Clear Sky Science · it
L'impatto della scelta di K nella cross‑validazione K‑fold su bias e varianza nei modelli di apprendimento supervisionato
Perché verificare il modello due volte conta davvero
Dalla diagnosi medica alla valutazione creditizia, molte decisioni oggi dipendono da modelli di machine learning addestrati su dati storici. Ma come possiamo sapere se un modello che sembra valido sul nostro schermo si comporterà bene su nuovi casi non visti? Un metodo diffuso per "testare" i modelli è la cross‑validazione k‑fold, in cui i dati vengono ripetutamente suddivisi in blocchi per l'addestramento e la verifica. Questo studio pone una domanda apparentemente semplice ma cruciale: quanti blocchi—quanto grande dovrebbe essere k—e in che modo questa scelta influisce, in modo spesso sottile, sull’affidabilità delle prestazioni riportate del modello?
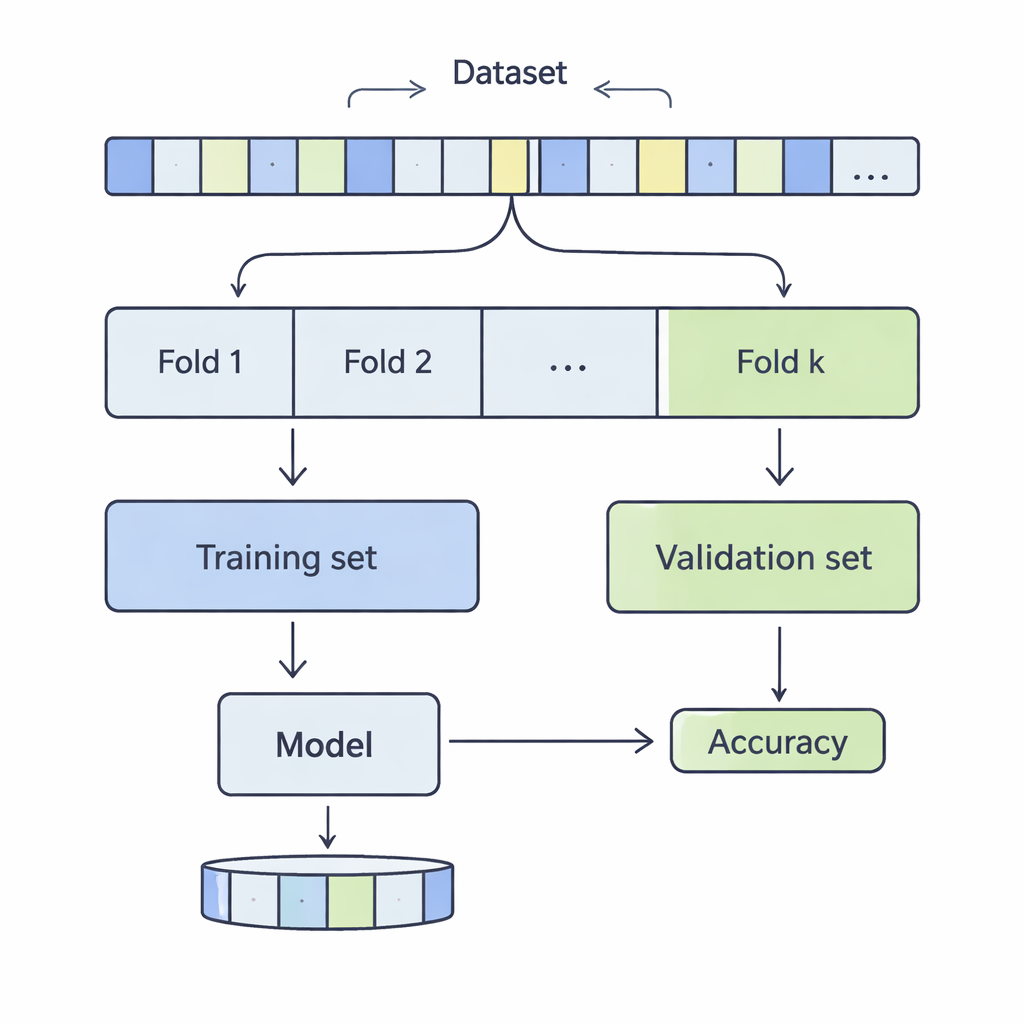
Come vengono tagliati i dati per un controllo di realtà
Nella cross‑validazione k‑fold, un set di dati viene mescolato e diviso in k parti uguali, o fold. Il modello viene addestrato su k‑1 di questi fold e valutato su quello rimanente; il processo si ripete finché ogni fold non ha avuto il suo turno come porzione di test. Gli autori hanno esaminato valori di k da 3 a 20, su 12 dataset reali che vanno da poche migliaia a oltre mezzo milione di record, coprendo ambiti come previsione del reddito, esiti medici, attacchi informatici, giochi e qualità del vino. Hanno applicato quattro metodi di classificazione comuni—Support Vector Machines, Decision Trees, Logistic Regression e k‑Nearest Neighbours—misurando con cura come la scelta di k abbia influenzato due aspetti chiave della prestazione: bias e varianza.
Cosa significano bias e varianza in termini quotidiani
Il bias, in questo contesto, cattura quanto il modello sembri andare meglio durante la cross‑validazione rispetto a quanto realmente performa su un set di test separato e intatto. Un bias positivo elevato significa che il modello appare eccessivamente ottimistico durante la validazione—simile a uno studente che fa bene nei test di pratica ma inciampa nell’esame reale. La varianza riflette quanto le prestazioni del modello oscillino da fold a fold: bassa varianza significa che i punteggi sono stabili attraverso diverse suddivisioni dei dati, mentre alta varianza indica oscillazioni. Idealmente vogliamo che sia bias sia varianza siano bassi, così che l’accuratezza riportata sia sia realistica sia stabile.
Cosa succede aumentando il numero di fold
Su tutti e dodici i dataset e con tutti e quattro gli algoritmi, è emerso un pattern chiaro: all’aumentare di k, la varianza quasi sempre cresceva. In altre parole, usare più fold rendeva l’accuratezza riportata meno stabile da un fold all’altro. Questo contrasta con la credenza comune che più fold diano automaticamente stime migliori e più affidabili. Il motivo è che con k grande, ogni porzione di validazione diventa molto piccola e meno rappresentativa, quindi i risultati diventano più sensibili a particolarità nei dati. Contemporaneamente, il comportamento del bias è stato meno uniforme. Per k‑Nearest Neighbours e Support Vector Machines, il bias tendeva ad aumentare con k, il che significa che questi modelli spesso apparivano più accurati in cross‑validazione di quanto fossero realmente sul test tenuto separato. I Decision Trees hanno mostrato schemi più bilanciati, mentre la Logistic Regression si è posizionata in mezzo, con variazioni di bias miste ma più moderate.
Perché le “impostazioni standard” possono fuorviare
La maggior parte delle guide pratiche suggerisce semplicemente di usare cinque o dieci fold, indipendentemente dal dataset o dall’algoritmo di apprendimento. L’analisi degli autori mostra che questo consiglio "taglia unica" può essere fuorviante. Su alcuni dataset e per alcuni modelli, valori di k più alti amplificavano impressioni eccessivamente ottimistiche delle prestazioni; su tutti i casi, più fold aumentavano la variabilità delle stime. Ciò è particolarmente preoccupante in ambiti ad alto rischio come la sanità, la finanza o le infrastrutture, dove una falsa fiducia nell’accuratezza di un modello può avere conseguenze reali. Lo studio sostiene che gli effetti di k dipendono sia dalla natura dei dati (piccoli vs. grandi, rumorosi vs. più puliti) sia da come il singolo algoritmo apprende da set di addestramento ripetuti e quasi identici.
Messaggio principale per chi usa il machine learning
La lezione centrale è che il numero di fold nella cross‑validazione non è un dettaglio tecnico innocuo—modella direttamente quanto siano affidabili i numeri di accuratezza che ottieni. In questi esperimenti, più fold rendevano costantemente i risultati più instabili e spesso facevano apparire alcuni modelli migliori di quanto fossero in realtà. Piuttosto che scegliere ciecamente k=5 o k=10, gli autori raccomandano di trattare k come una manopola di regolazione: verificare come cambiano i risultati su un piccolo intervallo di valori k e, quando possibile, esaminare più di una metrica di prestazione. Per praticanti e lettori interessati, il messaggio è chiaro: quando si tratta di valutare modelli di machine learning, il modo in cui si suddividono i dati può contare quasi quanto il modello stesso.
Citazione: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
Parole chiave: cross‑validation k‑fold, compromesso bias‑varianza, valutazione del modello, validazione in machine learning, classificazione supervisionata