Clear Sky Science · it
Sistema di assegnazione esperti basato sull’elaborazione del linguaggio naturale per le azioni Marie Sklodowska-Curie
Perché scegliere l’esperto giusto è davvero importante
Quando migliaia di proposte di ricerca competono per fondi limitati, tutto dipende da chi le valuta. Se gli esperti assegnati non comprendono davvero l’argomento di una proposta, idee promettenti possono essere fraintese o trascurate. Questo articolo esplora come l’intelligenza artificiale, in particolare i moderni sistemi di elaborazione del linguaggio, possa aiutare ad abbinare le proposte con i migliori esperti possibili in modo più accurato e più equo rispetto agli strumenti odierni basati sulle parole chiave.
Il problema delle liste di parole chiave
Finora, l’assegnazione degli esperti nei principali programmi di finanziamento europei, come le borse postdottorato Marie Skłodowska-Curie, si è basata in larga misura sulle parole chiave. La piattaforma attuale scansiona le descrizioni delle proposte e i profili dei valutatori per trovare termini corrispondenti, quindi suggerisce tre esperti più alternative. Ma i Vicepresidenti—scienziati senior che supervisionano il processo—finiscono per modificare circa il 40% di queste assegnazioni. Questo livello di correzione umana rende il sistema laborioso, lento e in qualche misura opaco, soprattutto quando ogni anno arrivano fino a 10.000 proposte, spesso in aree emergenti dove liste di parole chiave fisse funzionano male.
Leggere la ricerca come un essere umano, su scala
Gli autori hanno sviluppato un nuovo sistema di assegnazione che cerca di “leggere” la ricerca più come farebbe un esperto umano. Invece di affidarsi a etichette, raccoglie le pubblicazioni di ogni esperto tramite ORCID, un sistema globale di identificazione dei ricercatori, e costruisce un database di oltre 2.800 riassunti di articoli. Sia gli abstract delle proposte sia gli abstract delle pubblicazioni sono quindi elaborati da GALACTICA, un grande modello linguistico addestrato specificamente su testi scientifici. GALACTICA trasforma ciascun abstract in un’impronta numerica che cattura il suo significato, non solo la formulazione. Confrontando queste impronte, il sistema può stimare quanto il contenuto di una proposta si allinei con il lavoro passato di ciascun esperto.
Tre modi per sommare l’esperienza
Una sfida è che gli esperti possono avere dozzine di pubblicazioni. Il sistema necessita di un punteggio unico per esperto e proposta, così gli autori hanno testato tre semplici modi per combinare le similarità. La strategia Somma aggiunge tutti i punteggi di similarità, premiando rilevanza ampia e ripetuta. La strategia Prodotto li moltiplica, enfatizzando la similarità consistente attraverso molte pubblicazioni ma penalizzando severamente ogni corrispondenza debole. La strategia Massimo mantiene solo la corrispondenza singola più forte, assumendo che un articolo molto correlato possa essere sufficiente per giustificare un’assegnazione. Questi punteggi sono poi usati per classificare 48 esperti candidati per ciascuna delle 181 proposte, e le classifiche sono confrontate con le scelte finali degli esperti fatte dai Vicepresidenti.
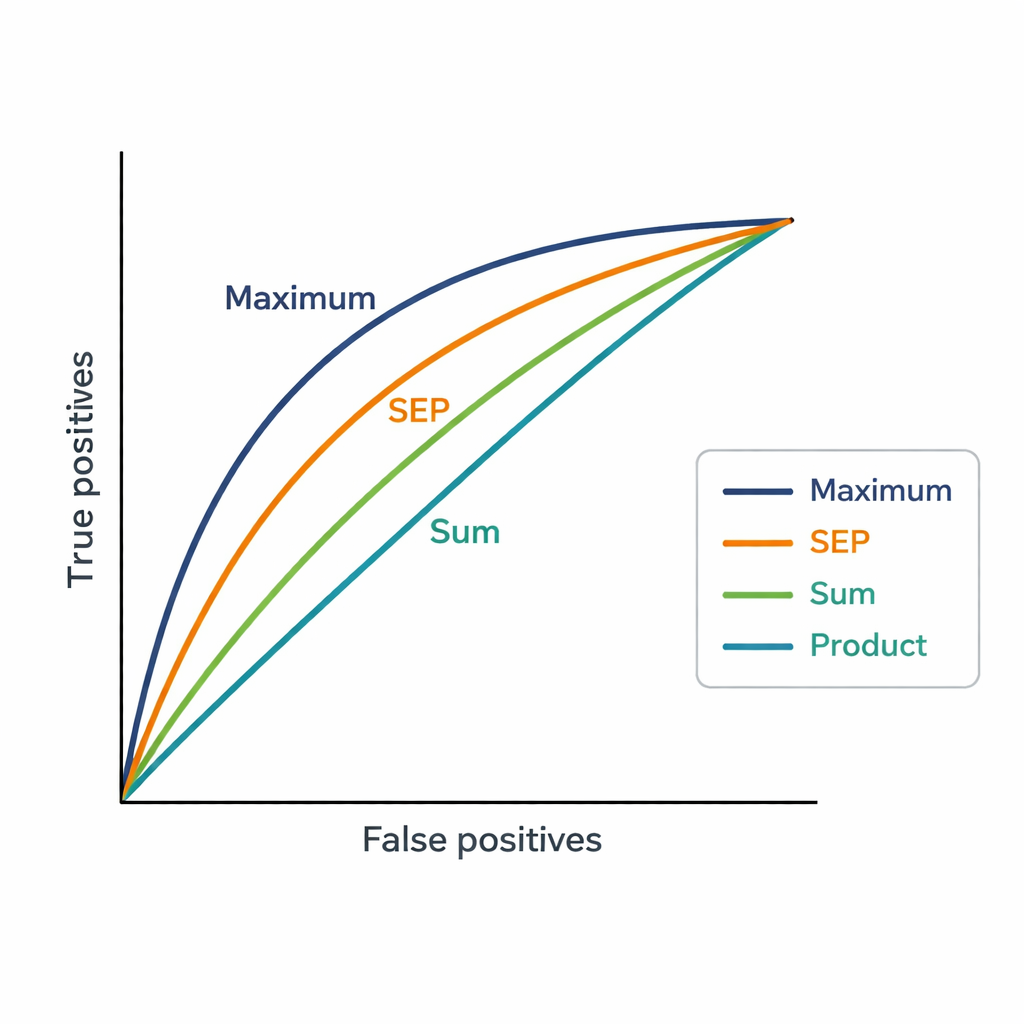
Cosa rivelano i numeri sulle scelte umane
La strategia Massimo ha corrisposto più da vicino alle decisioni dei Vicepresidenti, raggiungendo un AUC di 0,82, migliore sia del sistema esistente basato su parole chiave (AUC 0,75) sia delle altre metodologie di aggregazione. In pratica, l’esperto scelto dai Vicepresidenti appariva di solito fra le prime quattro proposte prodotte dalla strategia Massimo. Questo suggerisce che, nell’assegnazione dei valutatori, le persone tendono a concentrarsi sul fatto che esista almeno una connessione molto forte tra il lavoro precedente di un esperto e una proposta, piuttosto che esigere che tutte le pubblicazioni dell’esperto siano allineate. Il nuovo metodo genera inoltre punteggi molto più sfumati rispetto ai grossolani livelli di “affinità” della piattaforma, permettendo una distinzione più chiara tra esperti con classifiche ravvicinate.
Cosa significa per le future revisioni dei finanziamenti
Per un lettore non specialista, la conclusione è semplice: usando un’IA che comprende il linguaggio scientifico, le agenzie di finanziamento possono abbinare meglio le proposte agli esperti giusti, ridurre le correzioni manuali e rendere il processo più coerente e trasparente. Sebbene diversi modi di combinare le prove tratte dalle pubblicazioni mettano in luce aspetti differenti dell’esperienza, la semplice regola del “miglior singolo riscontro” sembra rispecchiare il modo in cui gli esseri umani decidono realmente. Man mano che tali sistemi vengono testati su scala più ampia e con modelli linguistici più recenti, potrebbero diventare una componente chiave per una valutazione della ricerca più equa ed efficiente a livello globale.
Citazione: Álvarez-García, E., García-Costa, D., De Waele, I. et al. Expert assignment system based on natural language processing for Marie Sklodowska-Curie actions. Sci Rep 16, 6396 (2026). https://doi.org/10.1038/s41598-026-37115-8
Parole chiave: revisione tra pari, abbinamento esperti, finanziamento della ricerca, elaborazione del linguaggio naturale, modelli linguistici di grandi dimensioni