Clear Sky Science · it
Studio comparativo sulla previsione delle metastasi a distanza postoperatorie del cancro polmonare basato su modelli di apprendimento automatico
Perché prevedere la diffusione del cancro è importante
Il cancro del polmone resta una delle neoplasie più letali, anche quando i chirurghi asportano tutti i tumori visibili. Molti pazienti in seguito sviluppano depositi di malattia nascosti che compaiono nel cervello, nelle ossa, nel fegato o in altri organi. I medici vorrebbero sapere, poco dopo l’intervento, quali pazienti hanno maggior probabilità di presentare questo tipo di diffusione a distanza per poter personalizzare le visite di controllo e le terapie. Questo studio indaga se i moderni programmi informatici, noti come modelli di apprendimento automatico, possano aiutare a prevedere chi è a rischio più elevato, usando informazioni che gli ospedali raccolgono già nella pratica routinaria.
Analisi approfondita su un ampio numero di pazienti
I ricercatori hanno esaminato le cartelle di 3.120 persone con cancro del polmone in stadio I-III che avevano subito la rimozione del tumore presso un unico centro oncologico in Cina. Tutti avevano almeno due anni di follow-up. Per ogni paziente il team ha raccolto 52 tipi di informazioni, tra cui età, sesso, peso corporeo, storia di fumo, reperti radiologici, dettagli dell’intervento, esami di laboratorio e se avessero ricevuto terapie aggiuntive come chemioterapia o radioterapia dopo l’operazione. Nel tempo 596 di questi pazienti hanno sviluppato metastasi a distanza, mentre 2.524 non l’hanno fatto. Questa combinazione di dati del mondo reale ha permesso al gruppo di vedere quali variabili fossero associate alla diffusione futura.
Insegnare ai computer a riconoscere i pattern di rischio
Invece di affidarsi a un’unica formula, gli scienziati hanno confrontato nove diversi metodi di apprendimento automatico, dagli alberi decisionali semplici a tecniche più avanzate che combinano molti modelli più piccoli. Hanno innanzitutto applicato un filtro matematico per ridurre i 52 fattori iniziali a un sottoinsieme più informativo. Poi, in ripetute iterazioni, hanno addestrato ciascun modello su una parte dei dati e lo hanno testato su pazienti che non aveva mai “visto” prima. Poiché solo circa uno su cinque pazienti ha sviluppato metastasi, hanno bilanciato l’addestramento in modo che il sistema non limitasse le previsioni a “basso rischio” per tutti. Hanno valutato le prestazioni usando diverse misure, tra cui quanto bene i modelli separassero pazienti ad alto e basso rischio e quanto le probabilità previste corrispondessero a quanto osservato nella realtà.
Trovare il modello più affidabile
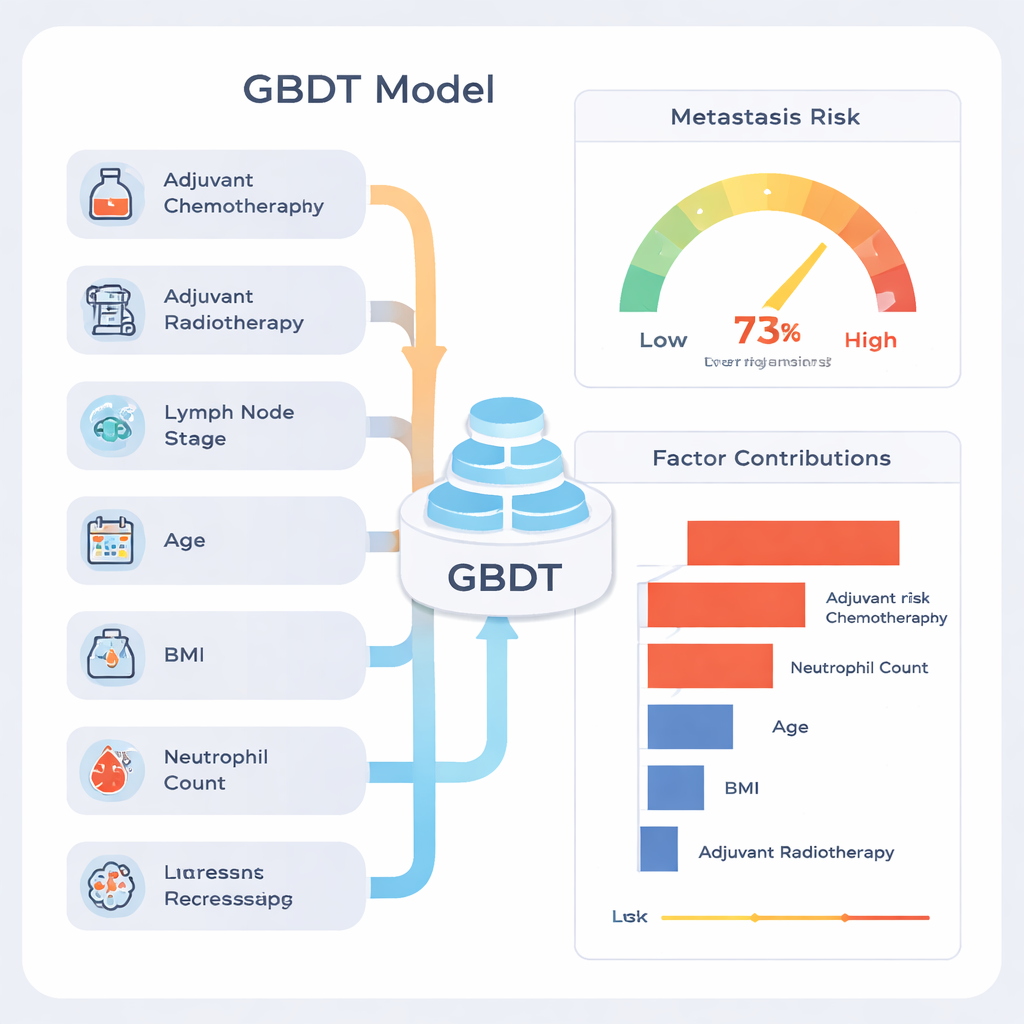
Tra i nove approcci, uno chiamato Gradient Boosting Decision Tree (GBDT) è emerso come il più efficace. Sui dati di test ha classificato correttamente i pazienti con una accuratezza complessiva di circa il 77% e il suo punteggio riassuntivo per la discriminazione (l’area sotto la curva ROC) è stato 0,81, valore considerato solido per strumenti predittivi in medicina. Il modello si è dimostrato particolarmente abile nell’identificare i pazienti che sarebbero rimasti senza metastasi (alto “valore predittivo negativo”), il che significa che un risultato a basso rischio era generalmente rassicurante. Quando il team ha esaminato il comportamento del modello su molteplici suddivisioni casuali dei dati, le prestazioni sono rimaste stabili, suggerendo che non stava semplicemente memorizzando caratteristiche specifiche di un singolo sottoinsieme.
Cosa guida le decisioni del modello
Una critica comune all’apprendimento automatico è che può funzionare come una “scatola nera”. Per affrontare questo aspetto, gli autori hanno utilizzato un metodo di spiegazione chiamato SHAP, che assegna a ciascun fattore un contributo alla stima finale del rischio per ogni paziente. Questa analisi ha mostrato che i segnali più forti erano se il paziente avesse ricevuto chemioterapia o radioterapia dopo l’intervento, il numero di linfonodi coinvolti dal tumore, l’età, l’indice di massa corporea (BMI) e il conteggio preoperatorio dei neutrofili, un tipo di globulo bianco. I pazienti con maggiore interessamento linfonodale e segni di infiammazione sistemica tendevano ad avere un rischio previsto più elevato. Gli autori sottolineano che l’elevato contributo associato a chemioterapia e radioterapia non implica che questi trattamenti causino metastasi; piuttosto, sono marcatori del fatto che i medici avevano già valutato la malattia come più aggressiva, quindi questi pazienti partivano da un rischio maggiore.
Come questo potrebbe aiutare i pazienti nella pratica
Poiché il modello utilizza informazioni che la maggior parte dei centri oncologici registra già, potrebbe, dopo ulteriori verifiche, essere integrato nel software ospedaliero. Per un nuovo paziente appena operato al polmone, il sistema potrebbe raccogliere i suoi dati e fornire una probabilità personalizzata di metastasi a distanza, insieme a una spiegazione semplice dei fattori che aumentano o riducono il rischio. I clinici potrebbero così decidere chi necessita di un follow-up radiologico più ravvicinato, di supporto aggiuntivo o dell’arruolamento in studi clinici, e chi può evitare sorveglianze intensive. Lo studio è stato condotto in un unico ospedale, quindi lo strumento necessita ancora di essere verificato e perfezionato in altre aree geografiche e sistemi sanitari. Tuttavia offre un progetto promettente per combinare i dati clinici di routine con apprendimento automatico trasparente per migliorare la cura a lungo termine delle persone con cancro del polmone.
Citazione: Guo, X., Xu, T., Luo, Y. et al. Comparative study on predicting postoperative distant metastasis of lung cancer based on machine learning models. Sci Rep 16, 6468 (2026). https://doi.org/10.1038/s41598-026-37113-w
Parole chiave: cancro del polmone, metastasi a distanza, apprendimento automatico, predizione del rischio, follow-up postoperatorio