Clear Sky Science · it
Analisi comparativa di modelli supervisionati e ensemble con esplorazione non supervisionata per la previsione della malattia di Alzheimer
Perché un allarme precoce è importante
La malattia di Alzheimer sottrae progressivamente memoria e autonomia alle persone, spesso molto prima che venga formulata una diagnosi certa. Famiglie, medici e sistemi sanitari traggono vantaggio dalla rilevazione precoce dei segnali d’allarme, perché è in quella fase che terapia, pianificazione e supporto possono fare la differenza maggiore. Questo studio pone una domanda pratica: programmi informatici accuratamente progettati, addestrati su informazioni cliniche di routine e dati di tomografia cerebrale, possono individuare la demenza in modo più affidabile rispetto agli strumenti standard odierni — e al contempo rivelare pattern nascosti nello sviluppo della malattia?
Trasformare le cartelle cliniche in segnali utilizzabili
I ricercatori si sono basati su una nota raccolta di dati chiamata OASIS-2, che segue 150 anziani di età compresa tra 60 e 96 anni per diversi anni. Per ogni visita il dataset include informazioni di base come età, anni di istruzione e stato socioeconomico, oltre a punteggi di test cognitivi e misure ricavate da risonanze magnetiche cerebrali, come il volume cerebrale complessivo. Prima di qualsiasi previsione, il gruppo ha pulito i dati, rimosso identificatori e casi ambigui, riempito un piccolo numero di valori mancanti e normalizzato tutte le misure numeriche su una scala comune. Hanno inoltre affrontato un problema chiave del mondo reale: nel dataset le persone sane erano molto più numerose di quelle con demenza. Per evitare che i modelli si limitassero a indovinare “nessuna demenza” nella maggior parte dei casi, i ricercatori hanno impiegato schemi di ponderazione che fanno pesare maggiormente durante l’addestramento gli errori sul gruppo più piccolo dei demented.
Confrontare strumenti classici con team di modelli
Con questo dataset preparato, gli autori hanno confrontato noti strumenti di machine learning con ensemble più sofisticati, che combinano diversi modelli in un predittore più potente. Il gruppo classico includeva regressione logistica, alberi decisionali, macchine a vettori di supporto e foreste casuali. Il gruppo degli ensemble comprendeva AdaBoost, XGBoost e un modello a voto di maggioranza che mischiava tre classificatori ottimizzati. Tutti i modelli sono stati addestrati su una porzione dei dati e testati su casi esclusi dall’addestramento, valutando le prestazioni tramite accuratezza, la capacità di individuare correttamente gli individui con demenza (recall) e l’area sotto la curva ROC, un sommario di quanto bene il modello separa casi sani da casi malati. 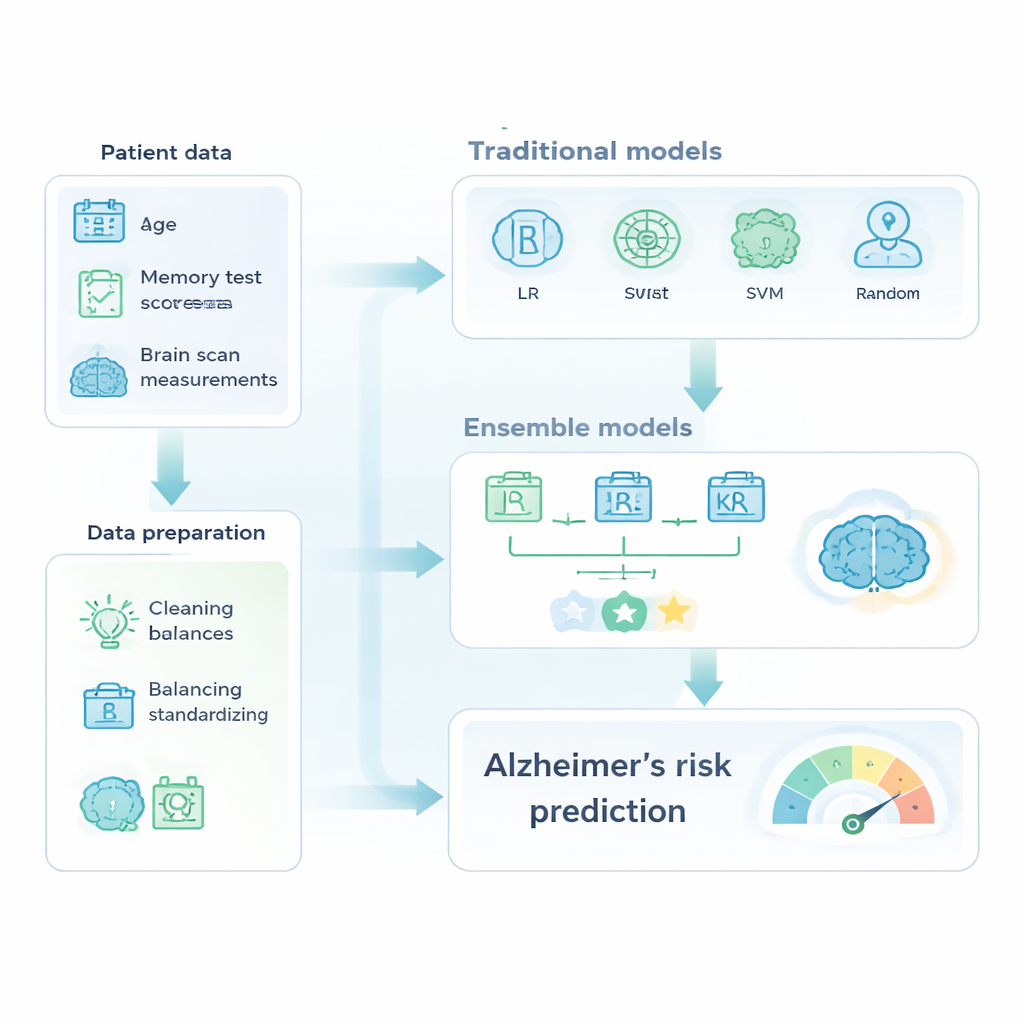
Quando più menti battono una sola
I risultati del confronto sono stati chiari. Mentre i migliori metodi tradizionali hanno mostrato prestazioni ragionevoli, si sono stabilizzati intorno ai livelli riportati in studi precedenti, con accuratezze nei test nella fascia bassa-medio dell’80 percento. Al contrario, l’ensemble a voto di maggioranza ha raggiunto circa il 95 percento di accuratezza e un punteggio ROC altrettanto elevato, superando il riferimento comunemente citato del 92 percento. Anche AdaBoost e altri modelli ensemble hanno fatto meglio di qualsiasi singolo modello tradizionale. Questo vantaggio deriva dal fatto che algoritmi diversi colgono aspetti differenti dei dati; permettendo loro di “votare”, l’ensemble attenua caratteristiche peculiari e overfitting dei singoli, ottenendo previsioni più stabili. Il prezzo di questo guadagno è una minore trasparenza: è più difficile capire, a prima vista, perché un ensemble abbia preso una decisione particolare rispetto a una semplice regressione o a un singolo albero. 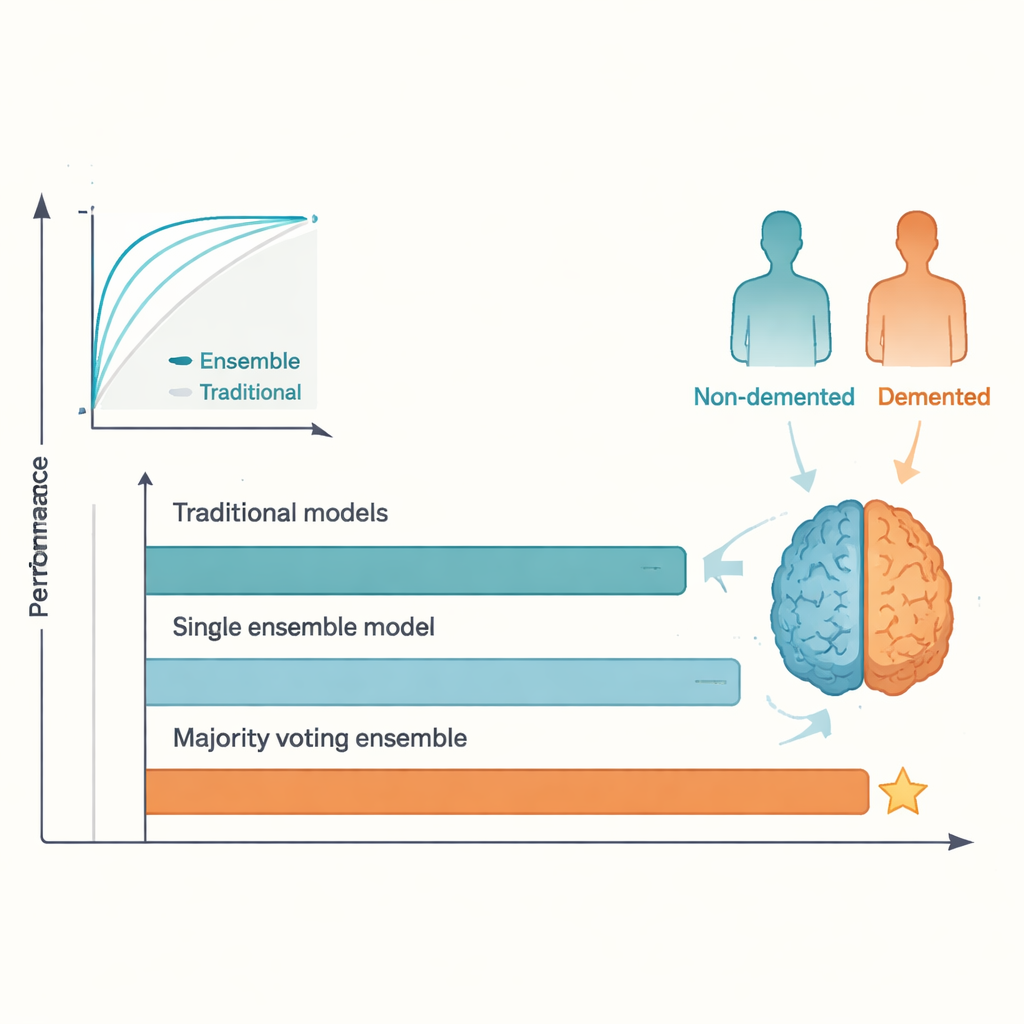
Cercare raggruppamenti naturali nei dati
Oltre a chiedersi chi ha la demenza, i ricercatori hanno esaminato anche come i pazienti si raggruppano naturalmente, indipendentemente dalle etichette diagnostiche. Per farlo hanno trasformato tutte le variabili continue in categorie ordinate — ad esempio intervalli di età o di volume cerebrale — e applicato una tecnica chiamata analisi delle corrispondenze multiple per comprimere queste informazioni ricche in poche dimensioni sottostanti. Successivamente hanno usato il clustering k-means per dividere questi punti in un piccolo numero di gruppi coerenti. Alcuni cluster erano dominati da persone con volume cerebrale preservato e punteggi cognitivi normali, mentre altri contenevano individui con basso volume cerebrale, risultati peggiori ai test e valutazioni di demenza più severe. Il fatto che questi cluster non supervisionati si allineassero bene con lo stato clinico suggerisce che i dati contengono un segnale forte e consistente sul rischio e sulla progressione della malattia.
Cosa significa per pazienti e clinici
Per il pubblico generale, la conclusione è semplice: se progettati con cura, i team di modelli di machine learning possono individuare la demenza correlata all’Alzheimer nei dati clinici strutturati più accuratamente rispetto ai metodi tradizionali, e possono farlo utilizzando informazioni che molte cliniche già raccolgono. Allo stesso tempo, le tecniche esplorative rivelano che le persone si distribuiscono in profili distinti di salute cerebrale e funzione cognitiva, suggerendo percorsi diversi che la malattia potrebbe seguire. Sebbene lo studio sia limitato dalle dimensioni modeste del campione e dalla complessità nell’interpretare i modelli ensemble, dimostra che combinare predizione potente con analisi esplorativa accurata può sia migliorare la rilevazione precoce sia approfondire la nostra comprensione di come l’Alzheimer si manifesta.
Citazione: Amr, Y., Gad, W., Leiva, V. et al. Comparative analysis of supervised and ensemble models with unsupervised exploration for alzheimer’s disease prediction. Sci Rep 16, 7322 (2026). https://doi.org/10.1038/s41598-026-37122-9
Parole chiave: Malattia di Alzheimer, predizione della demenza, apprendimento automatico, modelli ensemble, imaging cerebrale