Clear Sky Science · it
Costruzione e applicazione del grafo della conoscenza per i documenti sugli standard di qualità dei semi
Perché le regole sui semi contano per il cibo di tutti
Dietro ogni sacco di riso o bustina di semi di verdura c’è un intrico di norme tecniche che proteggono in modo discreto le rese delle colture e la sicurezza alimentare. Tuttavia, queste regole sulla qualità dei semi sono spesso sepolte in documenti PDF densi, difficili da cercare o interpretare per agricoltori, regolatori e aziende. Questo studio mostra come trasformare quei documenti statici in una “mappa” viva di fatti connessi — un grafo della conoscenza — possa rendere gli standard agricoli più trasparenti, ricercabili e pronti per l’era dell’agricoltura digitale. 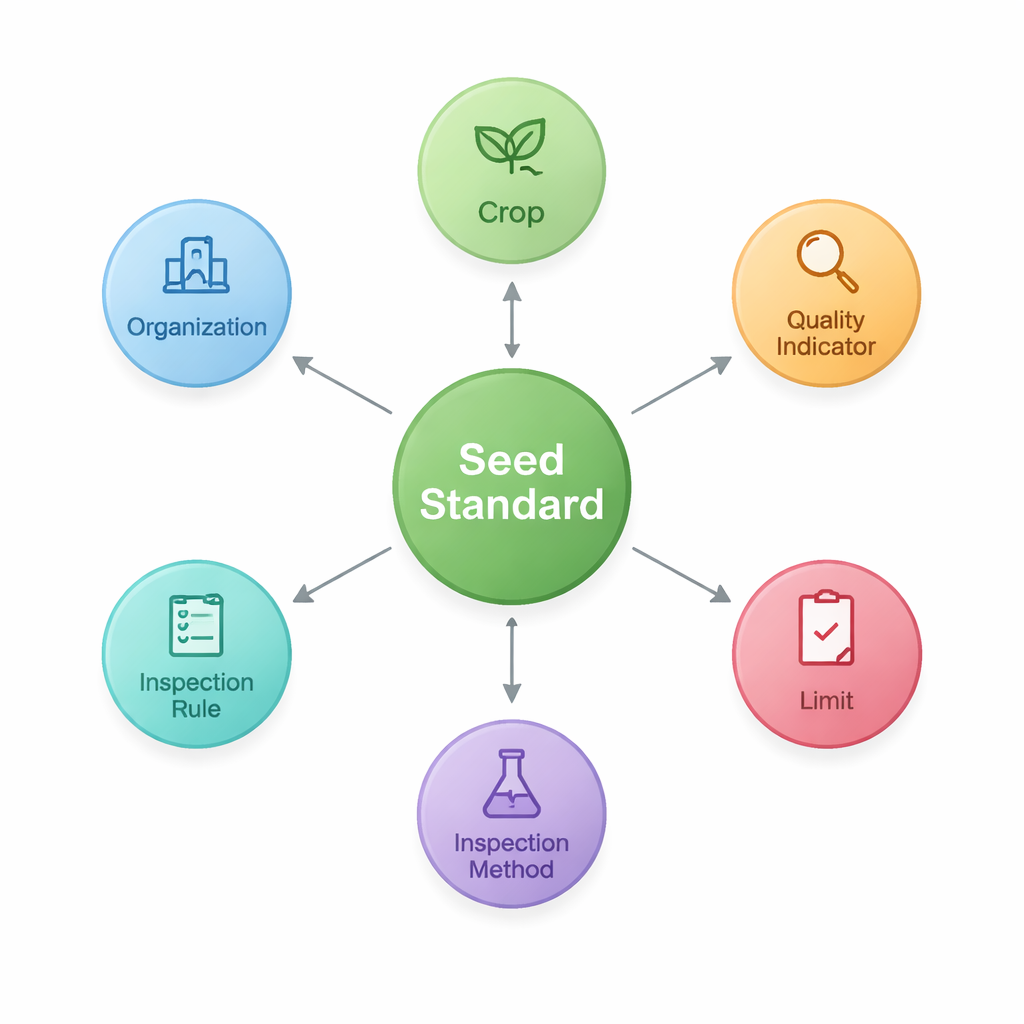
Dagli standard cartacei alle informazioni smart
Gli standard di qualità dei semi definiscono cosa costituisce un seme accettabile: quanto deve essere puro il lotto, quante sementi devono germinare, quanta umidità è ammessa e i metodi usati per testare questi caratteri. In Cina il numero di tali documenti è esploso e molti esistono ancora solo come pagine scannerizzate o testo non strutturato. Una semplice ricerca per parola chiave fatica a rispondere a domande pratiche come “Quali sono i limiti di purezza per questa coltura?” o “Quale norma ha sostituito una versione precedente?”. Gli autori sostengono che, per tenere il passo con i rapidi cambiamenti dell’agricoltura, questi standard debbano passare da pagine leggibili dall’uomo a conoscenza comprensibile dalle macchine, in grado di supportare interrogazioni rapide, confronti e controlli automatizzati.
Costruire una mappa della conoscenza sui semi
Per raggiungere questo obiettivo, i ricercatori progettano innanzitutto un’“ontologia” — un progetto condiviso che definisce i principali mattoni degli standard sui semi e come si collegano. Identificano sette tipi fondamentali di elementi, fra cui lo standard stesso, la coltura cui si applica, gli indicatori di qualità come purezza o tasso di germinazione, i limiti numerici per quegli indicatori, i metodi e le regole di ispezione e le organizzazioni che redigono o pubblicano i documenti. Questa struttura cattura schemi come “Coltura–Indicatore di qualità–Limite”, particolarmente importanti in ambito agricolo. Utilizzando questo progetto, memorizzano poi i fatti estratti come nodi e collegamenti in un database a grafo (Neo4j), creando una rete di 2.436 entità connesse da 3.011 relazioni.
Combinare regole e apprendimento automatico
La vera sfida è estrarre fatti puliti e affidabili da documenti sorgente disordinati. Gli standard sui semi mescolano tabelle ben formattate, metadati rigidi di frontespizio e lunghe clausole di testo libero. Nessuna tecnica singola gestisce tutto questo bene. Il team costruisce quindi un sistema di estrazione ibrido. Usa schemi di regole precisi (espressioni regolari) per leggere tabelle strutturate e informazioni di base del documento, che tendono a seguire formati rigidi. Per il testo narrativo più complesso — come le regole dettagliate di ispezione — addestrano una moderna pipeline basata su modelli linguistici chiamata BERT–BiLSTM–CRF per riconoscere nomi chiave, codici e termini tecnici. Questo modello impara da esempi accuratamente etichettati e può individuare entità anche quando compaiono con formulazioni diverse e in frasi lunghe. 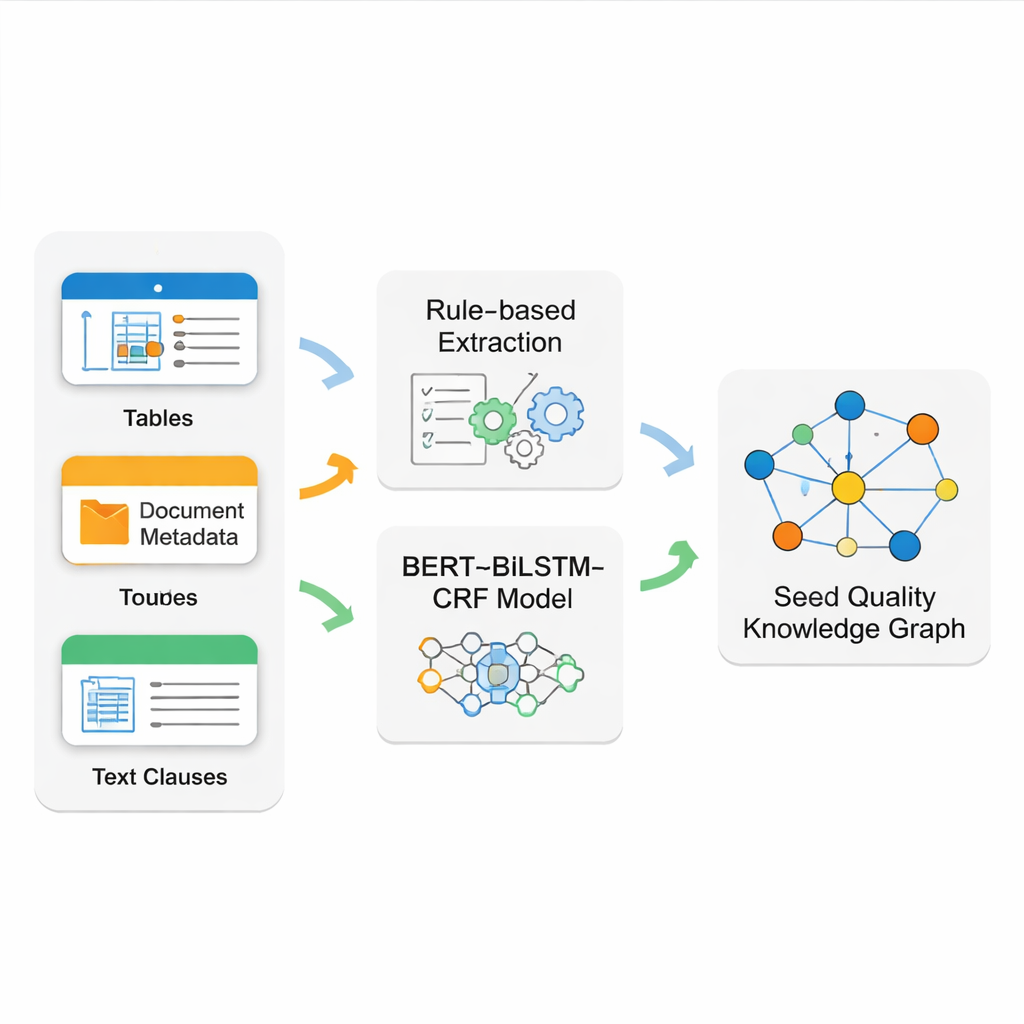
Quanto bene funziona il sistema nella pratica
Nei test l’approccio ibrido ottiene buone prestazioni. Il modello linguistico raggiunge un punteggio F1 complessivo (un equilibrio tra accuratezza e completezza) di circa il 91,6%, superando due modelli di riferimento comunemente usati. È particolarmente efficace nel trovare elementi strutturati come i codici degli standard e si comporta bene anche su compiti più difficili, come le lunghe regole di ispezione. Una volta che tutte queste informazioni sono caricate nel grafo della conoscenza, gli utenti possono esplorare visivamente come un dato standard si relazioni a versioni precedenti, quali organizzazioni lo hanno redatto, quali colture e indicatori copre e quali metodi di prova prescrive. Invece di sfogliare lunghi PDF, regolatori e aziende sementiere possono eseguire ricerche mirate e vedere risultati connessi in pochi secondi.
Cosa significa questo per agricoltori e sistemi alimentari
Per i non specialisti, il risultato è un modo più intelligente di gestire le regole che mantengono i semi affidabili e le colture produttive. Lo studio dimostra che combinando un progetto concettuale chiaro con estrazione basata sia su regole sia su apprendimento, è possibile trasformare standard sparsi sui semi in una base di conoscenza coerente e ricercabile. Questo pone le basi tecniche per standard “SMART” che i computer possono leggere, controllare incrociando i dati e aggiornare man mano che le normative cambiano. A lungo termine, tali strumenti potrebbero aiutare agricoltori e imprese agricole a verificare rapidamente se i semi soddisfano i requisiti di qualità vigenti, supportare i regolatori nel monitorare revisioni e lacune e contribuire a raccolti più stabili e alla sicurezza alimentare.
Citazione: Yang, Z., He, Q. & Zhang, J. Construction and application of knowledge graph for seed quality standard documents. Sci Rep 16, 5997 (2026). https://doi.org/10.1038/s41598-026-37084-y
Parole chiave: standard di qualità dei semi, grafo della conoscenza, digitalizzazione agricola, riconoscimento delle entità nominate, standard intelligenti