Clear Sky Science · it
Un benchmark per valutare l’efficienza delle domande diagnostiche degli LLM nelle conversazioni con i pazienti
Perché contano domande mediche più intelligenti
Quando vai dal medico, la prima diagnosi che ascolti raramente deriva da un singolo sintomo che hai menzionato. I medici fanno invece una serie di domande di approfondimento — sul momento di insorgenza, sull’intensità, su problemi correlati — per restringere gradualmente cosa potrebbe esserci. Per potenti che siano i sistemi di IA odierni, la maggior parte viene ancora testata come se sostenesse un esame a scelta multipla, non come se stesse parlando con persone reali. Questo articolo presenta Q4Dx, un nuovo modo per giudicare quanto bene i grandi modelli linguistici (LLM) possono interpretare il ruolo del “medico curioso”: scegliere le domande giuste, nell’ordine giusto, per arrivare a una diagnosi corretta in modo efficiente.
Dalle domande d’esame alle conversazioni reali
La maggior parte dei test di IA medica esistenti fornisce ai modelli casi ordinati e completamente specificati — come un problema di manuale — e chiede di scegliere una diagnosi. Questo mostra cosa il sistema “sa”, ma non come si comporterebbe in una conversazione disordinata e reale con un paziente che dimentica dettagli o descrive i sintomi in linguaggio quotidiano. Gli autori sostengono che questo sia un punto cieco significativo. Nelle cliniche, le informazioni emergono lentamente e spesso in modo impreciso; l’abilità di un buon clinico sta tanto in ciò che chiede quanto in ciò che già conosce. Q4Dx è progettato per colmare questa lacuna spostando l’attenzione dalla risposta a domande statiche alla strategia di porre domande nel tempo.
Costruire storie di pazienti verosimili
Per creare questo nuovo banco di prova, i ricercatori partono da una risorsa medica curata che collega specifiche malattie a insiemi caratteristici di sintomi. Selezionano casualmente 100 coppie malattia–sintomi e poi usano un modello di IA per trasformare liste sterili di sintomi in descrizioni del paziente dal tono naturale — storie che una persona potrebbe effettivamente raccontare in una clinica. Da ogni caso completo generano versioni più brevi in cui vengono citati solo circa l’80% o il 50% dei sintomi chiave. Questo “nascondere” controllato delle informazioni consente di studiare come diversi modelli si adattino quando indizi importanti mancano o sono solo accennati. Verifiche sulla sovrapposizione dei sintomi confermano che le versioni più brevi contengono realmente meno informazioni utili, non soltanto meno parole.
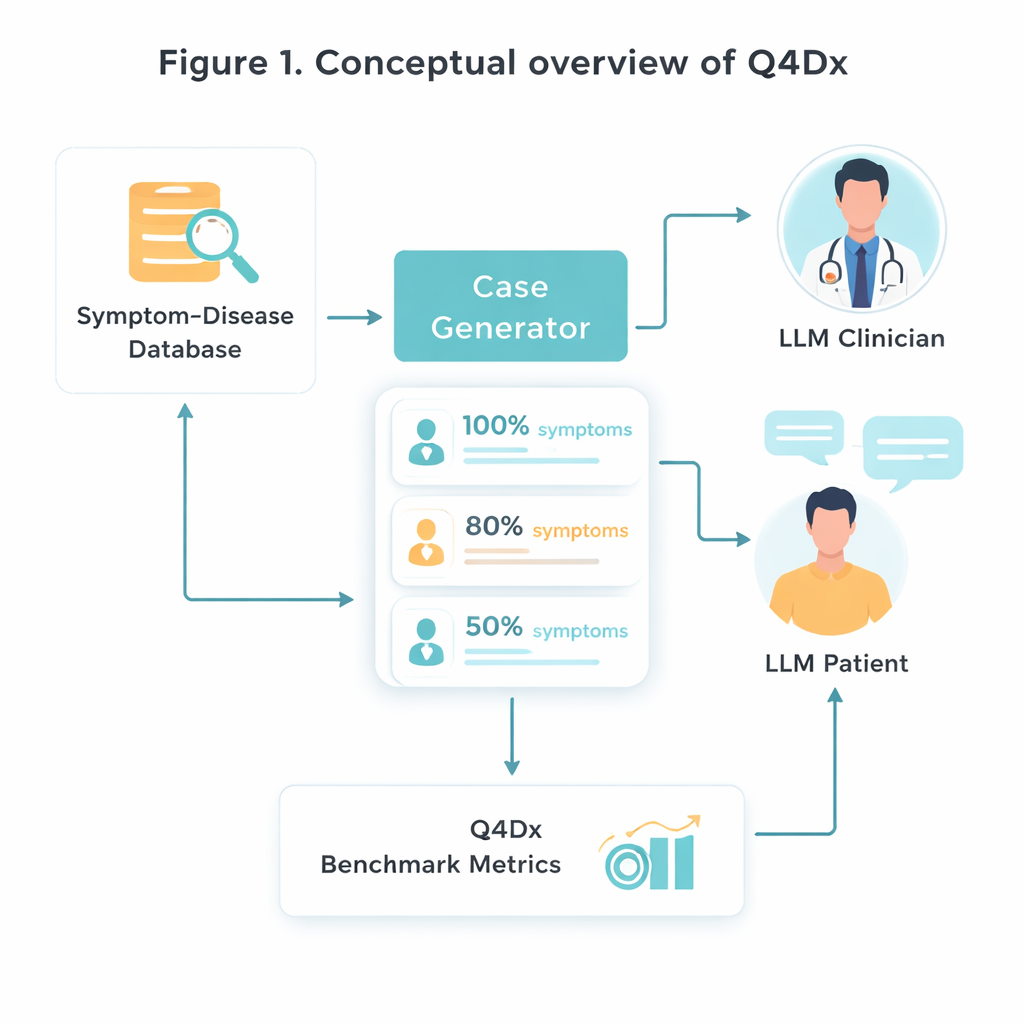
Dialoghi simulati medico–paziente
Il cuore di Q4Dx è una grande raccolta di conversazioni simulate tra due agenti di IA. Uno interpreta il ruolo del paziente, con pieno accesso alla malattia sottostante e al suo insieme completo di sintomi. L’altro funge da medico: vede solo una descrizione parziale, possibilmente vaga, all’inizio e deve decidere cosa chiedere dopo. Dopo ogni risposta del paziente, l’agente medico formula una diagnosi provvisoria, creando una traccia passo dopo passo di come evolve il suo ragionamento. Registrando tutte le domande, le risposte e i tentativi intermedi, il benchmark cattura non solo se il modello ha ragione, ma come ci arriva. Queste sequenze di domande generate dall’IA vengono usate come strategie di riferimento — non come verità medica perfetta, ma come metro coerente rispetto al quale confrontare modelli futuri e persino tirocinanti umani.
Misurare buone domande, non solo risposte giuste
Per valutare le prestazioni, gli autori progettano tre misure semplici ma complementari. L’Accuratezza Diagnostica Zero‑Shot (ZDA) chiede: se fornisci al modello il caso completo in anticipo, riesce a nominare immediatamente la malattia corretta? Il Numero Medio di Domande per la Diagnosi Corretta (MQD) riflette l’efficienza: in media, quante domande al paziente serve che il modello ponga prima di arrivare per la prima volta alla diagnosi giusta, con un limite massimo di cinque? Infine, l’Efficienza della Sequenza di Interrogazione (ISE) valuta la qualità del percorso di domande in sé — quanto sono simili, nel significato, le domande scelte dal modello rispetto alla sequenza di riferimento. Usando queste metriche, il team mostra che un modello generale potente (GPT‑4.1) diagnostica correttamente circa la metà delle volte con informazioni complete, ma la sua accuratezza scende quando i sintomi sono nascosti. Allo stesso tempo, le sue sessioni interattive di solito riescono dopo poche domande ben scelte, e le sue domande diventano più allineate a strategie di tipo esperto nei turni successivi.

Cosa significa questo per la futura IA medica
Per i non specialisti, il messaggio di questo lavoro è chiaro: in medicina, porre domande intelligenti è importante quanto avere le risposte giuste, e l’IA va valutata su entrambi gli aspetti. Q4Dx offre un quadro riutilizzabile e pubblicamente disponibile per fare esattamente questo. Fornendo storie di pazienti realistiche con quantità variabili di informazioni mancanti, tracce dettagliate delle conversazioni e misure chiare di accuratezza ed efficienza, il benchmark permette ai ricercatori di confrontare diversi sistemi di IA e persino metterli alla prova contro clinici umani in condizioni controllate. Nel tempo, strumenti come Q4Dx potrebbero aiutare a formare assistenti clinici più sicuri e affidabili e migliorare il modo in cui medici e studenti apprendono l’intervista diagnostica — sostenendo in ultima analisi cure migliori per i pazienti reali.
Citazione: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
Parole chiave: intelligenza artificiale medica, ragionamento diagnostico, dialogo clinico, modelli linguistici di grandi dimensioni, strategia di interrogazione