Clear Sky Science · it
MQADet: un paradigma plug-and-play per migliorare il rilevamento di oggetti a vocabolario aperto tramite question answering multimodale
Perché contano rilevatori di oggetti più intelligenti
Smartphone, automobili, robot domestici e motori di ricerca fanno sempre più affidamento su software in grado di trovare oggetti nelle immagini: un bambino che attraversa la strada, le chiavi smarrite su un tavolo o un prodotto specifico su uno scaffale. Ma la maggior parte dei sistemi attuali comprende solo etichette brevi e semplici come “cane” o “auto”. Se chiedi “il piccolo cane con il collare rosso sdraiato dietro il cuscino del divano”, spesso si confondono. Questo articolo presenta MQADet, un metodo per aggiornare i sistemi di ricerca di oggetti esistenti in modo che possano comprendere descrizioni ricche e dettagliate senza riaddestrare i modelli di base.
Da elenchi fissi a comprensione aperta
I rivelatori di oggetti tradizionali vengono addestrati su elenchi fissi di categorie, come le 80 voci di uso quotidiano nel diffuso dataset COCO. Funzionano bene finché l’oggetto appartiene a una di quelle categorie e la richiesta è breve e chiara. Tuttavia il mondo reale è disordinato. Le persone si riferiscono alle cose usando frasi lunghe, attributi sottili e relazioni come “l’uomo con il giubbotto giallo in piedi dietro il camion”. I più recenti rivelatori “a vocabolario aperto” cercano di liberarsi degli elenchi fissi collegando immagini e testo, ma faticano ancora con formulazioni complesse e con categorie rare a “coda lunga” che compaiono poco nei dati di addestramento. Inoltre richiedono molta potenza di calcolo e dati per migliorare.
Lasciare che i modelli linguistici guidino la ricerca
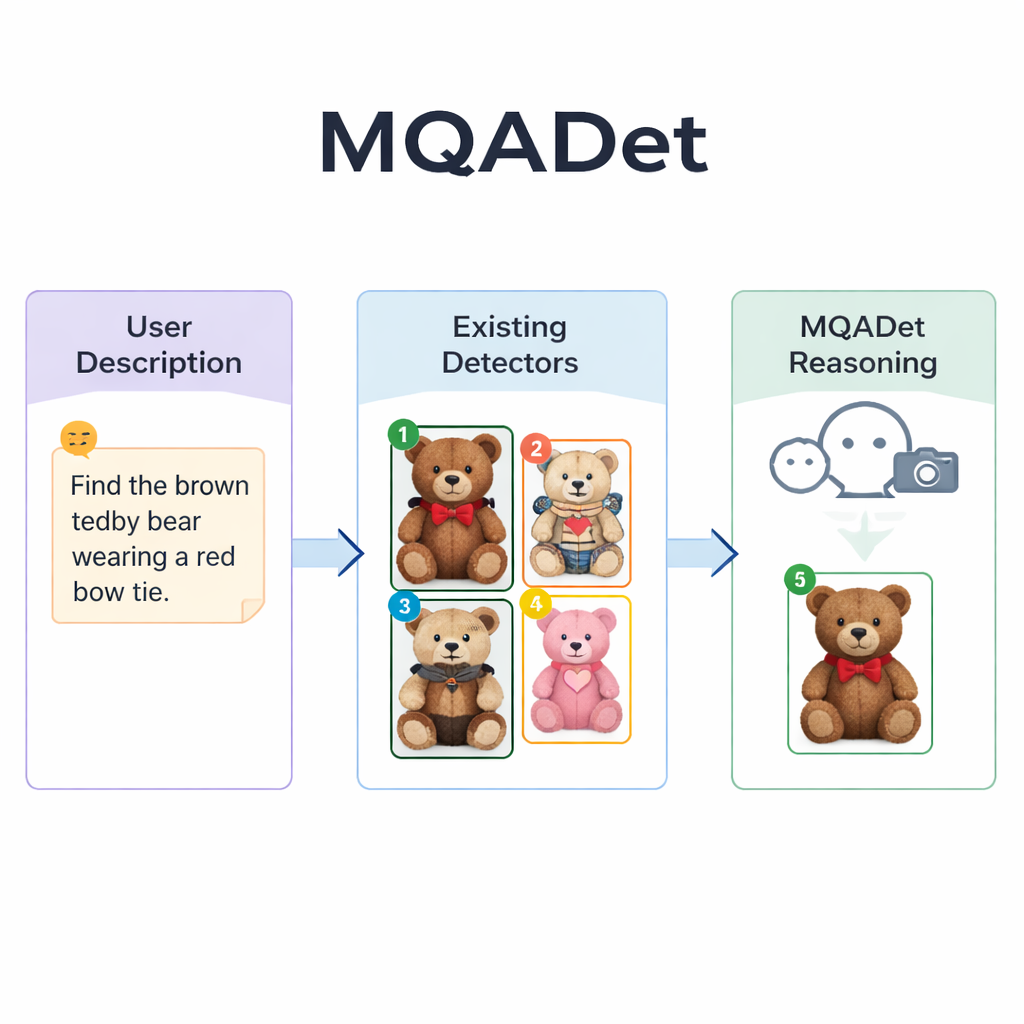
MQADet affronta questi problemi piazzando un modello linguistico multimodale — un sistema che può guardare immagini e leggere testo — sopra i rivelatori esistenti in un processo di question answering in tre fasi. Prima, una fase chiamata Text‑Aware Subject Extraction legge l’intera frase dell’utente ed estrae i veri target, come “ombrello” e “pedone” da una descrizione lunga. Questo rispecchia come una persona individua rapidamente i nomi principali in una frase prima di scandagliare la scena. Crucialmente, questa fase sfrutta la solida comprensione del linguaggio naturale del modello, perciò può gestire frasi descrittive lunghe invece di limitarsi a singole parole.
Segnare gli oggetti candidati nell’immagine
Nella seconda fase, Text‑Guided Multimodal Object Positioning, MQADet passa quei soggetti estratti insieme all’immagine a un rivelatore open‑vocabulary esistente — come Grounding DINO, YOLO‑World o OmDet‑Turbo. Il rivelatore propone diverse possibili posizioni nell’immagine dove ciascun soggetto potrebbe essere, disegnando un riquadro intorno a ogni candidato e inserendo un semplice numero all’interno del riquadro. Il risultato è un “immagine marcata” che mostra tutte le opzioni plausibili. È importante sottolineare che MQADet non riaddestra questi rivelatori; li usa così come sono. Questo rende l’approccio plug‑and‑play: ogni volta che emerge un rivelatore migliore, può essere inserito nella pipeline senza dati o messa a punto aggiuntivi.

Ragionare per arrivare alla corrispondenza migliore
La terza fase, chiamata MLLMs‑Driven Optimal Object Selection, trasforma la scelta finale in una domanda a scelta multipla per il modello linguistico: data la descrizione originale e l’immagine marcata con i riquadri numerati, quale numero corrisponde meglio al testo? Poiché il modello vede sia la formulazione dettagliata sia la disposizione visiva, può valutare indizi fini — pattern, colori, relazioni spaziali come “a sinistra” e interazioni fra oggetti. Gli autori dimostrano che rimuovere questo passaggio di ragionamento riduce drasticamente l’accuratezza, sottolineandone l’importanza. Usando questo design in tre fasi, MQADet ha migliorato l’accuratezza su quattro benchmark impegnativi con frasi naturali lunghe, spesso aumentando le prestazioni dei rivelatori esistenti del 10–40 punti percentuali senza modificare i loro pesi interni.
Cosa significa per la tecnologia di tutti i giorni
Per un non‑specialista, il messaggio chiave è che non è più necessario ricostruire i rivelatori di oggetti da zero per renderli più intelligenti. MQADet agisce come un assistente intelligente sovrapposto ai sistemi attuali, aiutandoli a interpretare descrizioni umane ricche e a scegliere l’oggetto giusto in scene complesse. Questo potrebbe rendere la ricerca visiva, gli strumenti assistivi e le macchine autonome più affidabili quando affrontano il modo naturale di parlare delle persone — ricco di dettagli, sfumature e contesto — aprendo la strada a un’interazione con il mondo visivo più intuitiva e guidata dal linguaggio.
Citazione: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
Parole chiave: rilevamento di oggetti a vocabolario aperto, modelli linguistici multimodali di grandi dimensioni, visual question answering, computer vision, comprensione delle immagini