Clear Sky Science · it
Applicazione del machine learning nella previsione degli esiti del trattamento del cancro del colon
Perché prevedere gli esiti del cancro del colon è importante
Il cancro del colon è uno dei tumori più comuni al mondo, e molti pazienti e famiglie vogliono sapere una cosa semplice e urgente: “Quali sono le mie probabilità e cosa si può fare per migliorarle?” Questo studio dall’Iran esplora come tecniche informatiche moderne, note come machine learning, possano setacciare cartelle cliniche dettagliate per prevedere meglio quali pazienti hanno un rischio maggiore dopo l’intervento chirurgico. Affinando queste previsioni, i medici potrebbero adattare il trattamento e il follow-up in modo più mirato, offrendo ai pazienti più fragili una maggiore possibilità di sopravvivenza a lungo termine.
Trasformare i registri ospedalieri in pattern utili
I ricercatori hanno utilizzato 10 anni di dati su 764 persone sottoposte a intervento per cancro del colon in un centro di rilievo a Shiraz, Iran. Per ogni paziente hanno raccolto 44 informazioni, tra cui età, esami del sangue, dimensione del tumore, stadio del cancro, sintomi e dettagli dell’operazione e dei trattamenti come la chemioterapia. Questi registri sono stati ripuliti e verificati con cura: valori di laboratorio impossibili sono stati corretti, i pazienti non tracciabili sono stati rimossi e le risposte mancanti sono state integrate con stime ragionevoli. Il gruppo ha poi suddiviso i dati in modo che la maggior parte servisse ad addestrare i modelli computazionali, mentre una porzione separata venisse tenuta da parte per testare quanto bene quei modelli riuscissero a prevedere chi sarebbe stato vivo o deceduto al follow-up.
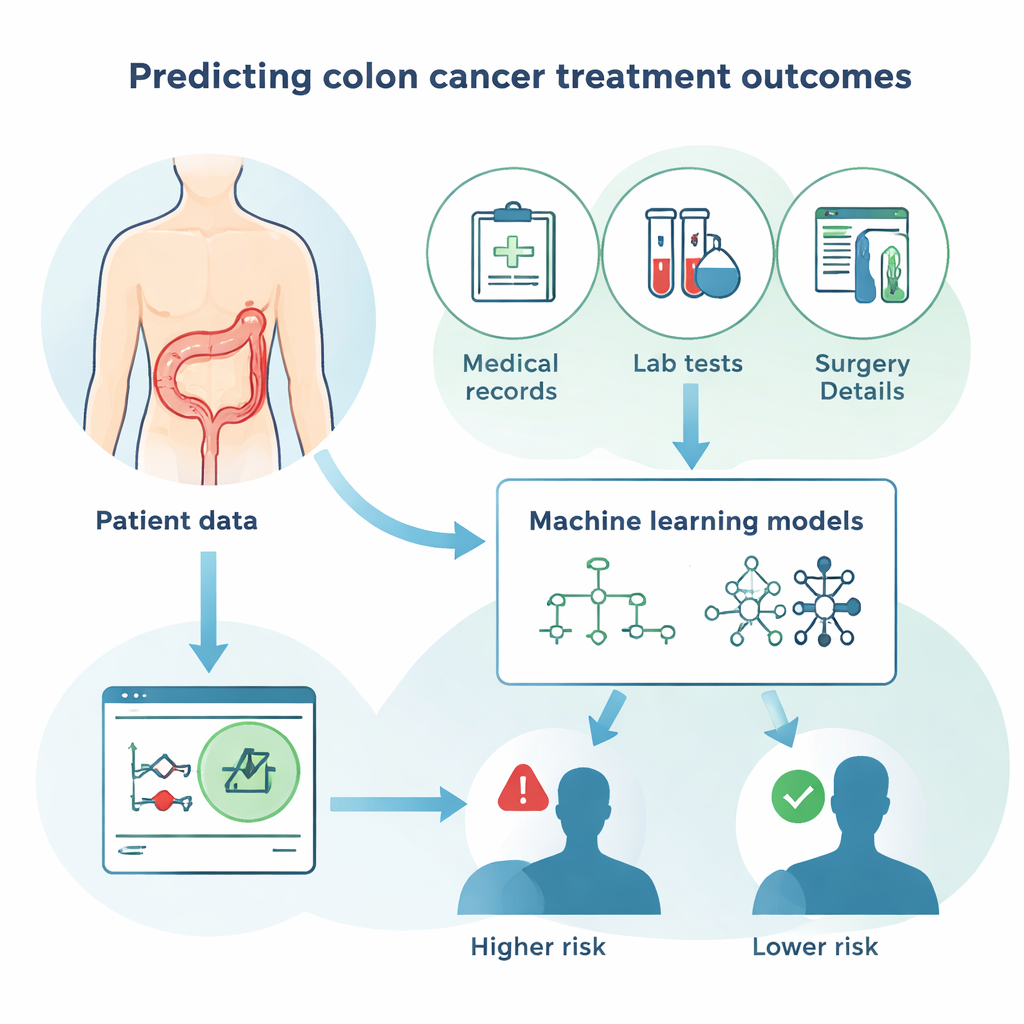
Come gli algoritmi intelligenti apprendono dai pazienti
Invece di affidarsi solo alla statistica tradizionale, lo studio ha confrontato fianco a fianco diversi approcci computazionali moderni. Questi includevano vari metodi a “foresta” e di “boosting”, che combinano molte semplici regole decisionali, oltre alle reti neurali, che ricordano in modo approssimativo come si connettono le cellule cerebrali. L’obiettivo per ogni metodo era lo stesso: usare le informazioni dei pazienti per indovinare se ciascuna persona sarebbe sopravvissuta, e poi confrontare quelle previsioni con quanto è effettivamente accaduto. I modelli sono stati valutati sulla loro accuratezza complessiva, sulla capacità di identificare i pazienti che sono deceduti e sulla capacità di evitare falsi allarmi per chi è sopravvissuto. I metodi migliori hanno raggiunto circa l’80% di accuratezza complessiva, un risultato significativo data la complessità degli esiti in oncologia.
Quali modelli e fattori hanno contato di più
Tra tutti gli approcci, un metodo chiamato CatBoost ha fornito la migliore accuratezza complessiva, mentre un modello random forest ha mostrato il miglior equilibrio tra il segnalare correttamente i pazienti ad alto rischio e non sovrastimare il rischio in chi ha avuto esiti favorevoli. Per rendere i risultati più comprensibili ai clinici, il team ha utilizzato uno strumento di interpretazione che ordina quali informazioni hanno maggiormente influenzato le decisioni del computer. Lo stadio del cancro — un riassunto di quanto è grande il tumore, se ha raggiunto i linfonodi e se si è diffuso — è risultato il fattore singolo più rilevante. Anche la dimensione del tumore, la profondità di invasione della parete colica, la presenza di metastasi a altri organi, il tipo di trattamento, il grado del tumore (quanto le cellule appaiono anomale), il coinvolgimento di vasi linfatici e sanguigni, l’età del paziente e la perdita di peso hanno giocato ruoli importanti nel modellare le previsioni di sopravvivenza.
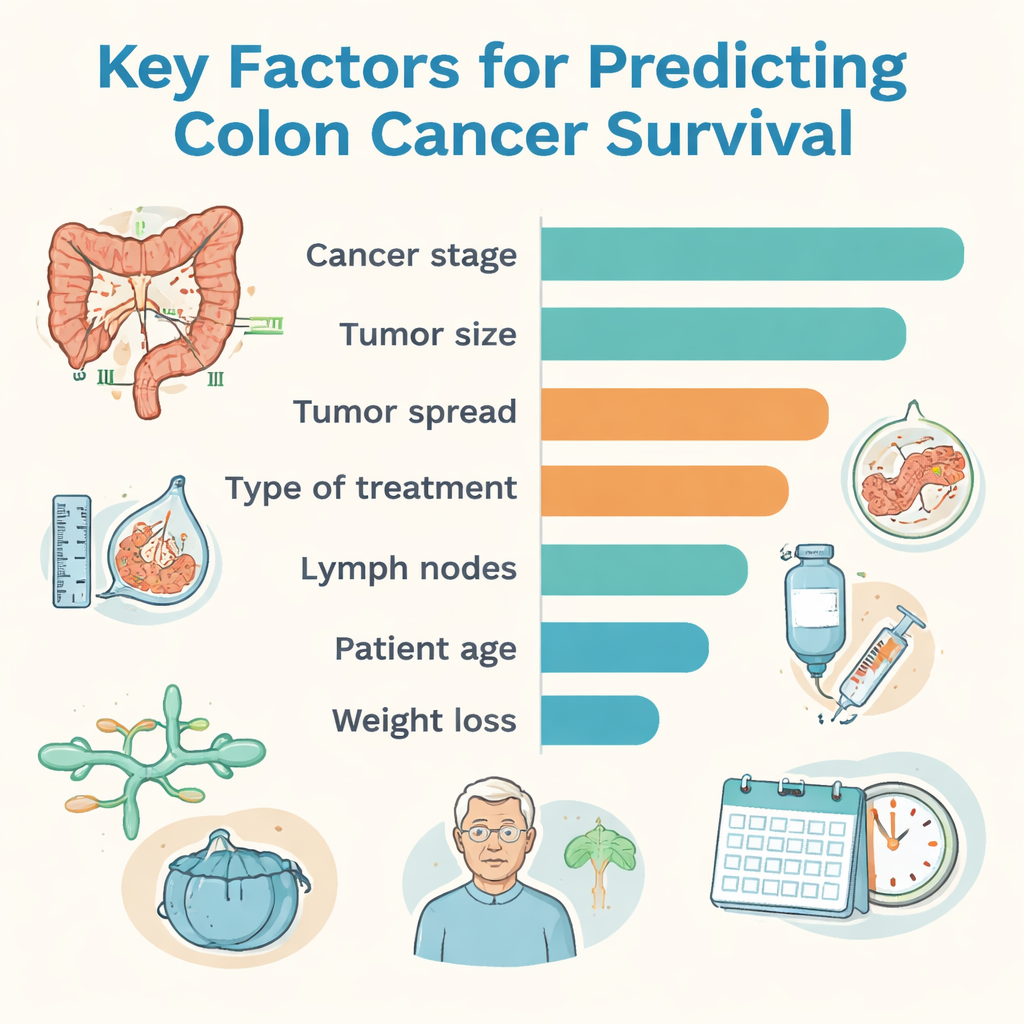
Dai numeri alle decisioni al letto del paziente
Questi risultati suggeriscono che un modello computazionale accuratamente addestrato, alimentato con informazioni cliniche di routine, può aiutare i medici a individuare pazienti che sono silenziosamente ad alto rischio dopo l’intervento per cancro del colon. Nella pratica quotidiana, uno strumento del genere potrebbe essere integrato nella cartella clinica elettronica, combinando istantaneamente dettagli sul tumore e sulla salute generale del paziente in una semplice stima del rischio. Quel numero non sostituirebbe il giudizio del medico, ma potrebbe orientare scelte come la frequenza dei controlli, se trattamenti aggiuntivi valgono gli effetti collaterali o quando è opportuno richiedere un secondo parere. Poiché i fattori più importanti individuati dal computer corrispondono a ciò che gli specialisti oncologi già considerano critico, il sistema è più facile da confidare e spiegare ai pazienti.
Cosa significa per i pazienti e per il futuro
Per pazienti e famiglie, il messaggio chiave è che i computer possono oggi usare dati medici ordinari per supportare una cura più personalizzata per il cancro del colon. Sebbene lo studio sia stato condotto in un unico centro in Iran e necessiti ancora di validazione in altri ospedali e con dati più ricchi, come informazioni genetiche e di imaging, dimostra che il machine learning può evidenziare chi necessita di attenzione aggiuntiva e perché. Col tempo, con l’aggiunta di più dati e il perfezionamento dei modelli, questi strumenti potrebbero aiutare i medici di tutto il mondo a offrire trattamenti non solo basati sull’evidenza, ma anche finemente adattati al cancro e alle circostanze di ciascuna persona.
Citazione: Ghasemi, H., Hosseini, S.V., Rezaianzadeh, A. et al. Machine learning application in colon cancer treatment outcome prediction. Sci Rep 16, 6159 (2026). https://doi.org/10.1038/s41598-026-36917-0
Parole chiave: cancro del colon, machine learning, esiti del trattamento, previsione del rischio, dati clinici