Clear Sky Science · it
Modello linguistico su base conoscitiva per la generazione di piani di allenamento sportivo personalizzati
Piani di allenamento più intelligenti per chiunque
La maggior parte delle app di fitness promette allenamenti personalizzati, ma molte si affidano ancora a modelli generici che ignorano lo stato reale del tuo corpo. Questo articolo presenta LLM-SPTRec, un nuovo sistema che utilizza lo stesso tipo di grandi modelli linguistici alla base dei chatbot moderni, combinati con conoscenze di scienze dello sport verificate e dati provenienti da dispositivi indossabili, per costruire piani di allenamento più sicuri ed efficaci. Per chi si è chiesto perché la propria app suggerisce continuamente esercizi sbagliati — o si è preoccupato sulla sicurezza dei consigli di salute generati dall’IA — questo lavoro mostra come rendere il coaching digitale sia più personale sia più scientifico.
Perché le app di fitness tradizionali non sono sufficienti
I motori di raccomandazione convenzionali, come quelli che suggeriscono film o prodotti, faticano quando applicati all’esercizio fisico. Spesso copiano e riutilizzano template standard, hanno difficoltà a gestire dati scarsi per utenti nuovi e raramente tengono conto di come il tuo corpo cambi giorno per giorno. Peggio ancora, non sono progettati per decisioni ad alto rischio dove la sicurezza conta. I modelli linguistici generici sono bravi a parlare di allenamenti, ma poiché sono addestrati su ampi testi del web, possono «allucinare» consigli rischiosi o trascurare giorni di riposo importanti. Gli autori sostengono che per la pianificazione dell’esercizio — dove una guida inadeguata può causare infortuni o sovrallenamento — l’IA deve essere ancorata a scienze dello sport verificate e deve monitorare lo stato di salute della persona nel tempo.
Costruire un ritratto ricco dell’individuo
Al centro di LLM-SPTRec c’è un modulo che crea un’istantanea dettagliata di ogni utente. Invece di memorizzare solo età, sesso o livello di esperienza, il sistema fonde tre tipi di informazioni: caratteristiche statiche (come la storia di allenamento), segnali dinamici (come frequenza cardiaca, variabilità della frequenza cardiaca, punteggio del sonno e allenamenti precedenti da dispositivi indossabili e registri) e obiettivi in testo libero scritti dall’utente. Un modello basato su transformer — correlato alla tecnologia dietro i moderni modelli linguistici — apprende i pattern in questi dati temporali, per esempio come un allenamento intenso di ieri possa influenzare la prontezza di oggi. Un meccanismo di attenzione valuta quindi quali segnali contano di più in un dato momento, combinandoli in una singola rappresentazione numerica dello stato attuale dell’utente.
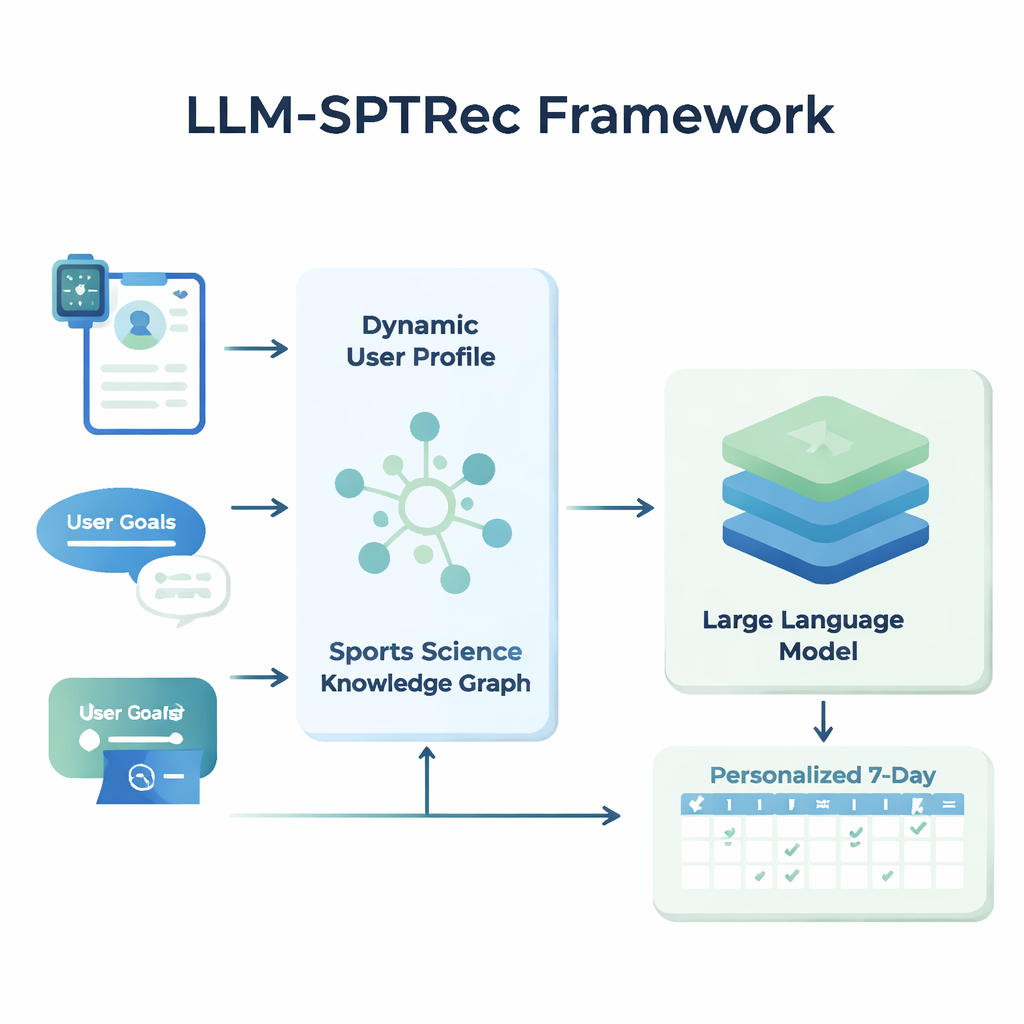
Insegnare alla IA la vera scienza dello sport
Per prevenire raccomandazioni non sicure o non scientifiche, i ricercatori hanno costruito un Sports Science Knowledge Graph, essenzialmente una mappa strutturata di fatti approvati da esperti. Include migliaia di voci che collegano esercizi a muscoli, tipi di movimento, attrezzatura, infortuni comuni e principi di allenamento come il sovraccarico progressivo e la specificità. Per ogni utente, il sistema estrae le parti più pertinenti di questo grafo — per esempio quali muscoli coinvolge la panca piana e quali movimenti sono controindicati per problemi alla spalla — e le trasforma in testo leggibile che viene fornito al modello linguistico insieme al profilo utente. Al modello viene quindi richiesto, tramite un prompt accuratamente progettato, di generare un piano di allenamento multi-giorno in un formato strutturato, rispettando regole come la rotazione dei gruppi muscolari tra i giorni ed evitando controindicazioni note.
Mantenere i piani strutturati, sicuri e in miglioramento nel tempo
LLM-SPTRec fa più che generare testo. Un modulo di validazione verifica ogni piano rispetto a regole rigide, come non sovraccaricare gli stessi gruppi muscolari primari in giorni consecutivi, e segnala conflitti con i rischi di infortunio memorizzati nel grafo della conoscenza. Se un piano non supera questi controlli, il sistema richiede nuovamente al modello di produrre una soluzione, indicando esplicitamente cosa non andava, finché non viene ottenuto un piano sicuro. L’addestramento del sistema avviene inoltre in due fasi. Prima impara da una vasta raccolta di piani progettati da esperti. Poi viene ulteriormente raffinato usando feedback, dove valutazioni simulate o reali degli utenti premiano i piani coerenti, allineati con gli obiettivi e soddisfacenti da seguire, penalizzando fortemente suggerimenti non sicuri. Questo ciclo di feedback spinge il modello verso raccomandazioni che funzionano meglio nella pratica.
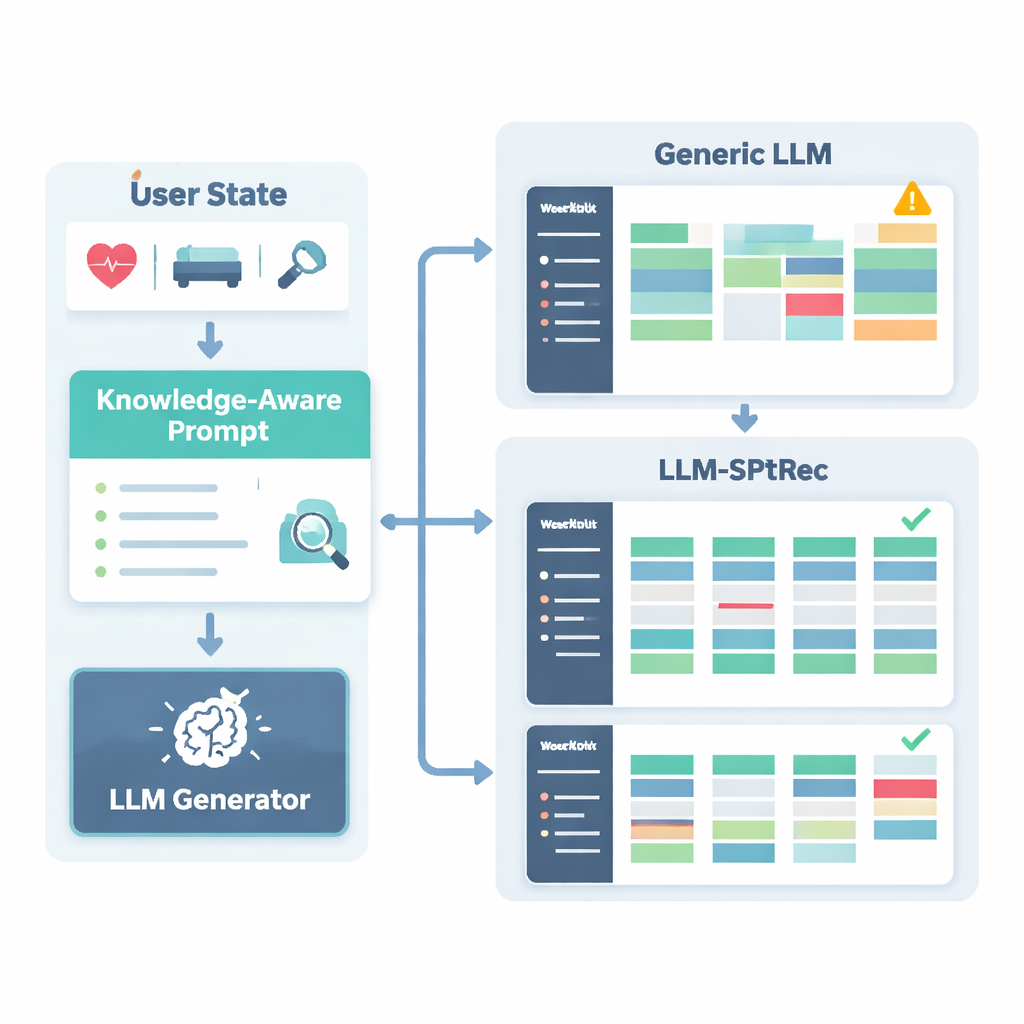
Quanto bene il sistema funziona nella pratica
Gli autori hanno testato LLM-SPTRec su un ampio dataset reale chiamato SportFit-1M, che combina dati anonimizzati di app di fitness e dispositivi indossabili, coprendo decine di migliaia di utenti e milioni di registrazioni di allenamento e dati fisiologici. Hanno confrontato il loro sistema con baseline robuste: il classico collaborative filtering, un modello sequenziale che considera solo le scelte passate, un raccomandatore basato su grafo della conoscenza all’avanguardia e un framework basato su modelli linguistici di uso generale. LLM-SPTRec ha superato tutti non solo nella selezione di esercizi appropriati, ma — cosa più importante — nella produzione di piani completi che gli esperti hanno giudicato più coerenti e più allineati con gli obiettivi degli utenti. Anche i punteggi di soddisfazione utente predetti sono stati più alti, e un piccolo studio umano con trainer certificati ha valutato la sua sicurezza molto meglio rispetto a un modello linguistico generale privo di un’ancora specifica allo sport.
Cosa significa questo per il coaching digitale futuro
Per un lettore non esperto, la conclusione è che un coaching AI più intelligente e più sicuro è possibile quando si combinano tre ingredienti: dati ricchi dai tuoi dispositivi, scienze dello sport esperte codificate come conoscenza strutturata e potenti modelli linguistici la cui creatività è guidata e verificata con cura. LLM-SPTRec dimostra che una tale combinazione può generare piani di allenamento adattivi, giorno per giorno, che rispettano lo stato in evoluzione del tuo corpo e i tuoi obiettivi personali, riducendo al contempo il rischio di consigli dannosi o insensati. Guardando avanti, la stessa ricetta potrebbe estendersi oltre l’allenamento a nutrizione, riabilitazione degli infortuni o anche benessere mentale, indicando un futuro in cui gli assistenti IA si comportano meno come chatbot generici e più come coach digitali esperti e attenti alla sicurezza.
Citazione: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
Parole chiave: allenamento personalizzato, IA e scienze dello sport, raccomandazioni fitness, dati da dispositivi indossabili, grafo della conoscenza