Clear Sky Science · it
Stima della DOA vettoriale acustica subacquea in ambienti con rumore ibrido basata su un meccanismo sparsamente-gated di mixture-of-experts
Ascoltare segnali nascosti sott’acqua
Navi, sottomarini, robot subacquei e persino biologi marini si affidano all’ascolto di suoni deboli nell’oceano per capire da dove provengono. Ma il mare è un luogo rumoroso: motori, onde, animali e gli strumenti stessi aggiungono disturbo. Questo studio presenta un nuovo modo per individuare la direzione dei suoni subacquei anche quando il rumore è confuso e imprevedibile, utilizzando una moderna forma di intelligenza artificiale che impara a gestire diversi tipi di rumore invece di assumere che tutto sia semplice e uniforme.

Perché trovare la direzione è così difficile nell’oceano
Per localizzare una sorgente sonora, gli ingegneri usano un array di microfoni subacquei, detti idrofoni vettoriali, disposti in linea. Confrontando le piccole differenze nei tempi con cui un suono raggiunge ciascun sensore, possono stimare la direzione da cui è arrivato, un compito noto come stima della direzione di arrivo (DOA). I metodi classici presumono che il rumore di fondo sia come un fruscio uniforme—matematicamente, “rumore gaussiano bianco”. I veri oceani raramente si comportano così bene. Il rumore può essere impulsivo, come scoppiettii improvvisi; colorato, con più energia in certe frequenze; o non uniforme tra i sensori. Questa miscela di comportamenti, chiamata rumore ibrido, rompe le ipotesi su cui si basano gli algoritmi tradizionali, facendo crollare la loro accuratezza proprio quando le condizioni sono più difficili.
Una linea di sensori più intelligente
I ricercatori basano il loro lavoro su un layout di sensori semplice ma potente: una linea retta di cosiddetti idrofoni vettoriali, che misurano sia la pressione sia il moto delle particelle nell’acqua. Quando sorgenti sonore lontane emettono onde, queste raggiungono ciascun sensore con leggere differenze di tempo e fase, a seconda dell’angolo di arrivo. Da queste misure il sistema costruisce una matrice di covarianza—un riassunto compatto di come i segnali sui diversi sensori si correlano nel tempo. Questa matrice contiene gli indizi geometrici necessari per inferire la direzione, ma è intrisa di tutto il rumore complesso presente nell’ambiente.
Trasformare dati rumorosi in pattern apprensibili
Le reti neurali tipicamente lavorano con numeri reali, ma la matrice di covarianza è a valori complessi. Il team quindi la divide in due matrici reali, che rappresentano la parte reale e quella immaginaria, e le alimenta come un “immagine” a due canali in una rete neurale convoluzionale (CNN). Questa CNN scansiona la matrice per scoprire pattern spaziali che distinguono la vera struttura del segnale dal rumore. Invece di affidarsi a formule progettate a mano, la CNN impara queste caratteristiche direttamente dai dati, costruendo gradualmente dalle relazioni locali semplici a pattern di livello superiore informativi per la localizzazione delle sorgenti sonore.
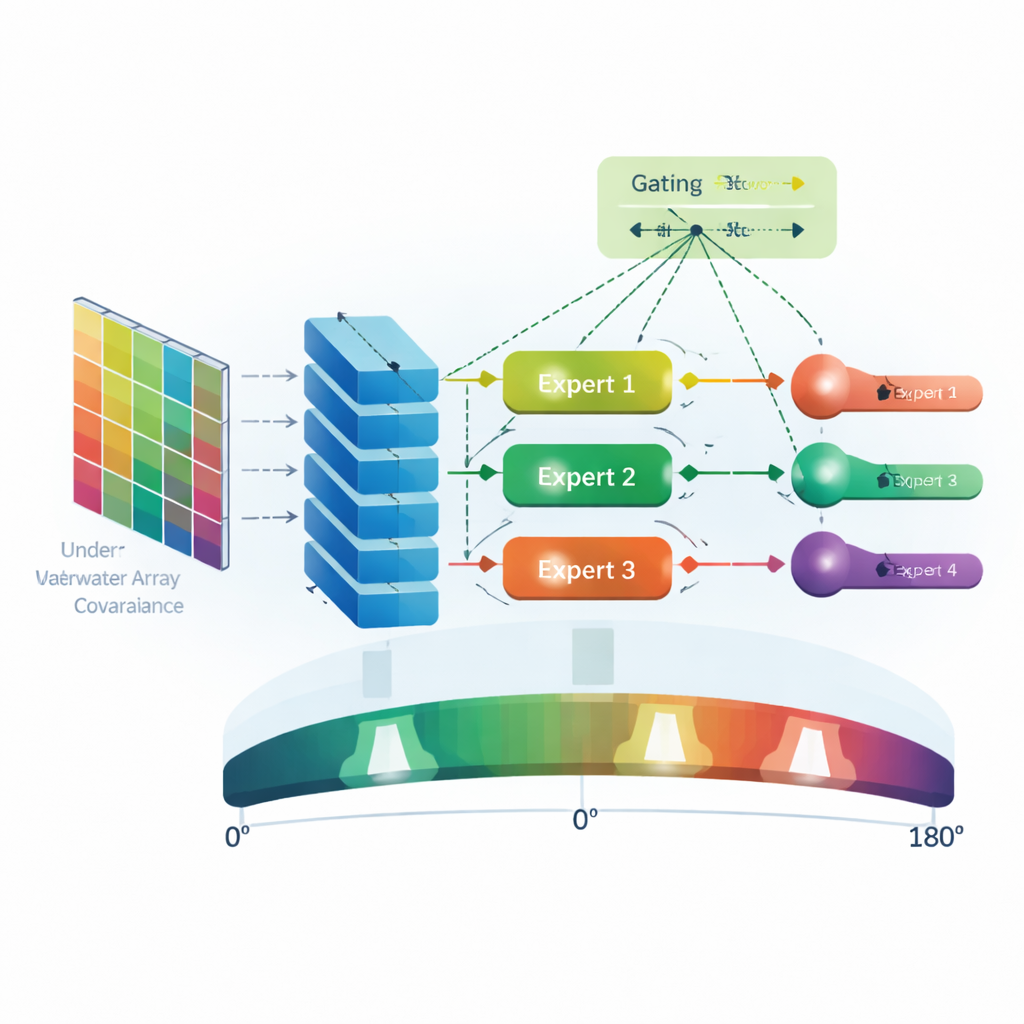
Molti specialisti e un coordinatore intelligente
L’innovazione chiave è ciò che avviene dopo la CNN: una rete mixture-of-experts con gating sparsamente attivato (SMoE). Piuttosto che un unico modello monolitico che prova a gestire ogni situazione, il sistema include diversi piccoli esperti, ciascuno addestrato per eccellere sotto un tipo specifico di rumore, come bianco, pink, red, blue, violetto o rumore impulsivo. Una rete di gating separata osserva le caratteristiche estratte dalla CNN e, per ciascun esempio in ingresso, decide quali pochi esperti sono più pertinenti. Solo questi esperti selezionati vengono attivati e i loro output vengono combinati per produrre una stima finale della probabilità che una sorgente sonora sia a ciascun angolo tra 0° e 180°. Questo progetto rende il modello sia adattivo—perché cambia gli esperti a cui si affida al variare delle condizioni di rumore—sia efficiente, perché evita di eseguire tutti gli esperti continuamente.
Testare in condizioni difficili e realistiche
Per addestrare questo sistema, gli autori hanno prima generato dati in cui ogni esperto vedeva un solo tipo di rumore, permettendogli di specializzarsi. Poi hanno addestrato la rete di gating su miscele delle sei tipologie di rumore, emulando ambienti ibridi reali. Hanno inoltre valutato il modello su un ampio set di test realistico che include sia rumore simulato sia rumore subacqueo registrato effettivamente, su un’ampia gamma di rapporti segnale-rumore e durate dei dati. Rispetto a tecniche classiche note e ad altri approcci di deep learning, il modello SMoE ha fornito costantemente errori minori e tassi di successo più alti, in particolare quando il rumore era intenso o quando era disponibile solo una quantità limitata di dati. A un rapporto segnale-rumore di 0 dB—dove potenza del segnale e del rumore sono uguali—il modello ha raggiunto un errore angolare medio inferiore a un grado, mentre i metodi concorrenti potevano sbagliare di molti gradi.
Cosa significa questo per il futuro del sensing subacqueo
In termini semplici, questo lavoro mostra che lasciare che più “ascoltatori” IA specializzati condividano il compito, e scegliere tra loro in tempo reale, può migliorare drasticamente la nostra capacità di determinare da dove provengono i suoni subacquei in condizioni caotiche e rumorose. L’approccio può essere adattato ad altri layout di sensori oltre ai semplici array lineari, e la stessa idea—mixture-of-experts con un gate intelligente—potrebbe essere utile in radar, robotica e altri campi in cui i segnali devono essere localizzati in presenza di interferenze complesse. Per applicazioni che dipendono da un ascolto subacqueo affidabile, dalla navigazione al monitoraggio ambientale, questo metodo offre un modo più flessibile e robusto per sentire attraverso il rumore.
Citazione: Xu, W., Yi, S., Gu, H. et al. Underwater acoustic vector DOA estimation in hybrid noise environments based on sparsely-gated mixture-of-experts mechanism. Sci Rep 16, 6192 (2026). https://doi.org/10.1038/s41598-026-37217-3
Parole chiave: acustica subacquea, direzione di arrivo, rumore ibrido, deep learning, mixture of experts