Clear Sky Science · it
Accertamento dello stato funzionale della mobilità nelle cartelle cliniche elettroniche utilizzando grandi modelli linguistici
Perché la capacità di camminare è un segnale di salute così importante
Con l’aumento dell’aspettativa di vita, i medici si interrogano sempre più non solo sulla durata della vita, ma anche sulla qualità del movimento: quanto bene riusciamo a muoverci, camminare e occuparci di noi stessi. Difficoltà a alzarsi da una sedia, salire le scale o spostarsi in città spesso compaiono molto prima di una crisi medica. Tuttavia, le descrizioni più dettagliate delle capacità quotidiane di una persona sono di solito sepolte nei testi liberi delle note di medici e terapisti nelle cartelle cliniche elettroniche, dove è difficile per i computer individuarle. Questo studio indaga se i moderni grandi modelli linguistici — lo stesso tipo di IA alla base di molti chatbot — possono leggere in modo affidabile quelle note e trasformare le descrizioni del movimento in informazioni strutturate e ricercabili.
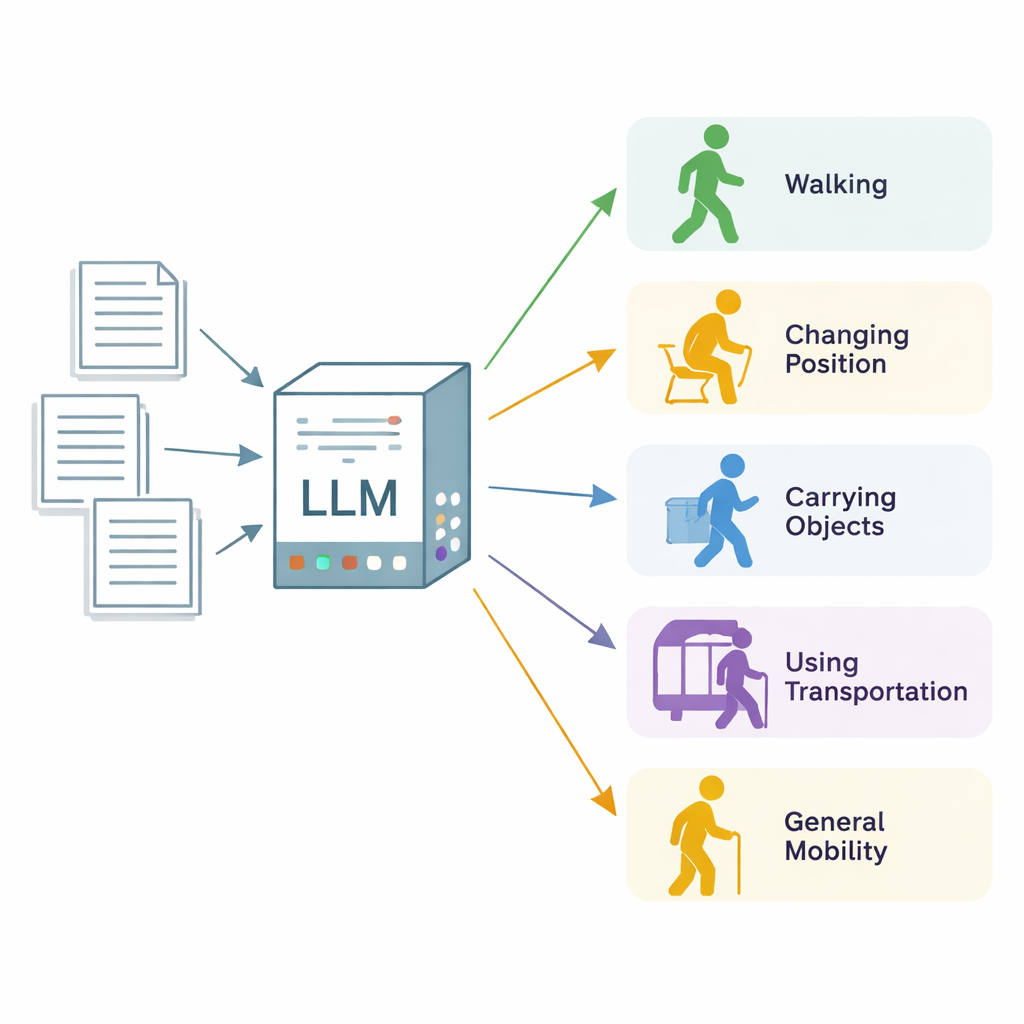
Trasformare note disordinate in dati sulla mobilità utilizzabili
I ricercatori si sono concentrati sullo “stato funzionale della mobilità”, un termine ampio per indicare quanto bene una persona cambia posizione corporea, cammina, porta e maneggia oggetti, usa i mezzi di trasporto e si muove nella vita quotidiana. Hanno utilizzato 600 note cliniche reali provenienti da tre strutture sanitarie nel Minnesota e nel Wisconsin, per lo più da visite di terapia fisica e occupazionale, oltre a un insieme di note di clinica generale. Annotatori esperti hanno esaminato ogni nota, sezione per sezione, e hanno etichettato ogni passaggio che descriveva una delle cinque categorie di mobilità, segnando se il paziente era chiaramente limitato (“compromesso”) o funzionante normalmente (“non compromesso”). Queste etichette esperte hanno fatto da standard d’oro per valutare il sistema di IA.
Come il modello di IA è stato addestrato a leggere come un clinico
Il team ha utilizzato Llama 3, un grande modello linguistico open source, eseguendolo su server locali sicuri in modo che i dati dei pazienti non lasciassero mai il sistema sanitario. Invece di riaddestrare il modello da zero, hanno progettato con cura dei prompt — insieme di istruzioni scritte e definizioni — per insegnare al modello cosa cercare. Hanno provato prompt “zero‑shot”, che forniscono solo istruzioni, e prompt “few‑shot”, che includono anche alcuni esempi di note. Hanno quindi analizzato dove il modello sbagliava e hanno elaborato un prompt “informato dagli errori” che spiegava cosa includere, cosa ignorare (come i piani di trattamento futuri) e come gestire casi complessi come cadute, vertigini o l’uso della sedia a rotelle. All’IA è stato chiesto, per ogni sezione di nota e per ciascuna categoria di mobilità, se la mobilità fosse menzionata e, in tal caso, se il paziente fosse compromesso.
Ottima performance che migliora a livello di paziente
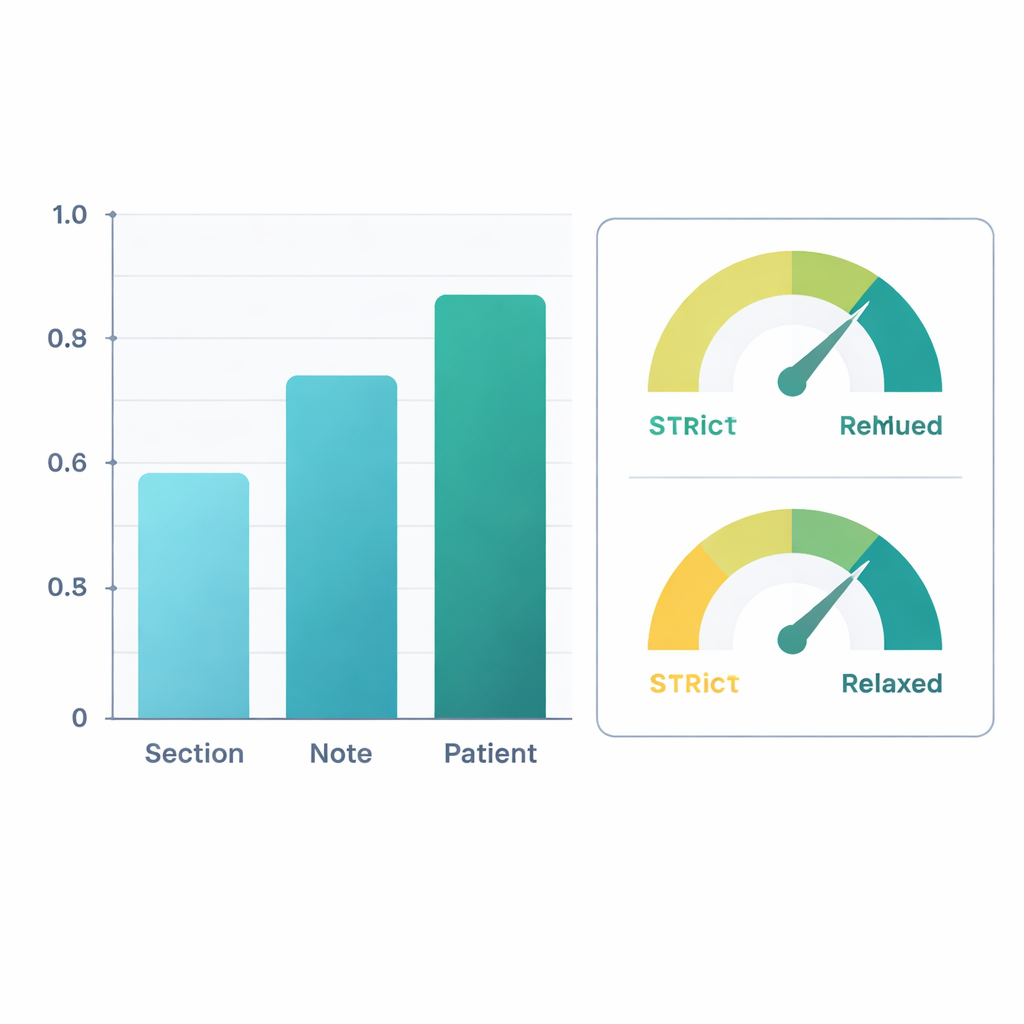
Rispetto alle etichette degli esperti, il sistema raffinato ha ottenuto buoni risultati. A livello del paziente nel suo complesso — combinando le informazioni presenti in tutte le sue note — l’IA ha raggiunto un punteggio F1 (una comune misura di accuratezza) di circa 0,88 per l’individuazione delle informazioni sulla mobilità e di 0,90 per la determinazione se la persona fosse compromessa. Ciò significa che i suoi giudizi corrispondevano da vicino a quelli dei revisori umani. Le prestazioni erano leggermente inferiori quando si analizzavano singole sezioni di nota, dove il linguaggio può essere scarno o ambiguo, ma l’accuratezza migliorava man mano che le informazioni venivano aggregate attraverso l’intera nota e poi attraverso tutte le note di un paziente. In un’analisi secondaria, i ricercatori hanno considerato corrette anche le “inferenze clinicamente ragionevoli” — per esempio, assumere che un forte dolore al ginocchio durante la deambulazione probabilmente limiti il cammino, anche se ciò non fosse esplicitato. Sotto questa visione più permissiva, i punteggi F1 a livello di paziente sono saliti oltre 0,96 per l’estrazione e 0,95 per la classificazione della compromissione.
Cosa ha sbagliato l’IA — e perché questo è comunque importante
La maggior parte degli errori derivava dall’interpretazione implicita del modello. Spesso inferiva problemi di mobilità sulla base di dolore, vertigini o piani terapeutici futuri, anche quando la nota non affermava chiaramente che il paziente fosse limitato. Altri errori riflettevano zone grigie nelle definizioni, come stabilire se le cadute ripetute debbano essere trattate come un problema di deambulazione o come un problema di equilibrio nel cambiare posizione. La categoria chiamata “mobilità, non specificata”, pensata per catturare attività quotidiane ed esercizio, è risultata particolarmente difficile da definire. Nonostante questi problemi, gli errori erano generalmente sensati dal punto di vista clinico piuttosto che casuali o bizzarri. Eseguendo il modello in modo deterministico (senza casualità incorporata) su server locali chiusi, il team ha inoltre garantito che i risultati fossero riproducibili e che la privacy dei pazienti fosse preservata.
Come questo potrebbe cambiare la cura degli anziani
Per un lettore non specialista, la conclusione è che un sistema di IA può ora leggere le note di routine di medici e terapisti abbastanza bene da riassumere quanto i pazienti si muovono e dove incontrano difficoltà. Ciò significa che le strutture sanitarie potrebbero monitorare i cambiamenti nella deambulazione, nell’equilibrio e nelle attività quotidiane nel tempo senza aggiungere nuovi questionari o test, individuare le persone ad alto rischio di cadute o di ricoveri ospedalieri e identificare chi potrebbe beneficiare di terapia fisica o valutazioni di sicurezza domestica. Convertendo milioni di note in testo libero in dati strutturati sulla mobilità, questo approccio aiuta i medici a vedere il quadro più ampio di come l’invecchiamento e le malattie influenzano la vita di tutti i giorni — portando l’assistenza sanitaria un passo più vicino a una medicina veramente personalizzata e incentrata sulla funzione.
Citazione: Liu, X., Garg, M., Jia, H. et al. Mobility functional status ascertainment in electronic health records using large language models. Sci Rep 16, 6045 (2026). https://doi.org/10.1038/s41598-026-37025-9
Parole chiave: mobilità, cartelle cliniche elettroniche, grandi modelli linguistici, stato funzionale, IA clinica