Clear Sky Science · it
Un metodo per rilevare elmetti di sicurezza in ambienti sotterranei basato sul modello YOLOv11-SRA
Perché controlli degli elmetti più intelligenti sono importanti sottoterra
In profondità nelle miniere e nei tunnel, i lavoratori si affidano agli elmetti di sicurezza come ultima linea di difesa contro il distacco di rocce, i macchinari e i soffitti bassi. Tuttavia, in passaggi bui, polverosi e affollati è difficile per i supervisori — e persino per le telecamere convenzionali — capire chi sia davvero protetto. Questo articolo presenta un nuovo sistema di visione artificiale, basato su un modello migliorato chiamato YOLOv11-SRA, in grado di individuare automaticamente elmetti e teste scoperte in tempo reale, anche quando la luce è scarsa, le visuali sono ostruite e le persone sono lontane dalla telecamera.
I rischi di fare affidamento sui controlli umani
Le ispezioni tradizionali degli elmetti nelle miniere si basano ancora in larga misura su personale che percorre i tunnel per cercare violazioni, o su tornelli e posti di controllo che i lavoratori devono attraversare. Questi metodi sono lenti, coprono solo pochi punti e possono non cogliere comportamenti a rischio una volta che le persone si spostano più in profondità. Gli elmetti con sensori, tag o elettronica integrata offrono una certa automazione, ma sono costosi, difficili da mantenere in condizioni difficili e richiedono la modifica di ogni elmetto. Con l’espansione delle attività minerarie e turni di lavoro più lunghi, questi approcci tradizionali faticano a garantire la sorveglianza continua e diffusa necessaria per prevenire incidenti.
Insegnare alle telecamere a riconoscere gli elmetti in condizioni difficili
I progressi recenti nel deep learning hanno trasformato il modo in cui i computer interpretano le immagini, specialmente nel riconoscere oggetti come auto o pedoni. La famiglia di algoritmi YOLO è ampiamente utilizzata perché può analizzare un’immagine e localizzare gli oggetti in un unico passaggio veloce — ideale per video in diretta. Tuttavia, le scene sotterranee mettono questi sistemi alla prova. Gli elmetti possono apparire come piccole macchie colorate su una testa distante, essere parzialmente nascosti da tubi o macchinari, o confondersi con lo sfondo sotto un’illuminazione debole e disomogenea. Gli autori hanno progettato YOLOv11-SRA specificamente per affrontare questi problemi, così che le telecamere in miniera possano distinguere con affidabilità tra lavoratori protetti e non protetti.
Un aggiornamento in tre parti per un motore di visione popolare
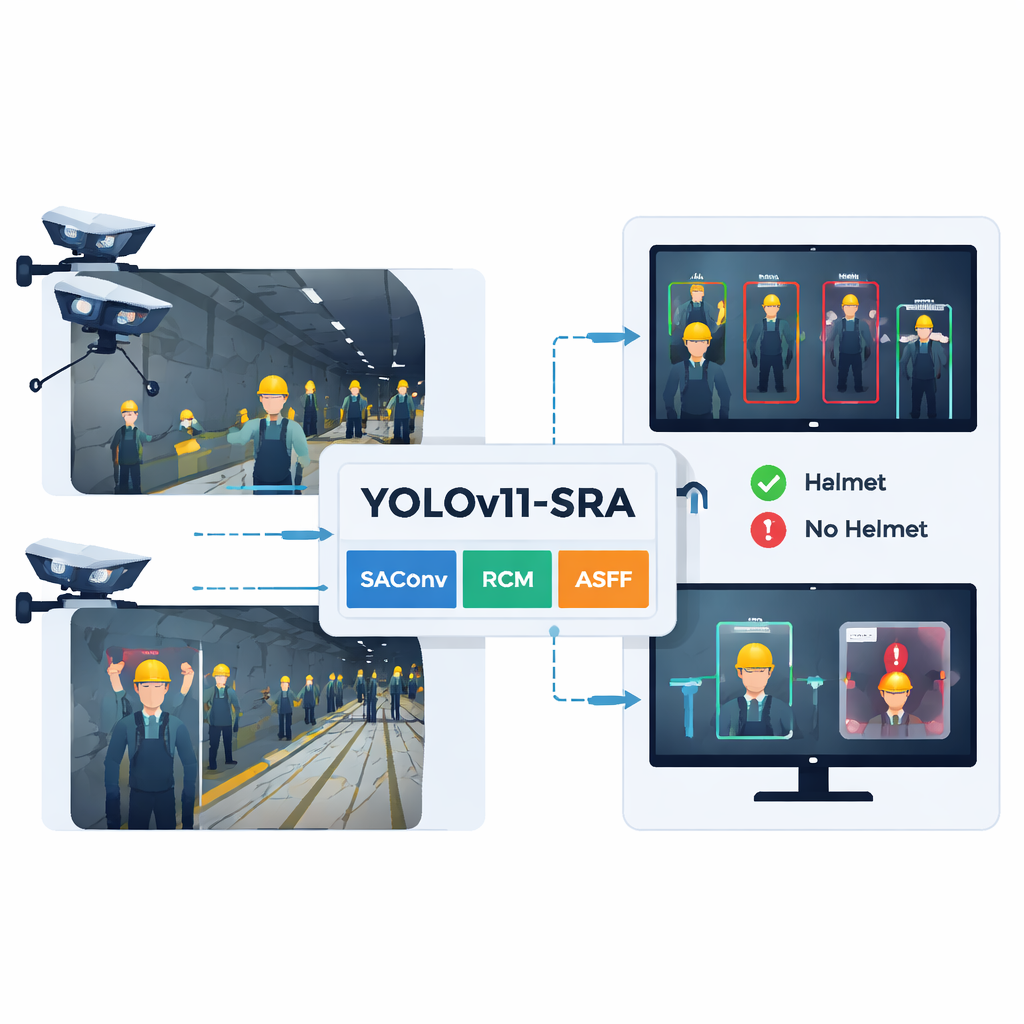
Il nuovo modello conserva la struttura generale di YOLOv11 — input, backbone, neck e detection head — ma aggiunge tre moduli specializzati. Primo, il blocco SAConv consente alla rete di osservare ciascuna immagine su più “livelli di zoom” contemporaneamente, permettendo di cogliere sia piccoli elmetti lontani sia quelli più grandi in primo piano senza costi aggiuntivi. Secondo, il blocco RCM guida il modello a concentrarsi su regioni lunghe e rettangolari che corrispondono alla forma tipica di testa e spalle in un tunnel, aiutando a tracciare i contorni dell’elmetto anche quando attrezzature o altri lavoratori ostacolano la vista. Terzo, il blocco ASFF fonde informazioni provenienti da più scale dell’immagine, permettendo al sistema di scegliere, pixel per pixel, quale livello descrive meglio ogni parte della scena. Insieme, questi aggiornamenti riducono la confusione tra elmetti e rumore di sfondo e affinano i contorni di elmetti piccoli o parzialmente visibili.
Mettere il sistema alla prova
Per verificare l’efficacia di queste idee, i ricercatori hanno addestrato e testato il modello sul dataset CUMT-HelmeT, una raccolta pubblica di immagini di sorveglianza sotterranea annotate con casi “elmetto” e “senza elmetto”, oltre ad altri oggetti comuni. Poiché il dataset grezzo è relativamente piccolo, lo hanno ampliato cinque volte ritagliando, ruotando e schiarendo le immagini per simulare diverse angolazioni delle telecamere e condizioni di illuminazione. Su questo benchmark impegnativo, YOLOv11-SRA ha raggiunto una mean average precision di circa l’84% e un recall vicino all’80%, superando nettamente diversi rilevatori noti, incluse versioni più recenti di YOLO, RetinaNet, SSD e Faster R-CNN. Nonostante la maggiore accuratezza, il modello resta compatto ed efficiente: usa meno parametri e meno calcolo rispetto alla maggior parte dei concorrenti e può analizzare quasi 100 immagini al secondo su una moderna GPU, sufficientemente veloce per gli avvisi in tempo reale.
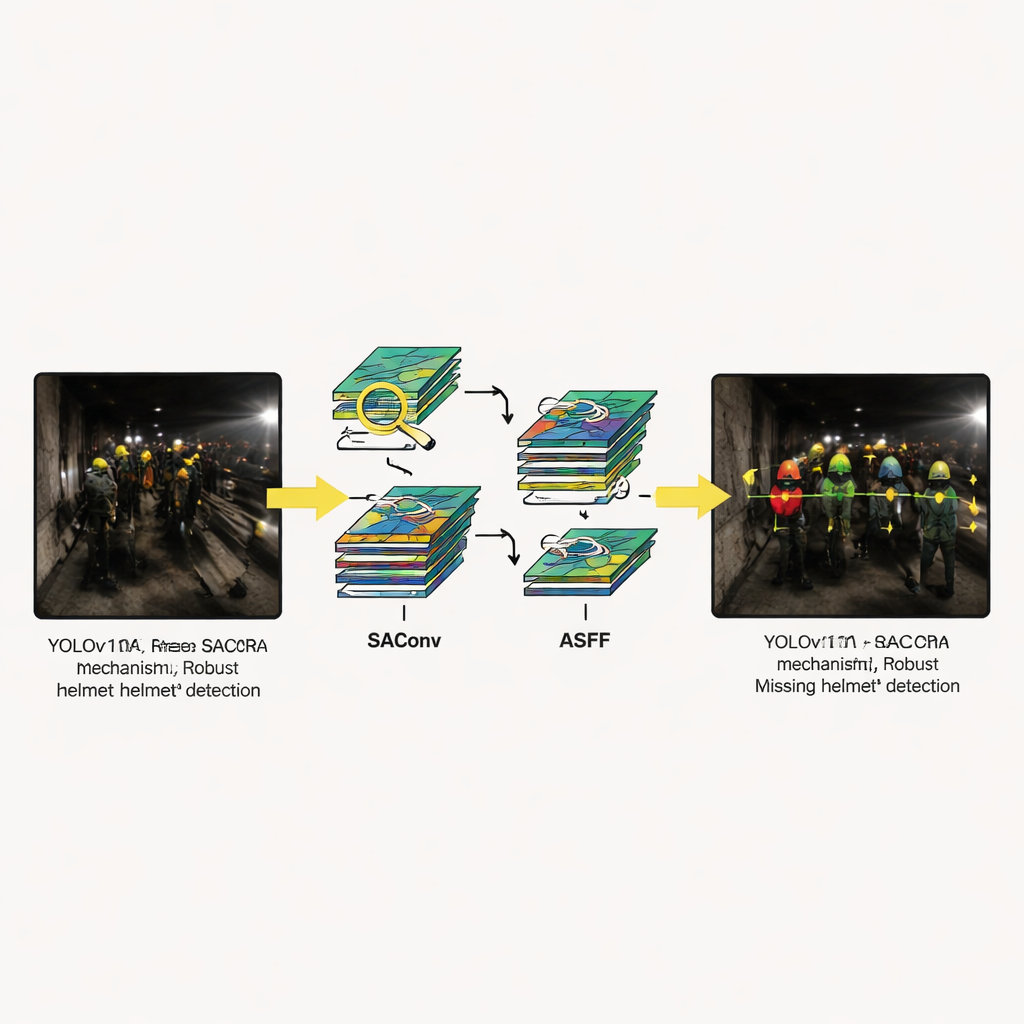
Vedere attraverso oscurità, polvere e riflessi
Esempi visivi mostrano come il sistema si comporti in situazioni che spesso confondono i metodi più datati: elmetti parzialmente occultati, scene illuminate solo da lampade deboli, lavoratori lontani dalla telecamera e forti riflessi su superfici lucide. In ogni caso, YOLOv11-SRA produce rilevazioni più sicure e coerenti rispetto ai modelli concorrenti. È meno propenso a perdere elmetti piccoli o poco luminosi e più abile nell’evitare falsi allarmi quando punti luminosi o tubi imitano i colori degli elmetti. Gli studi di ablazione — in cui gli autori attivano o disattivano singoli moduli — mostrano che ogni componente apporta benefici, ma che i guadagni maggiori si ottengono quando tutti e tre sono combinati, confermando che il progetto funziona come un insieme integrato piuttosto che come una raccolta di trucchi isolati.
Da prototipo di ricerca a turni più sicuri
In termini accessibili, questo lavoro equivale a dotare le telecamere delle miniere di un “occhio” più nitido e adattabile per l’equipaggiamento protettivo di base. Segnalando in modo più affidabile i lavoratori privi di elmetto, anche nei flussi video rumorosi e con scarsa illuminazione, il sistema YOLOv11-SRA potrebbe aiutare i supervisori a intervenire prima e ridurre il rischio di traumi alla testa. Poiché il modello è relativamente leggero, può essere distribuito su dispositivi embedded vicino alle telecamere anziché soltanto in data center remoti. Gli autori osservano che dati di addestramento più ampi e ulteriori ottimizzazioni potrebbero rendere l’approccio ancora più robusto, ma i risultati ottenuti indicano già una direzione verso un monitoraggio della sicurezza più intelligente e scalabile nelle impegnative condizioni delle miniere sotterranee moderne.
Citazione: Wang, L., Wan, X., Shi, X. et al. A method for detecting safety helmets underground based on the YOLOv11-SRA model. Sci Rep 16, 6194 (2026). https://doi.org/10.1038/s41598-026-37148-z
Parole chiave: sicurezza nelle miniere sotterranee, rilevamento elmetti, visione artificiale, monitoraggio in tempo reale, deep learning