Clear Sky Science · it
Riepilogo temporale innovativo per la classificazione video complessa
Perché contano riepiloghi video più intelligenti
Dalle telecamere di sorveglianza alle piattaforme di streaming, il mondo sta registrando più video di quanto esseri umani o computer possano gestire comodamente. Ogni secondo di ripresa contiene decine di fotogrammi, e molti di questi sono praticamente identici. Questo articolo esplora un modo per comprimere video lunghi fino ai momenti più significativi, così che i computer possano riconoscere azioni come cucinare, praticare uno sport o portare a spasso un cane—usando molto meno tempo, memoria ed energia. Tali progressi potrebbero aiutare a portare analisi video potenti su dispositivi quotidiani, dai robot domestici alle videocamere indossabili.

Dai fotogrammi infiniti ai momenti chiave
I sistemi tradizionali di classificazione video cercano di riconoscere cosa accade in un clip—per esempio, tagliare le verdure o tirare a canestro—alimentando lunghe sequenze di fotogrammi in modelli di deep learning pesanti. Questi modelli devono trattare sia l’aspetto (come appaiono le cose) sia il tempo (come si muovono nel tempo). Processare tutti i fotogrammi porta a dataset di grandi dimensioni, elevati requisiti di storage e calcoli lenti e affamati di energia. Gli autori sostengono che molti di questi fotogrammi sono ridondanti: se non cambia nulla di rilevante da un fotogramma al successivo, il sistema ottiene poco analizzandoli entrambi. L’idea centrale dell’articolo è selezionare un insieme molto più piccolo di “fotogrammi chiave” che catturi comunque i cambiamenti importanti nella scena.
Misurare il cambiamento tra fotogrammi
Per trovare quei momenti chiave, i ricercatori progettano e confrontano diversi modi di misurare quanto un fotogramma differisca da un altro. Invece di fare affidamento solo sulla classica distanza euclidea, che confronta tutti i pixel in modo uniforme, provano alternative più sensibili ai cambiamenti strutturali. La loro proposta principale, chiamata distanza “Norma delle righe”, si concentra sulla maggiore differenza lungo ciascuna riga di pixel e poi prende la riga più pronunciata come misura del cambiamento tra due fotogrammi. Esplorano anche distanze basate sulle colonne e metodi fondati sugli autovalori di matrici che riassumono come le differenze tra pixel si distribuiscono. Tutti questi approcci mirano a rilevare meglio movimenti o cambi di scena significativi, come una mano che afferra un utensile o un giocatore che salta.
Come funziona la pipeline di riepilogo
Il processo di riepilogo inizia con il primissimo fotogramma di un video, trattato come fotogramma chiave iniziale. Il sistema quindi confronta questo fotogramma chiave con ciascun fotogramma successivo usando una delle misure di distanza. Ogni volta che la distanza supera una soglia scelta, il fotogramma corrispondente viene segnato come nuovo fotogramma chiave, indicando che è avvenuto un cambiamento visivo importante. La procedura si ripete quindi usando questo nuovo fotogramma chiave come riferimento, scorrendo il video e raccogliendo una catena di istantanee rappresentative. Regolando la soglia, il metodo può mantenere dal 20 percento fino all’80 percento dei fotogrammi originali, bilanciando compattezza e dettaglio. Queste sequenze sintetiche vengono poi passate a un classificatore standard di deep learning che combina una potente rete per immagini (ResNet-50) con un modulo sensibile al tempo LSTM.
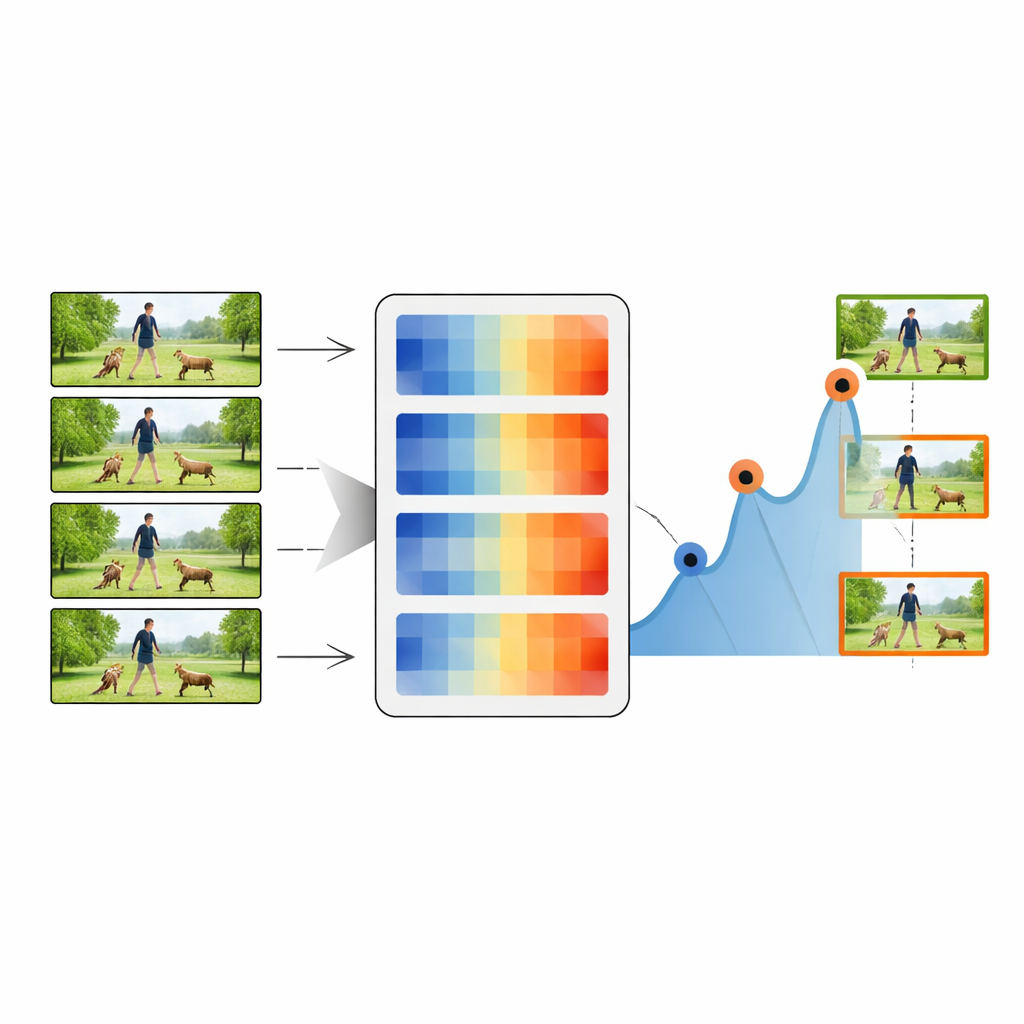
Mettere il metodo alla prova
Gli autori valutano rigorosamente il loro approccio su quattro collezioni video note: attività quotidiane in cucina (MMAC), sport e azioni generali (UCF101 e UCF11) e clip più vari e impegnativi (HMDB51). Su questi benchmark, la distanza Norma delle righe fornisce costantemente il miglior equilibrio tra velocità e accuratezza. Con solo circa la metà dei fotogrammi mantenuti, il loro sistema raggiunge accuratezze di classificazione superiori al 90 percento su diversi dataset—spesso uguagliando o superando metodi più complessi che usano video completi e non riassunti. Misurano inoltre quanto i riepiloghi coprano il contenuto originale, quanto siano ridondanti i fotogrammi selezionati e quanto diventino diversi i momenti catturati. La metrica proposta ottiene alta copertura con bassa ridondanza, il che significa che conserva la narrazione del video senza ripetere fotogrammi simili.
Decisioni più rapide per video nel mondo reale
Tagliando il numero di fotogrammi approssimativamente della metà, il metodo dimezza quasi i tempi di elaborazione su hardware standard e offre comunque accelerazioni evidenti anche su moderne schede grafiche. Per i sistemi reali che devono reagire in tempo reale—come sorveglianza, robot autonomi o app mobili—questa riduzione del carico di lavoro è cruciale. Lo studio mostra che una misura di distanza progettata con cura può funzionare come un guardiano intelligente, scegliendo quali fotogrammi meritano attenzione e quali possono essere saltati in sicurezza.
Conseguenza per l’uso quotidiano
In termini semplici, questo lavoro dimostra che i computer non devono guardare ogni singolo fotogramma per capire cosa sta succedendo in un video. Concentrandosi sui momenti in cui l’immagine cambia davvero e ignorando i quasi-duplicati, la tecnica proposta mantiene l’essenza di un’azione riducendo drasticamente la quantità di dati. Questo rende la comprensione video di alta qualità più pratica su hardware limitato e apre la strada a strumenti più veloci ed efficienti per analizzare il flusso crescente di informazioni visive nella nostra vita quotidiana.
Citazione: Khan, A., Rahnama, A., Islam, A. et al. Innovative temporal summarization for complex video classification. Sci Rep 16, 7970 (2026). https://doi.org/10.1038/s41598-026-37111-y
Parole chiave: classificazione video, riepilogo video, selezione dei fotogrammi chiave, riconoscimento delle azioni, efficienza della visione artificiale