Clear Sky Science · it
L’evoluzione del rilevamento degli oggetti da CNN a transformer e alla fusione multi-modale
Insegnare ai computer a vedere gli oggetti di tutti i giorni
Ogni volta che il tuo telefono tagga amici in una foto, un’auto individua un pedone o lo strumento di un medico evidenzia un tumore in una scansione, entra in gioco una tecnologia sorprendentemente potente: il rilevamento degli oggetti. Questo articolo di sintesi spiega come il rilevamento degli oggetti sia rapidamente evoluto nell’ultimo decennio, dai primi stratagemmi di elaborazione delle immagini fino ai sistemi odierni basati sui transformer e sui sensori multipli, e perché questi progressi contano per strade più sicure, robot più intelligenti e diagnosi mediche più accurate.
Dai pixel alle cose riconoscibili
Il rilevamento degli oggetti è il compito di trovare e etichettare elementi specifici in immagini o video—automobili, ciclisti, animali, strutture mediche e altro. L’articolo inizia tracciando quanto sia diffuso questo capability: guida autonoma, videosorveglianza, imaging medico e robotica. I primi sistemi si basavano su regole progettate a mano per individuare forme e texture, mentre gli approcci moderni imparano direttamente dai dati usando l’apprendimento profondo. Oggi dominano due grandi famiglie: le reti neurali convoluzionali (CNN), molto abili a riconoscere pattern locali come bordi e angoli, e i transformer, eccellenti nel cogliere la scena più ampia e le relazioni tra oggetti distanti. Insieme definiscono come le macchine “vedono” il mondo attuale.
Come funzionano i motori classici di visione
I metodi basati su CNN alimentano ancora molte applicazioni in tempo reale. Scansionano le immagini con piccoli filtri per costruire mappe di caratteristiche sempre più ricche, quindi le inviano a teste di rilevamento che tracciano riquadri di delimitazione e assegnano etichette. La survey illustra due strategie principali. I sistemi a due stadi come Faster R-CNN propongono prima regioni probabili di oggetto e poi le raffinano, ottenendo spesso alta accuratezza a costo computazionale maggiore. I sistemi a stadio unico come la famiglia YOLO saltano il passo di proposta e predicono riquadri ed etichette in un unico passaggio, scambiando un po’ di accuratezza per velocità. Le versioni recenti di YOLOv5 e YOLOv8 sono state pesantemente ottimizzate—aggiungendo piramidi di caratteristiche più intelligenti per oggetti piccoli, blocchi leggeri per dispositivi edge e funzioni di perdita migliorate—per raggiungere centinaia di frame al secondo restando competitive sui benchmark più impegnativi.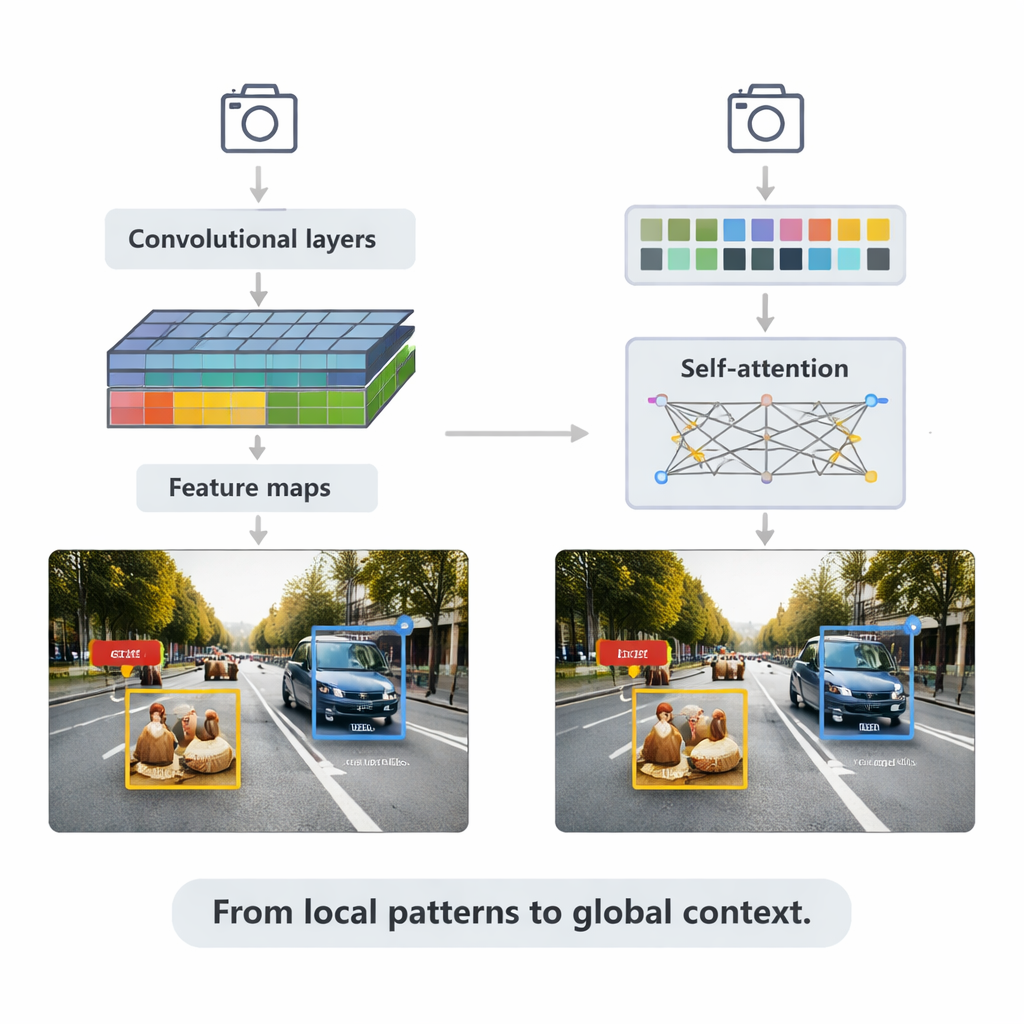
Transformer e il potere del contesto
L’articolo passa poi ai transformer, un’architettura più recente presa in prestito dai modelli linguistici. Invece di concentrarsi solo sui vicini locali, i transformer usano la “self-attention” per confrontare ogni patch dell’immagine con tutte le altre, imparando quali regioni sono più rilevanti per ogni decisione. Detection Transformer (DETR) e i suoi successori eliminano molti trucchi progettati a mano, puntando a pipeline più pulite e end-to-end. Varianti come Deformable DETR e RT-DETR riducono il carico computazionale e migliorano la velocità di addestramento, permettendo ai transformer di funzionare in tempo reale pur raggiungendo alcuni dei punteggi di accuratezza più alti sul diffuso benchmark COCO. Questi modelli eccellono in scene complesse con oggetti sovrapposti e sfondi confusi, dove il contesto globale aiuta a distinguere, per esempio, un pedone parzialmente nascosto dietro un’auto.
Mischiare fotocamere, laser e linguaggio
Condizioni reali—nebbia, oscurità, abbagliamento, ingombro—spesso mettono in difficoltà i sistemi a sensore singolo. Un focus importante della survey è la fusione multi-modale: combinare dati da fotocamere tradizionali (RGB), sensori di profondità come LiDAR, camere termiche e persino descrizioni testuali. Gli autori introducono una tassonomia chiara per come avviene questa integrazione: la fusione precoce mescola i dati grezzi all’inizio, la fusione intermedia unisce caratteristiche apprese all’interno della rete e la fusione tardiva combina le uscite di rilevatori separati alla fine. I moderni “fusion transformer” usano meccanismi di attenzione per allineare questi flussi, così che misurazioni di distanza precise da LiDAR, l’aspetto ricco dalle immagini RGB e gli indizi semantici dal linguaggio si rinforzino a vicenda. Questo approccio migliora il rilevamento nella guida autonoma, nell’imaging medico, nella comprensione video e nelle scene ricche di testo.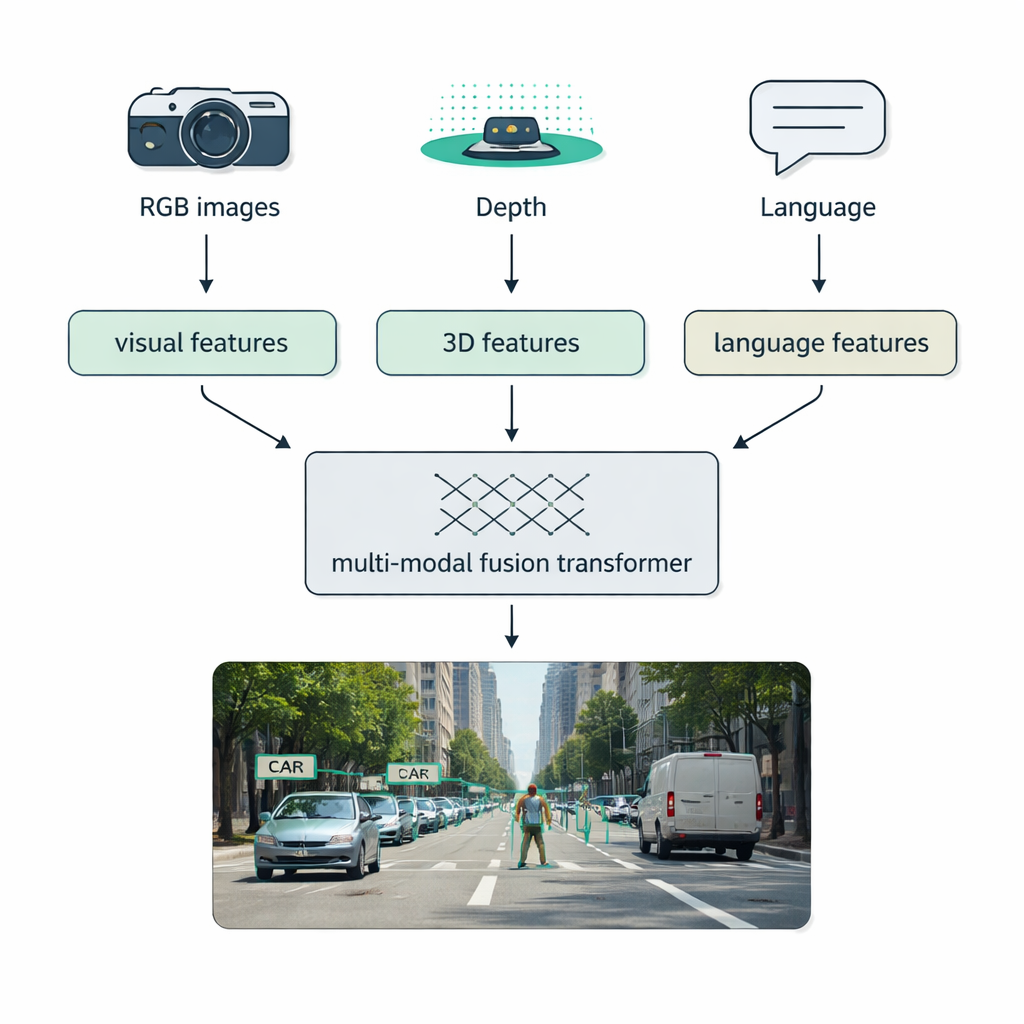
Benchmark, limiti e cosa verrà dopo
Su test standard come MS COCO, la survey confronta rilevatori CNN e transformer sia per accuratezza sia per velocità. Le CNN classiche a due stadi restano robuste ma più lente, i modelli in stile YOLO dominano sull’hardware leggero e i sistemi basati su transformer ora guidano per accuratezza mentre colmano il divario di velocità. Metodi specializzati a infrarossi raggiungono punteggi molto alti in condizioni di scarsa visibilità. Restano però problemi difficili: oggetti molto piccoli o estremamente grandi, forti occlusioni, condizioni meteo e di illuminazione variabili e la necessità di funzionare in modo affidabile su dispositivi minuscoli. Guardando avanti, gli autori evidenziano tendenze verso modelli di percezione unificati che gestiscono rilevamento, segmentazione e captioning insieme, e “foundation model” che fondono visione e linguaggio per riconoscere oggetti descritti in linguaggio naturale, anche se non etichettati nei dati di addestramento.
Perché questo conta nella vita quotidiana
Per i non specialisti, il messaggio chiave è che il rilevamento degli oggetti sta passando da sistemi ristretti e tarati a mano verso motori di visione flessibili e d’uso generale che possono adattarsi a nuovi compiti, ambienti e sensori. Le CNN offrono riconoscimento di pattern veloce ed efficiente; i transformer aggiungono una comprensione più globale e attenta al contesto; e la fusione multi-modale integra indizi aggiuntivi da profondità, temperatura e linguaggio. Insieme, questi progressi promettono auto che anticipano meglio i pericoli, strumenti che aiutano i medici con maggiore fiducia e dispositivi domestici che interagiscono in modo più sicuro e intelligente con l’ambiente—avvicinando la percezione delle macchine alla ricchezza della vista umana.
Citazione: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
Parole chiave: rilevamento oggetti, visione artificiale, apprendimento profondo, modelli transformer, fusione multi-modale