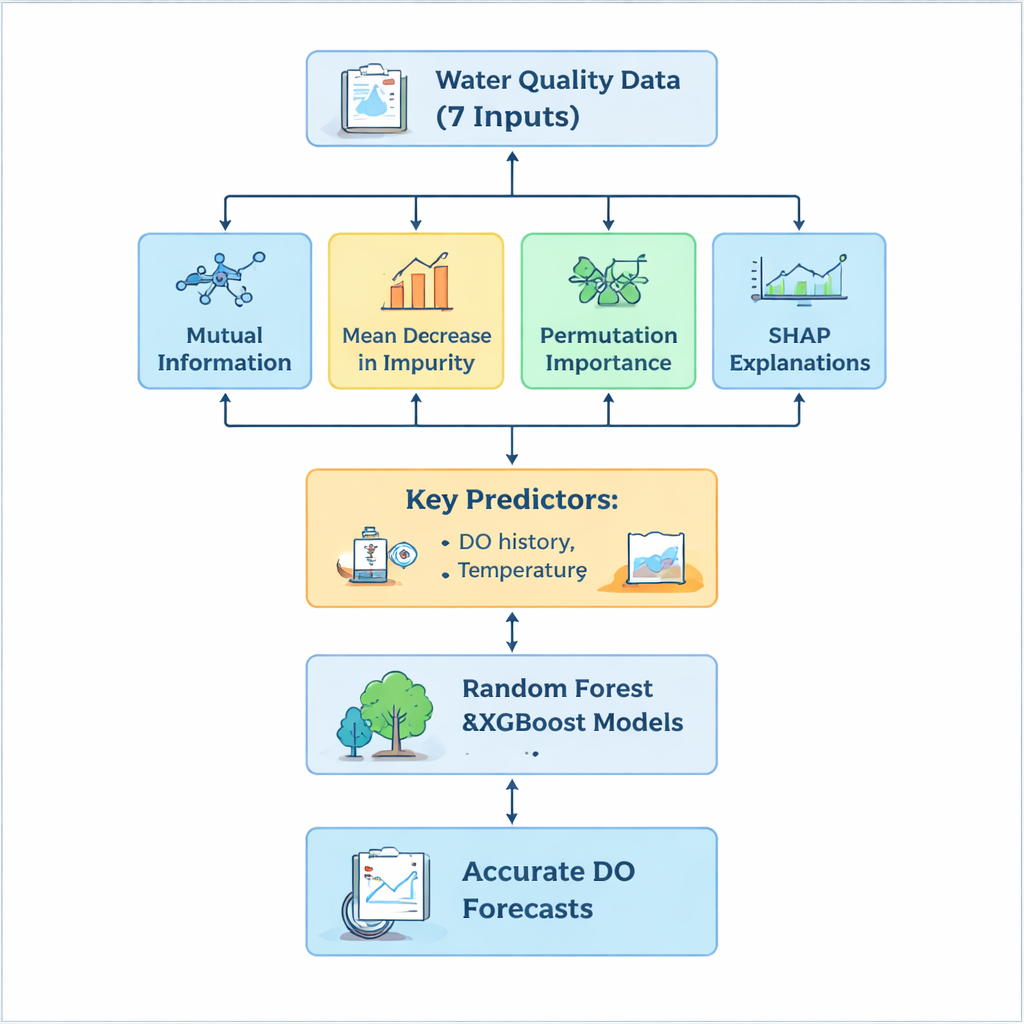
Cosa significa questo per un’acqua potabile sicura ed efficiente
Per i non specialisti, il succo è semplice: permettendo a diversi metodi guidati dai dati di “votare” su quali misure sono più importanti, gli operatori possono costruire strumenti di previsione compatti e trasparenti che stimano in modo affidabile l’ossigeno disciolto in tempo reale. Sapere in anticipo quando l’ossigeno potrebbe calare consente a un impianto di regolare l’aerazione, proteggere i filtri ed evitare condizioni che rilasciano metalli o favoriscono microrganismi dannosi — il tutto evitando l’uso eccessivo di energia e prodotti chimici. Oltre questo singolo impianto e parametro, lo stesso approccio ibrido potrebbe essere applicato ad altre questioni ambientali, dal tracciamento degli inquinanti all’anticipazione delle fioriture algali, offrendo indicazioni più chiare e affidabili dove qualità dell’acqua e salute pubblica si intrecciano.
Citazione: Hoshyarzadeh, R., Hafshejani, L.D., Tishehzan, P. et al. A hybrid framework of feature selection and interpretability for dissolved oxygen prediction in drinking water treatment plants. Sci Rep 16, 6912 (2026). https://doi.org/10.1038/s41598-026-37276-6
Parole chiave: ossigeno disciolto, trattamento dell’acqua potabile, apprendimento automatico, selezione delle caratteristiche, monitoraggio della qualità dell’acqua